Combining characters
Some characters can be coded in more than one way in Unicode. For example, there are two different ways to represent a Latin "a" with an umlaut (or diaeresis). You can code the single character ä, or you can code a plain a plus a diaeresis ¨. The isolated diaeresis character is a combining character.
I call a character pair built with a combining character a "combo". Combos create data-processing headaches and should be normalized to their equivalent single characters when data cleaning. Combining characters can be detected using a regular expression class with the function "combocheck", which takes table as its one argument:
Detect and count combining characters
(More information here)
combocheck() { grep -cP "\p{M}" "$1" }
The combining characters most used with Latin letters are in the Unicode block Combining Diacritical Marks, which runs from code point U+0300 to U+036F (hexadecimal cc 80 through cc bf, and cd 80 through cd af).
Print a list of all strings containing combining characters,
together with their record numbers
(More information here)
awk -b '{for (i=1;i<=NF;i++) {if ($i ~ /\xcc[\x80-\xbf]/ || $i ~ /\xcd[\x80-\xaf]/) print NR,$i}}' table
Print a list of unique strings containing combining characters,
together with their frequencies
(More information here)
awk -b '{for (i=1;i<=NF;i++) {if ($i ~ /\xcc[\x80-\xbf]/ || $i ~ /\xcd[\x80-\xaf]/) print $i}}' table | sort | uniq -c
Find the hexadecimal codes for the unique strings
found by the previous command (without their frequencies)
(More information here)
awk -b '{for (i=1;i<=NF;i++) {if ($i ~ /\xcc[\x80-\xbf]/ || $i ~ /\xcd[\x80-\xaf]/) print $i}}' table | sort | uniq | xxd -c1 | cut -d" " -f2-
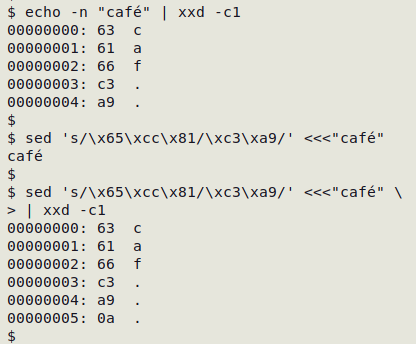
I use sed to replace combos with their single-character equivalents. For example, the string "café" in the first command (screenshot below) contains a plain "e" (hex 65) and a combining acute accent (hex cc 81). The combo is replaced with the single character "Latin small letter e with acute" (hex c3 a9).
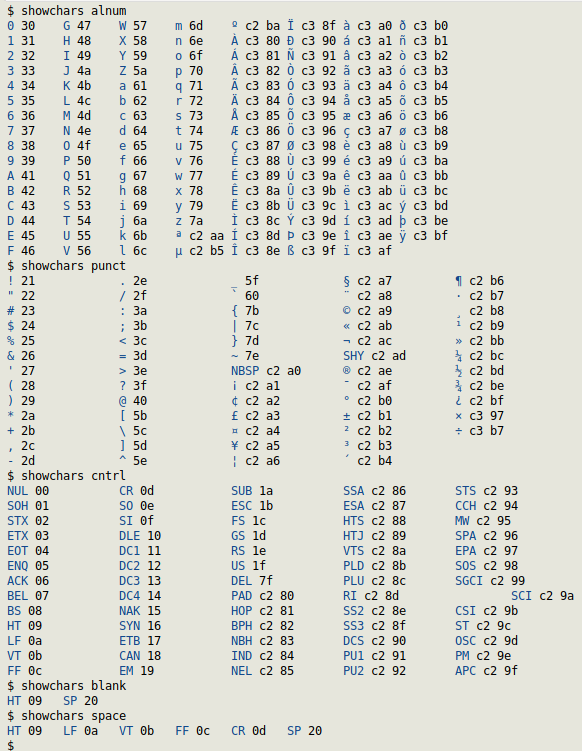
Character classes
The function below lets you quickly check the contents of a POSIX character class, like [:alnum:] and [:punct:], for use in regular expressions. The command relies on a plain-text file called "256chars". It's a list of the first 256 Unicode characters, either as the character itself or an abbreviation, along with a short description of the character, its Unicode code point and the order number in decimal, hexadecimal and octal, together with the hex value in UTF-8 encoding. You can download "256chars" here. The function "showchars" takes as its one argument the POSIX class abbreviation (alnum, punct, cntrl, etc), and prints the character and its UTF-8 hex value.
