
For a full list of BASHing data blog posts see the index page. ![]()
Embedded newlines without a clue
There are command-line recipes in A Data Cleaner's Cookbook and in this blog for finding and fixing tables with embedded newlines, but those recipes are really only for simple cases. To tell the truth, in most of my data work the cure for Embedded Newline Disease is just a few quick edits in Geany text editor.
However, I sometimes see tables that aren't simple: several fields in each record have embedded newlines and there's no special marker for "end-of-record". Worse yet, the program that allowed embedded newlines in data items (for example, a spreadsheet) didn't escape the embedded newline characters when exporting as text, or didn't double-quote all the data items so I can tell where a data item begins and ends. Instead I'm faced with this:
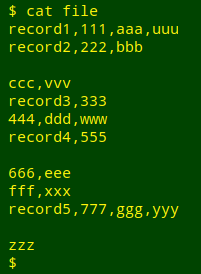
record1,111,aaa,uuu
record2,222,bbb
ccc,vvv
record3,333
444,ddd,www
record4,555
666,eee
fff,xxx
record5,777,ggg,yyy
zzz
from this original:
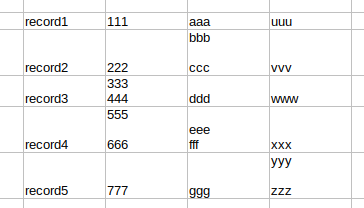
How to repair this file to put each record on a single line? It's do-able with basic GNU tools if there's a constant element in the first or last field that's not present in any other field. In the demo file, that constant element is "record" in field 1.
The first step is to put the whole file on one line with paste, using a paste delimiter not present in the table. Here I'll use a pipe as delimiter:

Next, I'll use sed to replace all those "|record" strings with a newline followed by "record", and the table is repaired:
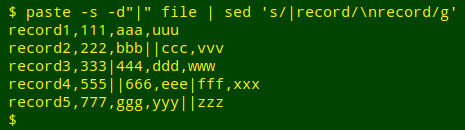
In this demo the pipes indicate newlines within data items. Some other character(s) could replace those pipes if needed.
A similar process would fix broken records where the last field ends with an ISO 8601 date:
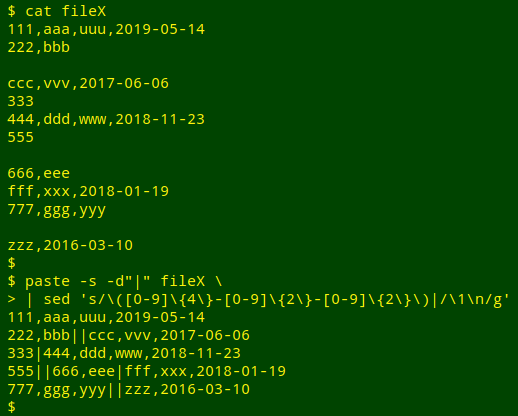
Because human brains are used to processing text in blocks that are long in the up-down direction, the idea of putting an entire file on a single line seems a little awkward. But a computer doesn't see blocks of text as long and narrow. Newlines are just single characters among the letters, numbers and punctuation in a line of bytes.
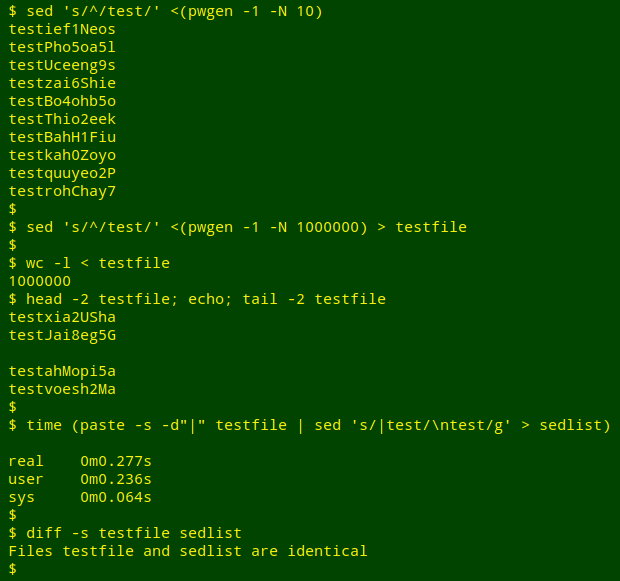
To get some idea of how fast the "single line" repair job takes, I built a 1,000,000-line test file by prefixing the string "test" on 1,000,000 lines of pwgen output. I used the paste/sed sequence to put all 1,000,000 lines on one line, then split the single line back into its 1,000,000 constituent lines. That took about a quarter of a second on my desktop, which has a quad-core i5 CPU and 8GB of RAM:
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License