
For a full list of BASHing data blog posts, see the index page. ![]()
Curse of the CSV monster
CSV stands for "comma-separated values" and as a tabular data format it's been around for more than 40 years. Nevertheless, CSV doesn't always mean comma-separated. There are plenty of ".csv" files out there that use the tab character, a colon or a semicolon as a field separator instead of a comma.
That isn't the biggest problem with CSVs, however. Imagine you were designing a new digital format for text data in tables, and you needed a character to tell a text-parser that one data field had ended and another was about to start. Would you choose the second most commonly used punctuation character for this job? Wouldn't you realise how likely it is that your field-separating character would also occur within a data field?
Well, what's done is done. So as not to confuse the CSV parser, you put double quotes around any data field containing an embedded comma. Other CSV-producers might also put double quotes around every field containing white space, and still others put double quotes around every field, just to be safe.
Of course, all this double-quoting means that double quotes within fields should also be double-quoted, to avoid being mistaken for "escape" double quotes. And so we arrive at the godawful mess called the CSV format, in which any of the following versions might be found for the same 5-field record:
"Smith, Andrew",0417 563 294,""The Croft"",Middleboro,Vic
"Smith, Andrew","0417 563 294",""The Croft"",Middleboro,Vic
"Smith, Andrew","0417 563 294",""The Croft"","Middleboro","Vic"
In A Data Cleaner's Cookbook I give four reasons why I prefer tab-separated value (TSV) format to CSV.
| Smith, Andrew | 0417 563 294 | "The Croft" | Middleboro | Vic |
See the Cookbook for details, but in a nutshell: you avoid comma-escaping hassles, you can display fields neatly in a text editor or terminal, you can move data between text file and spreadsheet easily, and you don't have to specify a field separator for command-line tools like cut and paste. There are various ways to convert CSVs to TSVs on the command line, depending on how the CSV is built. Sometimes, however, there are complications, as in the example below.
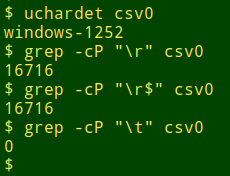
The CSV table I was working with had a header line, 16715 uniquely numbered records and 25 fields. I'll call this file "csv0". The file was windows-1252 encoded and grep found one line-ending Windows carriage return for each record, and no tab characters:
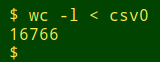
Alas, "csv0" also had lots of broken records caused by embedded newlines:
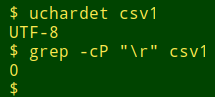
I changed the encoding of "csv0" from windows-1252 to UTF-8 with iconv, then deleted all the Windows carriage returns with tr -d '\r'. The resulting CSV was named "csv1".
Needless to say, command-line CSV programs don't automatically repair broken records while converting "csv1" to TSV. Here are three of the command-line CSV converters at work: csvquote, csvtool and csvformat from csvkit.

The function "broken" used below comes from the Cookbook and simply tallies up the number of tab-separated fields in each line of a file:
broken() { awk -F"\t" '{print NF}' "$1" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/' | sort -nr; }
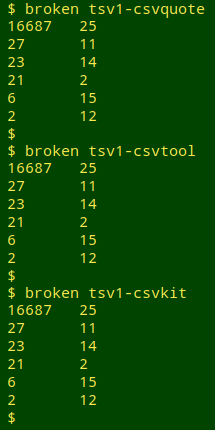
Inspection of the line numbers for the broken records, now in TSV format, showed three patterns: two records split into 14 and 12 fields, six records with a 15/11 split and 21 records with a 14/2/11 split:
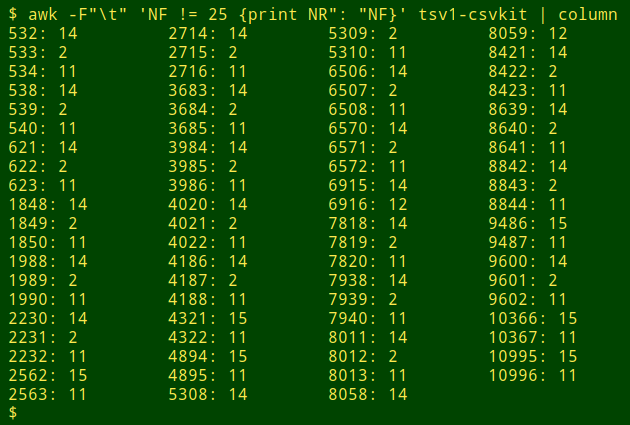
These all seemed to be simple splits, with no added characters before or after the unwanted line break. For example, here in "csv1" are the three lines from the first of the 14/2/11 splits, double-spaced for clarity:
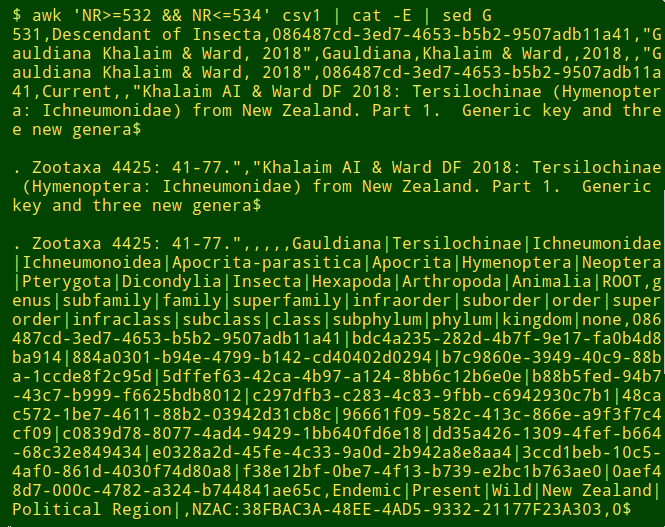
While the broken records could be repaired on the command line after converting "csv1" to TSV, I decided to fix the broken records before conversion with the help of a GUI program. (I wouldn't torture a GUI program with a huge file this way, but 16716 lines isn't huge.)
