|
On this page:
|
On the Structure 2 page:
|
TSV This marker means that the recipe only works with tab-separated data tables.
Fields per record
In a table with N fields, every record should have exactly N fields. A record with more or fewer than N fields is broken and needs fixing before any further data auditing or cleaning is done.
Tally the number of fields per record TSV
(The "broken" function takes table as its one argument. The optional sed command after uniq -c converts the numbering to tab-separated.)
broken() { awk -F"\t" '{print NF}' "$1" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/' | sort -nr; }
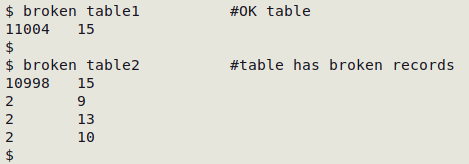
Interactive script to tally the number of fields per record
and identify anomalous records TSV
(I call this script "fldnos" — see screenshot)
#!/bin/bash
blue="\033[1;34m"
reset="\033[0m"
var1=$(awk -F"\t" '{print NF}' "$1" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/' | sort -nr)
var2=$(echo "$var1" | wc -l)
if [ "$var2" -eq "1" ]; then
printf "All $blue$(echo "$var1" | cut -f1)$reset records in $blue$1$reset have $blue$(echo "$var1" | cut -f2)$reset fields\n"
else
printf "$blue$1$reset has:\n"
echo "$var1" | awk -F"\t" -v BLUE="$blue" -v RESET="$reset" '{print BLUE $1 RESET" records with "BLUE $2 RESET" fields"}'
echo
read -p "Show line numbers with wrong field totals? (y/n)" var3
case "$var3" in
n) exit 0;;
y) echo "$var1" | sort -nr | tail -n +2 | cut -f2> /tmp/wrongs
awk -F"\t" -v BLUE="$blue" -v RESET="$reset" 'FNR==NR {arr[$0]; next} (NF in arr) {print "line "BLUE FNR RESET": "BLUE NF RESET" fields"}' /tmp/wrongs "$1"
rm /tmp/wrongs;;
esac
fi
exit 0
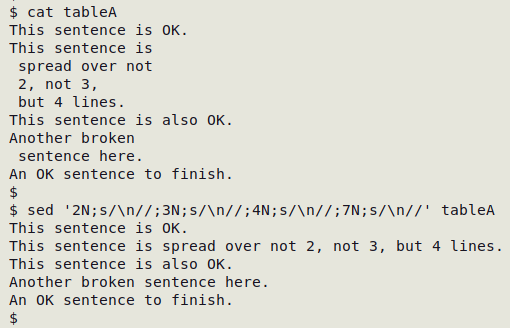
Embedded newlines
Broken records must be repaired before any further auditing or cleaning is done on a data table. A few breaks in a small table can be repaired in a text editor. Breaks in larger tables can be fixed on the command line with sed or AWK.
The most common causes of broken records are newline characters embedded within data items. Multi-line data items are allowed in spreadsheets, and when a spreadsheet with multi-line items is copy/pasted into a text file, each line takes up one field in the record.
Prevention is better than cure, and I strongly recommend that newlines within spreadsheet cells are removed while the data items are still in the spreadsheet. I do this with Microsoft Excel files by opening the spreadsheet (worksheet) in Gnumeric and doing a global replacement of "\n" with a comma or space.
Command-line repair methods depend on the nature of the record breaks. The simplest case is that there are only a few broken records, and the records are "simply" broken: whatever was in the data item has been split over two or more lines. The fix is to specify the line (record) number of each of the pre-break lines and then just delete the newline character that caused the break. "tableA" has five records, two of which are simply broken:
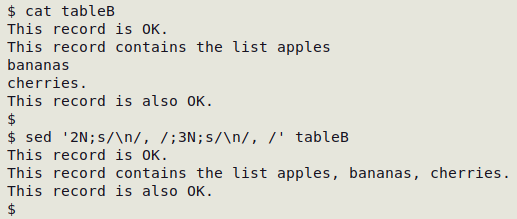
The repair is a little more difficult if the records aren't simply broken, for example if the newline-separated items made up a list, as in "tableB" in the next screenshot. In this case the newlines should be replaced with a suitable separator, such as a comma and a space:
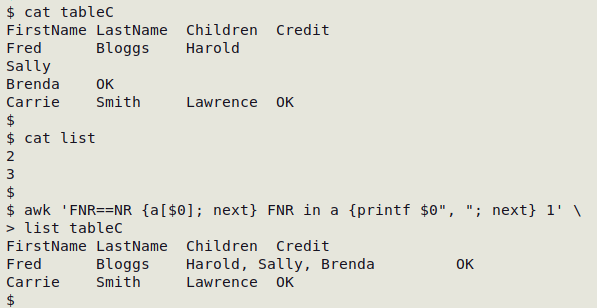
When there are many broken records, it's easiest to put the line (record) numbers of the pre-break lines in a temporary file, then store those numbers in an AWK array and do the repair with AWK:
For more information on fixing broken records, see the BASHing data posts here (2018), here (2019) and here (2020). To be honest, most of the data tables I see don't have many (or any) broken records and I do repairs in a text editor, not on the command line.
Broken CSVs
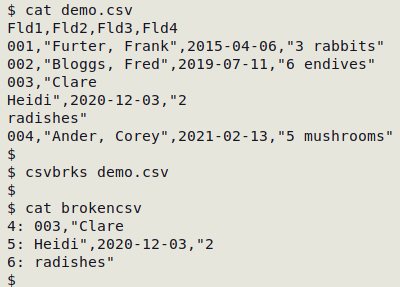
CSVs sometimes have broken records caused by embedded newlines or carriage returns within data items. When the CSV is converted to a TSV for checking, the "fldnos" script (above) will list the lines with too few fields, but it can be helpful to have the broken lines and their line numbers in a separate text file. This operation can be done on the original CSV with the following "csvbrks" function, which takes the original CSV as its one argument and builds "brokencsv". The function relies on the csvformat -T command from the "csvkit" package of Linux utilities.
Function to select broken records and their line numbers from a CSV
csvbrks() { awk 'FNR==NR {a[$0]; next} FNR in a {print FNR": "$0}' <(awk -F"\t" 'NR==1 {c=NF} NR>1 && NF != c {print NR}' <(csvformat -T < "$1")) "$1" > brokencsv; }