TSV This marker means that the recipe only works with tab-separated data tables.
Single-record viewing
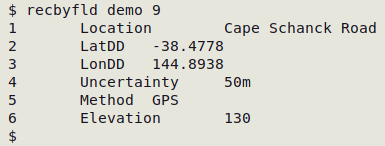
The "recbyfld" function takes table name and record (line) number as its two arguments.
List a record's data items by numbered field TSV
recbyfld () { paste <(head -n1 "$1" | tr '\t' '\n') <(sed -n "$2p" "$1"| tr '\t' '\n') | nl -w1; }
Single-record paging (YAD)
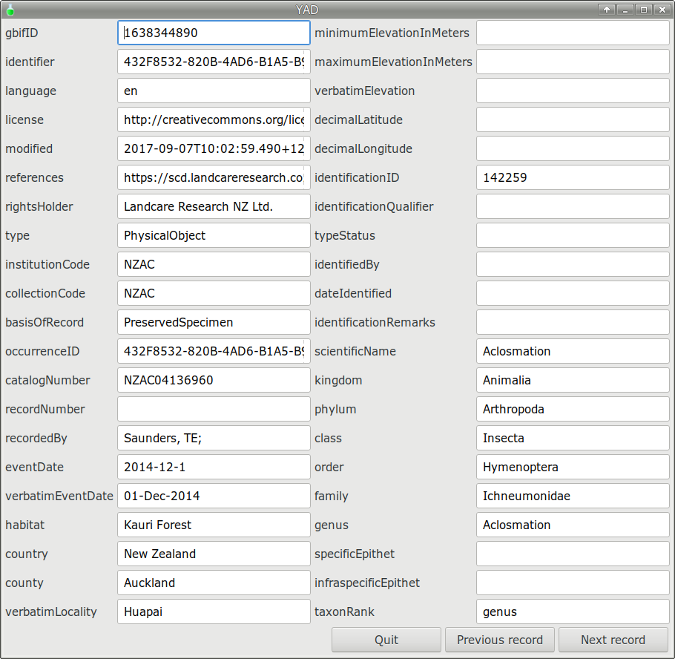
The "yadrex" script uses the YAD dialog creator and is a much neater way to display the contents of a single record. It can also page records forward and back, one at a time. The script takes three arguments: table name, record (line) number and number of columns for display.
Note: The script shown here is an improved version of the one described in this BASHing data post. YAD will delete any underscores (_) in field names.
Page through individual records, neatly displayed in a GUI dialog TSV
#!/bin/bash
mapfile -t < <(head -1 "$1" | tr '\t' '\n' | sed 's/^/--field=/')
nr="$2"
while true; do
awk -v goto="$nr" 'NR==goto' "$1" | tr '\t' '\n' \
| while read line; do echo "$line"; done \
| yad --center --columns="$3" --form "${MAPFILE[@]}" \
--button="Quit":1 --button="Previous record":2 --button="Next record":0 > /dev/null
case $? in
1) exit 0;;
2) nr=$(($nr-1)) && continue;;
0) nr=$(($nr+1)) && continue;;
252) exit 0;;
esac
done
exit 0
The (reduced) screenshot below shows record 26 in table "demo", displayed with 2 columns (command yadrex demo 26 2) :
Bulk replacements (YAD)
Another handy script if you have YAD available. The "brgy" script (bulk replacement in a gui with yad) allows you to repeatedly replace pseudo-replicate entries in a data table with a single "correct" version. The script builds a new table after each replacement with the same name as the starting table; the previous version of the table is saved with a time stamp in its filename. For instructions and a demonstration, see this BASHing data post.
Bulk-replace pseudo-replicates TSV
(See instructions here)
#!/bin/bash
while true; do
choice=$(yad --geometry=400x600+1450+100 --title="" --align=center \
--button="Quit":1 --button="Replace":0 \
--form \
--field="Items to be replaced:":TXT \
--field="Replace with:" \
--field="In field number..." \
"" "" "")
case $? in
1) exit 0;;
0) cp "$1" "$1".$(date +"%Y-%m-%d_%T") && \
awk -v REPL="$(echo "$choice" | cut -d"|" -f2)" \
-v FLD="$(echo "$choice" | cut -d"|" -f3)" \
'BEGIN {FS=OFS="\t"} FNR==NR {a[$0]; next} \
$FLD in a {$FLD=REPL} 1' \
<(echo -e "$choice" | cut -d"|" -f1 | cut -f2) "$1" > temp && \
mv temp "$1" && \
continue;;
252) exit 0;;
esac
done
exit 0
Field-aware search
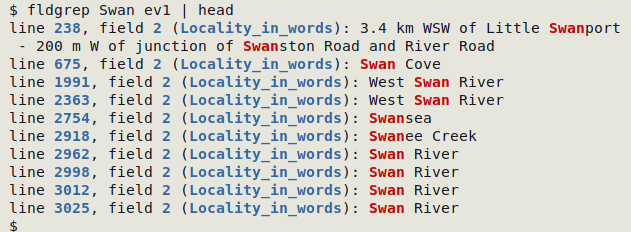
The "fldgrep" function searches for an exact string in a TSV and returns the string's line and field location (field number and field name), plus the field containing the string with the string highlighted.
Field-aware search for exact string TSV
fldgrep() { awk -F"\t" -v target="$1" -v blue="\x1b[1;34m" -v red="\x1b[1;31m" -v reset="\x1b[0m" 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i} NR>1 {for (j=1;j<=NF;j++) if ($j ~ target) {n=split($j,m,target,sep); printf("%s","line " blue NR reset ", field " blue j reset " (" blue a[j] reset "): "); for (k=1;k<=n;k++) printf("%s", m[k] red sep[k] reset); print ""}}' "$2"; }
More information here.