The GUI program was Gnumeric spreadsheet and I used the import/copy/paste trick to make it into a TSV. Before copying, though, I deleted all newline characters with Gnumeric's "Search and Replace" function (Ctrl+h). Gnumeric does the deletion only within records, leaving the newlines at the ends of records untouched. The resulting TSV text file had no broken records and the repairs had been neatly done (see below).
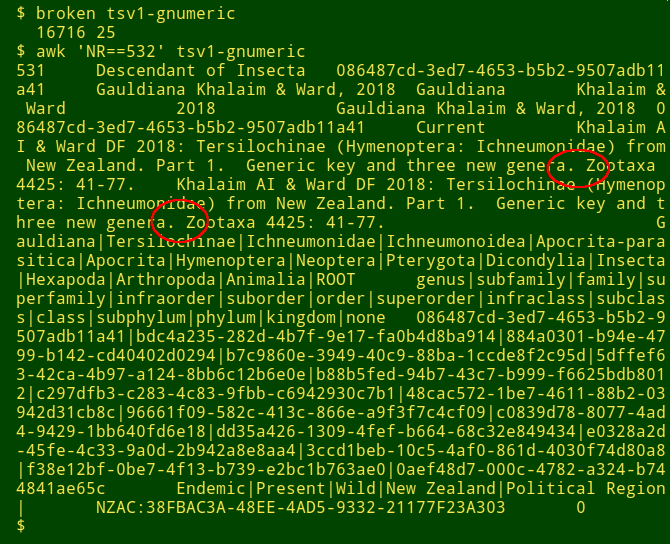
Getting back to those three "Andrew Smith" address versions I showed at the start of this post, I tried converting them with the command-line tools used above. As shown in the next screenshot the results were mostly unhappy. The successful "c2t" function is from the Cookbook.
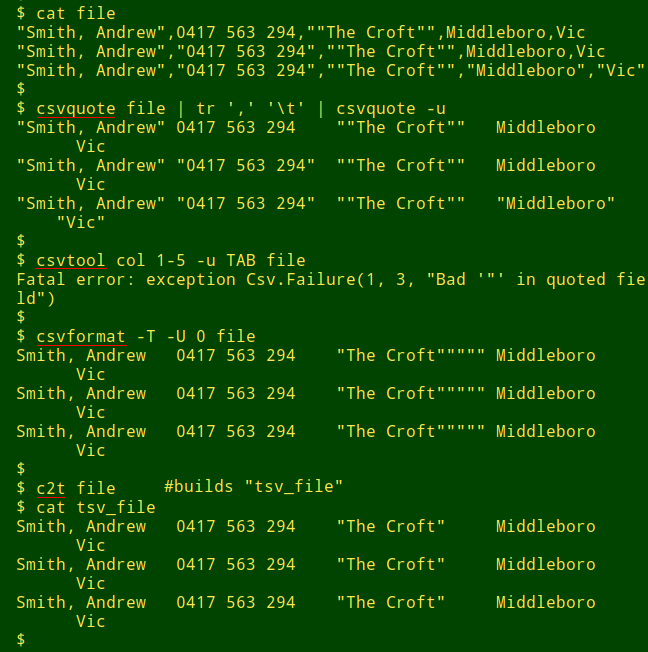
Shaun Pankau points out that Perl has some dedicated CSV-wrangling code in Text::CSV, and that most Linux distros come with Perl. He suggests the following function:
csv2tsv() { file=$1; name=${file%.*}; perl -E 'use Text::CSV; \
my $csv = Text::CSV->new ({ binary => 1 }); \
open my $io, "<&STDIN" or die "$file: $!"; while (my $row = $csv->getline ($io)) \
{ say join "\t", @$row; }' <$file >${name}.tsv; }
CSV is OK on the command line for data files where no data item contains a comma, no escape-quoting is needed for correct parsing, there are no broken records and the locale doesn't use a comma instead of a period as a decimal separator. The datasets I audit aren't often like that. I dread getting data in CSV format because it usually means extra and often fiddly work. See here and here for similar opinions. A quote from the first source:
The problem here is two-fold: (1) the CSV format is just kind of awful and (2) many end-users complain when CSV parsers don’t “successfully” interpret the mis-formatted files they want to parse. To borrow language from the web, essentially all CSV parsers have been compelled to operate in quirks mode all the time...
I think it’s worth documenting just how little work would be required to replace CSV files with a format that’s far easier for machines to parse while only being slightly harder for humans to write. When I think about the trade-off between human and machine needs in computing, the CSV format is my canonical example of something that ignored the machine needs so systematically that it became hard for humans to use without labor-intensive manual data validation.
Please don't use CSV. I and many other command-line data-wranglers will be grateful.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License