Is the table in UTF-8?
If you haven't had much experience with character encoding and its problems, please read up on the subject before looking at this section of the cookbook. I warmly recommend What every programmer absolutely, positively needs to know about encodings and character sets to work with text, a blog post by developer David C. Zentgraf.
It could be that the data table you're working with contains only the basic Latin-alphabet numbers, letters and punctuation marks from the ASCII scheme. In that case, it doesn't much matter what the data table's encoding is, because encodings that can code for many more characters, like UTF-8, already contain the ASCII basics as a subset.
You may, however, be checking or cleaning a data table with characters not found in the ASCII set. To work with such a table, it's best if the table's encoding is UTF-8, and your data cleaning should be done on a system with a UTF-8 locale. If the data table is ever to be shared between data users, UTF-8 is the safest encoding choice.
Two command-line utilities that can reliably identify UTF-8 encoding are isutf8 (from the GNU "moreutils" package) and file. I like file because it also looks at line endings.
Check file encoding
file table

table1 may not have character encoding problems, but the CRLF line endings should be changed to LF before any further data checking is done.
table2 is ready for data checking.
table3 should be converted to UTF-8 and have its line endings changed before any further data checking is done.
Converting to UTF-8
The best all-purpose conversion tool I know is iconv. You should specify both the existing encoding (-f) and the target encoding, UTF-8 (-t utf-8).
Convert a data table from [another encoding] to UTF-8
iconv -f [another encoding] -t utf-8 < table > new_table
For a list of all the available "from" encodings, enter iconv -l. Unfortunately it can sometimes be hard to determine what the "from" encoding might be. For example, the euro sign, €, has no encoding in the old but still widely used encoding ISO 8859-1. In ISO 8859-15, € is encoded with the hexadecimal value a4. file might say the encoding is ISO-8859, but which ISO-8859?
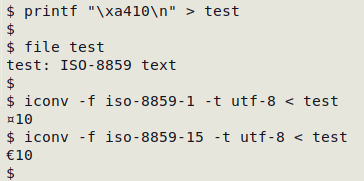
Another iconv issue is that it stops converting when it finds an "illegal input sequence at position [some number]". It might be that the data table's encoding is corrupted, but a more likely explanation is that the "from" encoding being used is incorrect.
If you get the "illegal input sequence" message, you can try other likely "from" encodings. A more general workaround is to find the "illegal input sequence" in the last line of the partly-converted table being built by iconv. The (missing) character after the last one on the line must be the "illegal" one. It can be replaced with another character once its byte sequence is found in the original table. For details of this method see this BASHing data blog post.
Note also that if file reports that the encoding is ASCII, it's not necessary to convert the data table to UTF-8. The entire ASCII character set is a subset of Unicode, on which UTF-8 is based.
Tally visible characters
The script below (I call it "graph") generates a columnated tally of all the non-gremlin characters and their hexadecimal values in UTF-8 encoding. It finds its characters using the POSIX character class graph. The invisible characters "no-break space" (NBSP), "soft hyphen" (SHY) and a few oddities like byte order marks are also included in the listing if they're present in the data table. Because the tallying can take a while (the data tables I audit can contain tens of millions of characters), I've added a progress bar with the pv utility.
I run the "graph" script on most data tables because it can show combining characters, multiple versions of the same character and unmatched braces indicating possible truncations, as well as indicators of encoding conversion failure.
A script to tally visible characters and their hex values
#!/bin/bash
pv -w 50 -pbt "$1" \
| awk 'BEGIN {FS=""} {for (i=1;i<=NF;i++) if ($i ~ /[[:graph:]]/) {arr[$i]++}} END {for (j in arr) printf("%s\t%s\n",arr[j],j)}' \
| sort -t $'\t' -k2 \
| while read -r line; do printf "%s\t%s" "$line"; cut -f2 <<<"$line" | hexdump -e '/1 "%02x" " "' | sed 's/ 0a //'; echo; done \
| column
exit
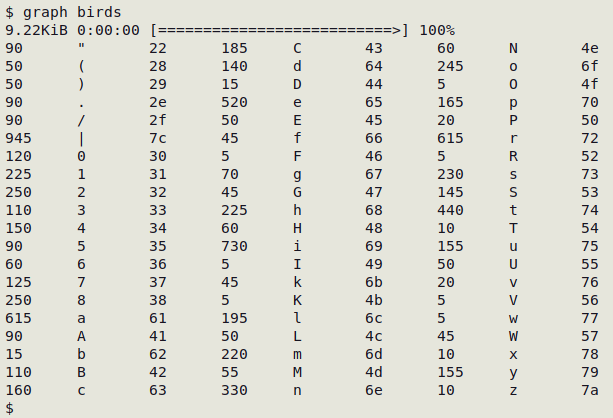
The screenshot below shows "graph" working on the small data table "birds", which has minimal punctuation and only the ASCII letters and numbers.