Print an inventory of a POSIX character class
(More information here)
showchars() { awk -F"\t" -v foo="$1" 'BEGIN {class=sprintf("[[:%s:]]",foo)} NR>1 {x=sprintf("%c",$2); if (x ~ class) print "\033[34m"$5"\033[0m "$7}' path/to/256chars | column; }
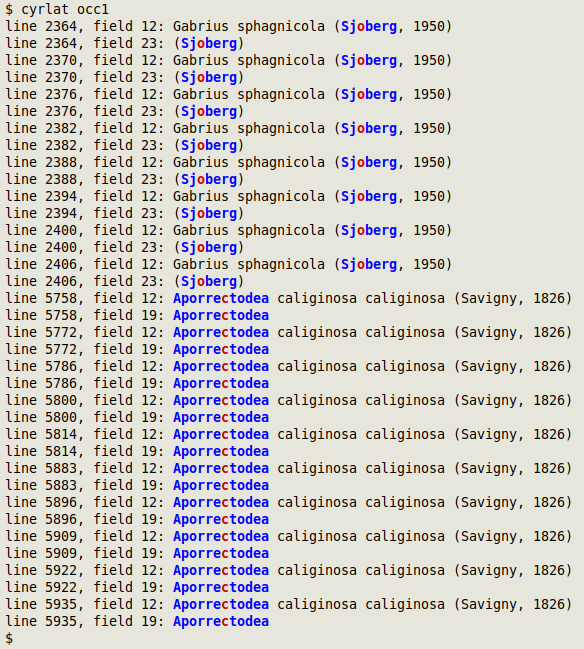
Cyrillic + Latin
The "cyrlat" function finds individual words in which Cyrillic and Latin characters are mixed, and colours Cyrillic in red and Latin in blue. It takes filename as its one argument and prints line number, field number and the whole data item containing the mixed Cyrillic+Latin word. More information here.
Function to find words with a mix of Cyrillic and Latin characters TSV
cyrlat() { latin=$(printf "[\\u0041-\\u005a\\u0061-\\u007a\\u00c0-\\u00ff\\u0160\\u0161\\u0178\\u017d\\u017e\\u0192]"); cyrillic=$(printf "[\\u0400-\\u04ff]"); awk -F"\t" -v lat="$latin" -v cyr="$cyrillic" '{for (i=1;i<=NF;i++) if ($i ~ cyr && $i ~ lat) print "line "NR", field "i": "$i}' "$1" | awk -v lat="$latin" -v cyr="$cyrillic" '{for (j=1;j<=NF;j++) {if ($j ~ cyr && $j ~ lat) {gsub(lat,"\033[1;34m&\033[0m",$j); gsub(cyr,"\033[1;31m&\033[0m",$j); print}}}'; }
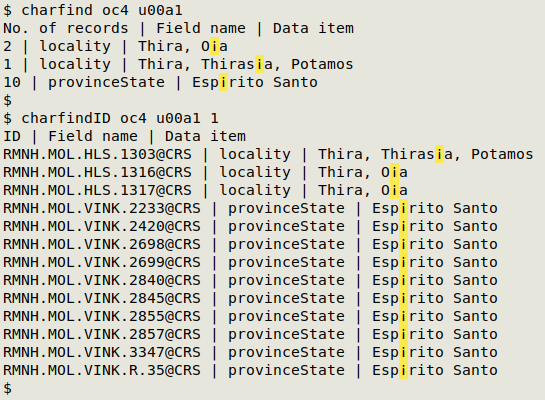
Finding suspect characters
The "charfind" function finds data items in a TSV that contain a particular character. I use it when checking the graphu output for characters that I suspect could be mojibake or OCR artifacts. "charfind" prints the number of records containing the data item, the name of the field in which the data item appears, and the data item itself with the character highlighted in yellow. Results are sorted by fieldname. The function takes two arguments: filename and Unicode code point (uXXXX).
Function to find a selected character by its Unicode code point TSV
charfind() { echo "No. of records | Field name | Data item"; awk -F"\t" -v char="$(printf "\\$2")" 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i} $0 ~ char {gsub(char,"\33[103m"char"\33[0m",$0); for (j=1;j<=NF;j++) if ($j ~ char) print a[j] FS $j}' "$1" | sort | uniqc | sed 's/\t/ | /g'; }
A variant of "charfind" is "charfindID". Instead of returning number of records with the selected character, it prints the entry in a selected ID field in the table. "charfindID" takes the 3 arguments filename, Unicode code point and number of the ID field.
charfindID() { echo "ID | Field name | Data item"; awk -F"\t" -v char="$(printf "\\$2")" -v idfld="$3" 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i} $0 ~ char {gsub(char,"\33[103m"char"\33[0m",$0); for (j=1;j<=NF;j++) if ($j ~ char) print $idfld FS a[j] FS $j}' "$1" | sort -t $'\t' -k2,2 -Vk1 | sed 's/\t/ | /g'; }
In the screenshot below, "charfind" and "charfindID" are looking for the inverted exclamation mark character ¡ (u00a1) in the TSV "oc4", which has a unique record ID in field 1: