
For a full list of BASHing data blog posts, see the index page. ![]()
Embedded newlines
If you work with plain-text data that has just one record per line of text, you're sooner or later going to meet a set of records suffering from "embedded newline disease".
Most of the records are OK, but some individual records extend across several consecutive lines. This might have been caused by a processing glitch at some time in the past. More often, the data have come from an application that allows more than one line per record. Spreadsheets do this and no, Microsoft Excel isn't the only offender. You can also enter multiple lines in LibreOffice Calc: just press Ctrl + Enter at the end of a line within a cell:
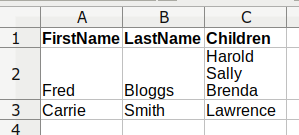
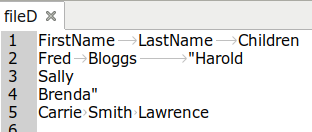
Copied into or exported as text, that one line of cells now occupies 3 lines:
Good ways to find broken records are explained here in A Data Cleaner's Cookbook. A few breaks in a small file can be repaired in a text editor. Larger files are best fixed on the command line, and in the Cookbook I recommend sed with its "N" option. In this post I expand on that solution and suggest an AWK alternative.
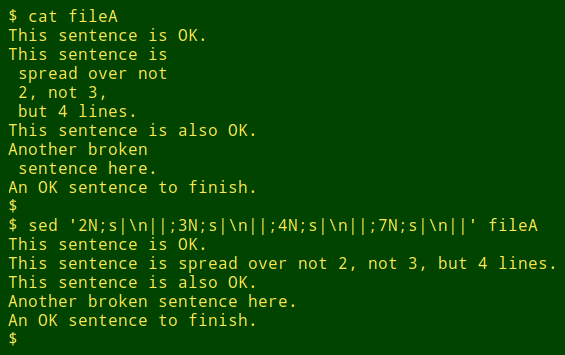
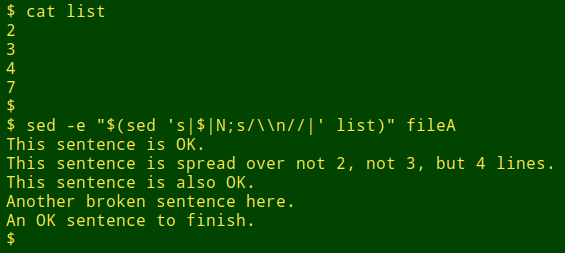
The first demonstration file, "fileA", has 5 records split over 9 lines. The records are "simply split": if you rejoin the pieces of a split record as-is, you get a perfect record. Using sed and "N", you can do the repair by specifying the line number of each of the pre-break lines and then deleting the newline character that caused the break:
sed '2N;s|\n||;3N;s|\n||;4N;7N;s|\n||' file
(fileA):
This sentence is OK.
This sentence is
spread over not
2, not 3,
but 4 lines.
This sentence is also OK.
Another broken
sentence here.
An OK sentence to finish.
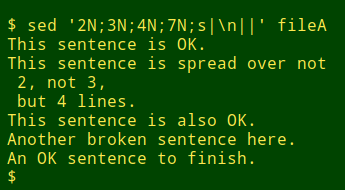
You can "gang" the address+"N" commands, but that only applies if the repairs are on non-consecutive lines. It won't work if there are consecutive lines to be stitched together:
Furthermore, typing all the addresses and newline deletions could get pretty tedious if there are a lot of embedded newlines in the file to be repaired. An easier approach is to create a new file (here called "list") listing each of the relevant line numbers. Next, build a sed command which appends an "N" and a newline deletion to each line of that list of line numbers, and feed the result of that command to sed with its "-e" option. (Note the change of sed separators and the backslash escape before the newline character.)
sed -e "$(sed 's|$|N;s/\\n//|' list)" file
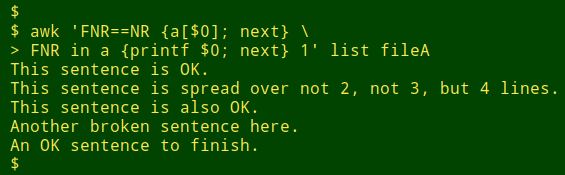
AWK can also do this, a bit more simply. Store the line numbers from "list" in an array. Print all lines, but if the current line number in "fileA" (FNR, not NR) is in that array, use printf to print the record fragment without a newline, before moving with next to the next line:
awk 'FNR==NR {a[$0]; next} \
FNR in a {printf $0; next} 1' list file
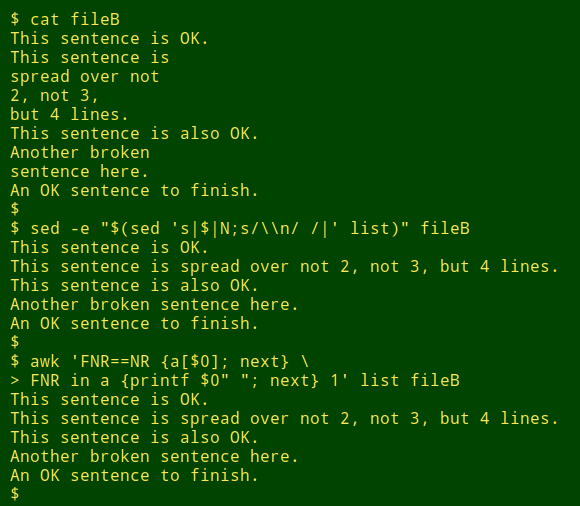
If the records haven't been simply split, you have to replace the embedded newline with an appropriate character. Here I'm adding a single space with AWK and sed to repair "fileB", which is "fileA" with the leading whitespaces trimmed away:
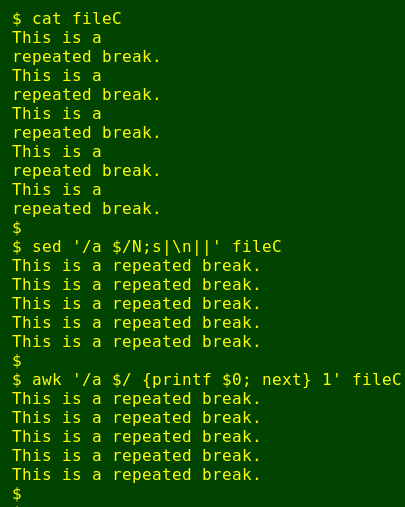
Now for a special case. If a record with "embedded newline disease" is repeated, it's easier to search for the pattern at the end of the break than to list all the relevant line numbers. Here the searched-for pattern is "a " (letter "a" + whitespace) at the end of a line:
sed '/a $/N;s|\n||' file
(or) awk '/a $/ {printf $0; next} 1' file
(fileC):
This is a
repeated break.
This is a
repeated break.
This is a
repeated break.
This is a
repeated break.
This is a
repeated break.
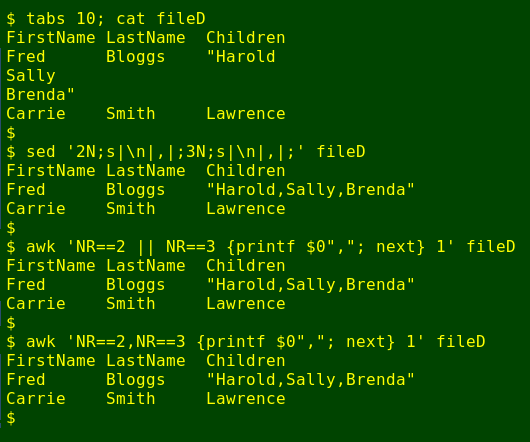
And that spreadsheet import?
sed '2N;s|\n|,|;3N;s|\n|,|;' fileD
(or) awk 'NR==2 || NR==3 {printf $0","; next} 1' fileD
(or) awk 'NR==2,NR==3 {printf $0","; next} 1' fileD
For another example of "embedded newline disease", see this blog post.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License