TSV This marker means that the recipe only works with tab-separated data tables.
Pseudo-duplicates
Pseudo-duplicated data items have the same information content but have minor errors or formatting differences, so that a sort generates multiple results for the "same" item. Pseudo-duplicates are very common in real-world data tables and are easily found with the "tally" function, as in this example:

In another real-world case I found 48 variations on "sea level" in an elevation field:
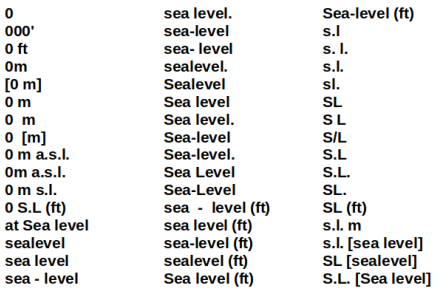
Cleaning up pseudo-duplicates means selecting one of the data items (or a new version) and replacing all the other data items with the selected one. A straightforward way to do this is to copy all the unwanted versions of the data item, uniquified, into a temporary file and build an AWK array with it. The generic command below is for a TSV.
awk 'BEGIN {FS=OFS="\t"} FNR==NR {arr[$0]; next} \
$[field with data items] in arr \
{$[field with data items]="[replacement string]"} 1' \
[temp file listing unwanted versions of data item] table \
> edited_table
See this BASHing data post for an example. The replacement procedure can get fairly tedious if there are many pseudo-duplicates in a table, but there is a GUI version for repeated replacements that uses the generic AWK command above: see this "Extras" page.
Truncation
A "truncated" data item has had its right-hand end trimmed off by software. Truncations can be hard to detect, and they might also be data entry errors. For example, in the data item Melbourne, Vict. 201 did the data-enterer simply leave off the last digit of a year, or did software truncate the string Melbourne, Vict. 2019 (for example) at 20 characters?
When auditing data I often spot truncations while tallying fields. I also use three other methods to find possible truncations:
Item length distribution. Tally item lengths in a particular field, sort them by frequency in reverse order and look for suspicious "bulges". For example, to check field 33 in the TSV "midges":
awk -F"\t" 'NR>1 {a[length($33)]++} END {for (i in a) print i FS a[i]}' midges | sort -nr
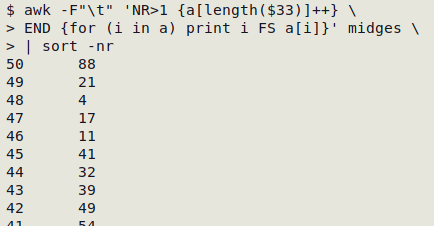
The longest entries have exactly 50 characters, which is suspicious, and there's a bulge of data items at that width, which is even more suspicious. Inspection of those 50-character data items reveals numerous truncations:

Some other tables I've checked this way had bulges at 80, 100, 200 and 255 characters. In each case the bulges contained apparent truncations.
Unmatched braces. This method was explained on the Format 1 page.
Unexpected endings. The third method looks for data items that end in a trailing space or a non-terminal punctuation mark, like a comma or a hyphen. I detect these potential truncations with trailing whitespace and punctuation checks.
Field disagreements
It's possible to check on the command line to see if data items in one field agree with related data items in another field. The hard part is deciding which fields to compare and what kind of possible disagreements should be looked for. You need to be a bit creative in this kind of data auditing, and there are no generally applicable recipes. Some of the checks I've done in my auditing work are:
- "Total" data item is sum of added-up data items?
- Verbatim date (any format) is correctly processed to ISO 8601 date?
- Starting date is before finishing date?
- Minimum depth/elevation is less than maximum depth/elevation?
- "Decomposed" date is the same as full date?
- "Decomposed" scientific name is the same as full name?
- Date of collecting a sample is before the date of identifying/processing the sample?
- Day number agrees with ISO 8601 date?
- Named locality is in agreement with locality as coordinates? (Geochecking)
In all these cases it was important to exclude records in which both of the data items being compared were blank, because empty strings always agree!
An efficient way to find many kinds of field disagreements is to do a "one2many" check on the two fields of interest.
Missing but expected
This check parallels the checks for field disagreements. It looks for records in which related, non-blank data items that are usually present in a data table have one or the other data item missing. The "fldpair", "fldtriplet" and "one2many" functions are all useful for finding missing-but-expected blanks.
In "occ1", below, countryCode has been included with some records and is missing-but-expected in others:

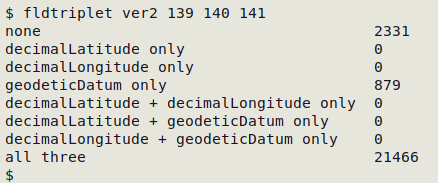
The "ver2" table (below) has geodeticDatum entries without corresponding latitude/longitude entries, which makes no sense. Either latitude and longitude are missing-but-expected, or geodetic datum was entered by mistake in 879 records:
Geochecking
"Geochecking" here means calculating the difference between a location's latitude/longitude (lat/lon) as provided in the data table, and as listed for that location in an independent reference such as a gazetteer. If the difference is large, there's a problem.
In the example TSV "geo" (see screenshot below), the "LatData" and "LonData" figures are the ones given in the data table, and the "LatRef" and "LonRef" figures are reference ones I found for the verbal descriptions of the sites in the data table (not shown). For each record I calculate the Euclidean distance between the data and reference lat/lons; this distance is added to the record in the "Diff" field. The Euclidean distance isn't as accurate as the great circle distance between the points, but it's good enough if the points are fairly close together, and in any case I'm looking for unusually big distances between provided and reference lat/lons.
How big is "big"? It depends in part in how accurate the lat/lons are claimed to be. In the "geo" table, it looks like the lat/lons were converted from degrees-minutes-seconds format to the nearest 1 minute. For example, 145.0833 is 145°05' E, and -42.7167 is 42°43' S. Since 1 minute is roughly 1.9 km in latitude, my arbitrary threshold for "bigness" in distance will be 2 km. If the distance between data and reference lat/lons is 2 km or greater, something may be wrong.
The Euclidean distance calculation is explained in this BASHing data post.
awk -F"\t" 'BEGIN {pi=3.14159} NR==1 {print $0 FS "Diff"} NR>1 {printf("%s\t%.1f\n",$0,sqrt((($4-$2)*111.32)^2 + (($5-$3)*111.32*cos($4*(pi/180)))^2))}' geo
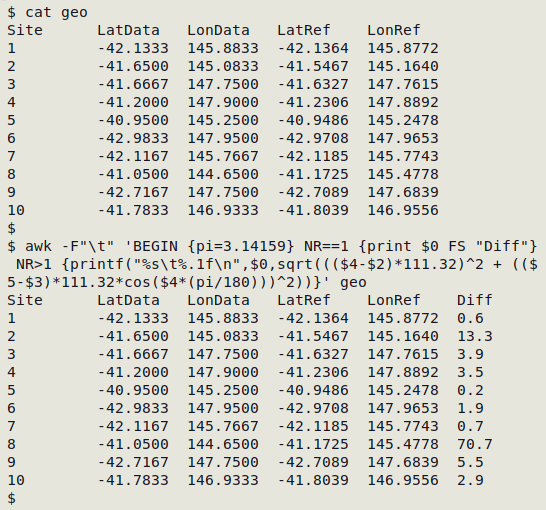
There could be problems with the lat/lons for sites 2, 3,4, 8, 9 and 10, especially sites 2 and 8!
Domain schizophrenia
Data quality guru Arthur Chapman says domain schizophrenia occurs in a database when fields are used for purposes for which they weren’t designed and which end up including data of more than one nature. Chapman gives the example of a "Species" field with items not appropriate for that field:
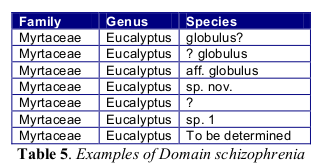
I often find domain schizophrenia when tallying fields. For example, in a certain Australian biodiversity database the "locality" field has entries like "Gympie" and "15 km S of Griffith". These verbal locations are useful when checking the accompanying latitude/longitude data. But one of the data items in "locality" is:
In a 4m high heathland spp. not sure what it is. It has a weeping habit and tiny flat leaves. Every second year or so it flowers spectaularly - looks like a white waterfall. The beetles completely covered it and stayed for about two days (after which the little flowers were worse for wear. We called these bettles pumpkin beetles when we were kids because of their appearance.
I don't think data cleaners should attempt to fix domain schizophrenia. If you find it, you could recommend to the data manager or compiler that the field be split. In Chapman's example above, the "Species" entries for those records could be moved to a "Species_comment" field and the "Species" field left blank.