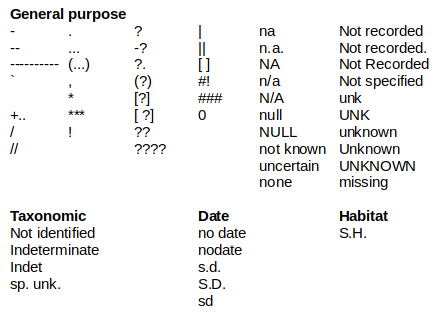
Within fields
tally
Valid entries in the wrong field
Invalid entries
Inappropriate entries
Incorrectly formatted entries
Missing-but-expected entries
NITS
Pseudo-duplication
Truncated entries
Excess space
Incrementing fill-down error
tally
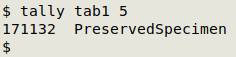
The tally function is a very powerful tool. It returns a sorted list of the entries in a single field, together with the number of times each entry occurs. tally takes filename and field number as its two arguments, and it ignores the header line.
tally() {
tail -n +2 "$1" | cut -f"$2" | sort | uniqc
}
In the screenshot below, tally has found that all 171132 records in "tab1" have "PreservedSpecimen" in the basisOfRecord field (field 5).
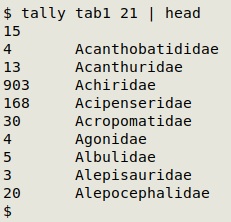
To check another field, just up-arrow to repeat the last command, backspace the field number and enter the number of the next field you want to check. If you expect many different entries from tally, then pipe the output to less. The screenshot below shows the first 10 results of a tally of the family field in "tab1". Notice that the first entry is a blank — in other words, there are 15 records in "tab1" without a family entry.
A great deal of the checking needed in a Darwin Core table can be done by running tally on successive fields, one by one, and scanning the results.
Valid entries in the wrong field
A simple example of this problem is the entry "holotype" in the type field rather than in the typeStatus field, but there are other possible mistakes. Three common errors are:
UTM easting (or northing) in decimalLongitude (or decimalLatitude). Easting/northing data belong in verbatimCoordinates and need to be accompanied by verbatimCoordinateSystem and verbatimSRS.
scientificName entries with code names ("Acacia sp. A14") or unpublished species ("Acacia nova ms"). Only formal taxonomic names should be in scientificName. Code names and informal names of all kinds belong in verbatimIdentification .
A citation of a scientific paper in bibliographicCitation, instead of in (for example) associatedReferences or identificationReferences (see here for an explanation).
In rare cases the software used (such as a spreadsheet) has allowed whole records or parts of records to be shifted "left" or "right", putting many data items in the wrong field. See here for an example.
Invalid entries
This category of error overlaps with "valid entries in the wrong field" and NITS. Simple examples:
"30000" in minimumElevationInMeters and/or maximumElevationInMeters
"2084-06-17" or "1983-00-00" in eventDate
"0" in coordinateUncertaintyInMeters
For some fields, tally is the easiest way to check for invalid entries. When sorting eventDate, for example, impossible past dates ("956-11-03") will appear at the top of the list and impossible future dates at the bottom.
For checking some fields you can sort the entries numerically after using tally. This is a good way to spot impossible decimalLatitude and decimalLongitude entries:
tally [filename] [field number] | sort -t $'\t' -nk2 | less
Regular expressions are also useful when looking for invalid entries. For example, all non-blank entries without authorships in the genus field should begin with an uppercase letter and finish with one or more lowercase letters: ^[A-Z][a-z]+$. Suppose the genus field is field 22. You could look for records that do NOT match that regular expression:
cut -f22 [filename] | awk NF | grep -v "^[A-Z][a-z]+$"
#The "awk NF" removes blank entries
or better
awk -F"\t" '$22 != "" && $22 !~ /^[A-Z][a-z]+$/ {print N FS $22}' [filename]
where "N" is the field number for an identifying field like occurrenceID or catalogNumber.
Inappropriate (overloaded or underloaded) entries
These are best detected with a tally. They are entries that contain information that belongs in another field, or not enough information. Examples:
"F. Smith, Dec 1968" in identifiedBy is overloaded and should be split between "F. Smith" in identifiedBy and "1968-12" in dateIdentified.
"Mount Everest, 1145m" in locality is overloaded and should be split between "Mount Everest" in locality and "1145" in minimumElevationInMeters and maximumElevationInMeters. "Mount Everest, 1145m" could go in verbatimLocality.
In typeStatus, "holotype" is underloaded because it should include the name of the species.
In georeferenceSources, "map" is underloaded because the entry should explain which map.
Incorrectly formatted entries
You can find recommended formats in the Darwin Core term descriptions and examples. Examples:
"27/6/83" in eventDate should be "1983-06-27"
"Frank Garcia, Julia Percy" in recordedBy should be "Frank Garcia | Julia Percy"
Missing-but-expected entries
These show up as blanks in a tally. For example, the country entry might be "Myanmar" but the continent entry is blank instead of "Asia", or decimalLatitude and decimalLongitude are "22.3804" and "97.4072" but the country entry is blank instead of "Myanmar".
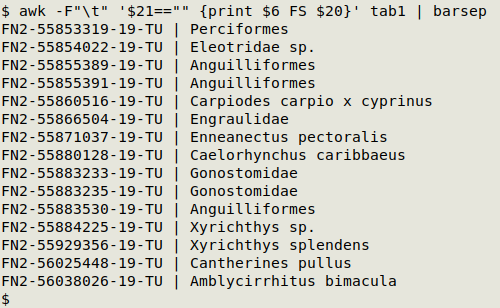
Missing-but-expected entries are best explored with AWK. There are 15 records in "tab1" without a family entry. family is field 21 in "tab1", occurrenceID is field 6 and scientificName is field 20. In the screenshot below, AWK prints the occurrenceID and scientificName of the 15 records in which family is blank. It looks like most of those scientificName entries could be assigned to a family.
NITS
NITS is an acronym for Nothing Interesting To Say. NITS entries are "filler" items that either say nothing or should be explained in another field. Examples:
NITS are unfortunately very common in Darwin Core tables. In all cases they can be deleted (replaced by a blank). If there is information that explains the blank, this information can be put in a ...Remarks field. Examples:
eventDate blank, and eventRemarks has "label says '14 July' but the year is not known"
decimalLatitude and decimalLongitude blank, and
georeferenceRemarks has "locality 'Serendip' in Brazil could not be located in any of our georeference sources"
recordedBy blank, and occurrenceRemarks has "collector’s name unclear on label, could be H. Neisse or A. Meisse"
sex blank, and
organismRemarks has "rear of specimen missing, could be male or female"
Pseudo-duplication
Pseudo-duplicated entries are entries that have the same information expressed or formatted in different ways. These should be "normalised" to a single form of the entry. Examples from a tally:
No. of records identifiedBy
7 Javiera Venegas & Nicolás Cañete
54 Javiera Venegas | Nicolás Cañete
1 Javiera Venegas |Nicolás Cañete
should be normalised to
62 Javiera Venegas | Nicolás Cañete
No. of records | locality
3 | 1.5 km S of Highway 46/Almond Road junction, under bridge
2 | Under bridge, 1.5 km S of junction of Hwy 46 and Almond Road
should be normalised to
5 | Under bridge, 1.5 km S of junction of Highway 46 and Almond Road
Truncated entries
A truncated entry is missing part of its right-hand end. Truncations can be difficult to detect, and they may also be data entry errors.
If you look carefully, you can spot possible truncations when doing a tally on a field. Three command-line methods for detecting truncations are described in the Cookbook, but none of them are guaranteed to find all truncations, and some detections may be "false positives". Please see also this BASHing data post.
Excess space
Excess whitespace can create pseudo-duplicates and can mask duplicate records:
Watch this space
Watch this space
Watch this space
Watch this space
To reduce multiple whitespaces to a single whitespace everywhere in a Darwin Core table, use
tr -s " " < [filename] > newfile
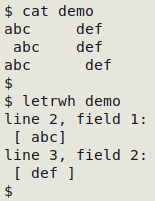
To find leading or trailing whitespace, use the letrwh function:
letrwh()
{
awk -F"\t" '{for (i=1;i<=NF;i++) {if ($i ~ /^[ ]+/ || $i ~ /[ ]+$/) print "line "NR", field "i":\n ["$i"]"}}' "$1"
}
letrwh detects leading or trailing whitespace and prints the line (record) number and the field number, then the data item with enclosing square braces, so the leading or trailing whitespace can be more easily seen, as shown in the screenshot below. Because there may be many errors of this kind, it's best to pipe the output of letrwh to less and page through the results.
The spacevis function makes whitespace clearly visible, as shown in the screenshot below. spacevis is very useful for detecting whitespace in a tally.
spacevis() {
sed 's|\x20|\x1b[103m\xc2\xb7\x1b[0m|g'
}

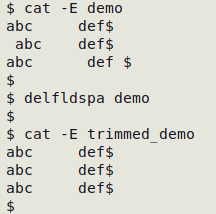
To trim leading and trailing whitespace from entries in a TSV, use the delfldspa function:
delfldspa() {
awk 'BEGIN {FS=OFS="\t"} {for (i=1;i<=NF;i++) gsub(/^[ ]+|[ ]+$/,"",$i); print}' "$1" > "trimmed_$1"
}
delfldspa builds a new TSV, "trimmed_[filename]" with trimmed entries:
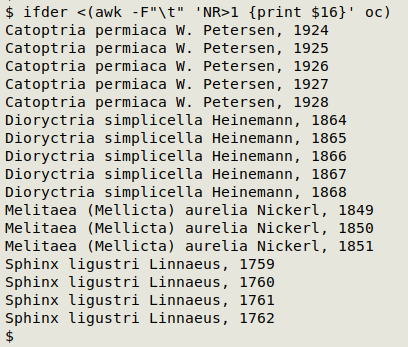
Incrementing fill-down error
These are errors generated by a spreadsheet and can usually be spotted in a tally. Examples:
Linneaus, 1758
Linneaus, 1759
Linneaus, 1760
Linneaus, 1761
Linnaeus, 1762
WGS84
WGS85
WGS86
WGS87
You can find incremental fill-down errors in a single field with the ifder function:
ifder() {
sort -V "$1" | uniq | awk -v FPAT="[0-9]+$" '/[0-9]+$/ {head=substr($0,1,length($0)-length($1)); tail=$1; if (head==hbuf && tail==(tbuf+1)) print hbuf tbuf ORS $0; hbuf=head; tbuf=tail}' | sort -V | uniq
}
Use the function like this:
ifder <(cut -f[field of interest] [filename]) #or
ifder <(awk -F"\t" 'NR>1 {print [field of interest]' [filename])
Here ifder finds errors in the scientificName field (field 16) in "oc":