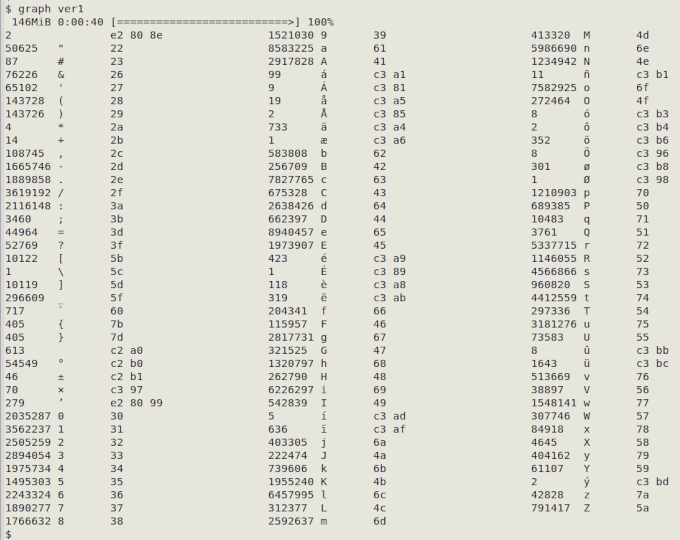
The data table "ver1" is more interesting. It contains multi-byte, non-ASCII letters and symbols, including the unusual (and invisible) "left-to-right-mark" (hex e2 80 8e). Note also the three versions of a single quote (apostrophe, hex 27; right single quote, hex e2 80 99; backtick, hex 60), the invisible no-break space (hex c2 a0) and the unmatched "(" and "[".
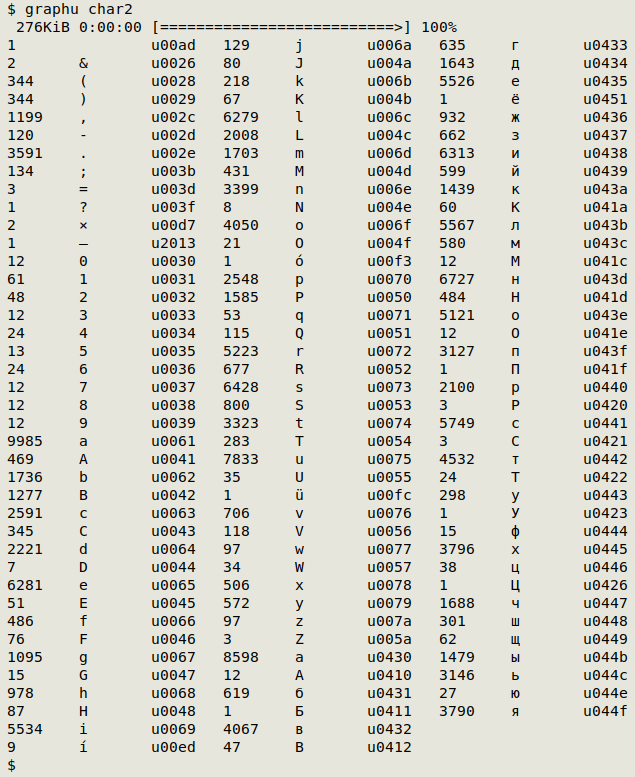
An alternative to "graph" that I call "graphu" will print Unicode code points (formatted "unnnn") instead of hex values:
A script to tally visible characters and their Unicode code points
#!/bin/bash
pv -w 50 -pbt "$1" \
| awk 'BEGIN {FS=""} {for (i=1;i<=NF;i++) if ($i ~ /[[:graph:]]/) {arr[$i]++}} END {for (j in arr) printf("%s\t%s\n",arr[j],j)}' \
| sort -t $'\t' -k2 \
| while read -r line; do printf "%s\t%s" "$line" "$(cut -f2 <<<"$line" | iconv -f utf-8 -t UNICODEBIG | xxd -g 2 | awk '{printf("u%s",$2)}')"; echo; done \
| column
exit
The screenshot below shows "graphu" at work on a UTF-8 file with both Latin and Cyrillic characters. The "u00ad" character is a soft hyphen gremlin: