
For a full list of BASHing data blog posts see the index page. ![]()
How to find mixed Latin+Cyrillic words
In a 2020 blog post I mentioned ABEHKMOPTXY, an 11-letter string each of whose letters appears in Latin, Greek and Cyrillic scripts, with different Unicode code points:
| Character | Latin | Greek | Cyrillic |
| A | U+0041 | U+0391 | U+0410 |
| B | U+0042 | U+0392 | U+0412 |
| E | U+0045 | U+0395 | U+0415 |
| H | U+0048 | U+0397 | U+041D |
| K | U+004B | U+039A | U+041A |
| M | U+004D | U+039C | U+041C |
| O | U+004F | U+039F | U+041E |
| P | U+0050 | U+03A1 | U+0420 |
| T | U+0054 | U+03A4 | U+0422 |
| X | U+0058 | U+03A7 | U+0425 |
| Y | U+0059 | U+03A5 | U+04AE |
In most monospace terminal fonts these "triplet" letters are indistinguishable:
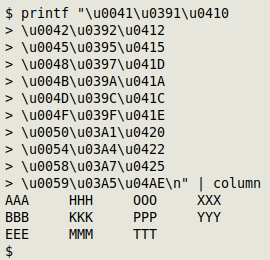
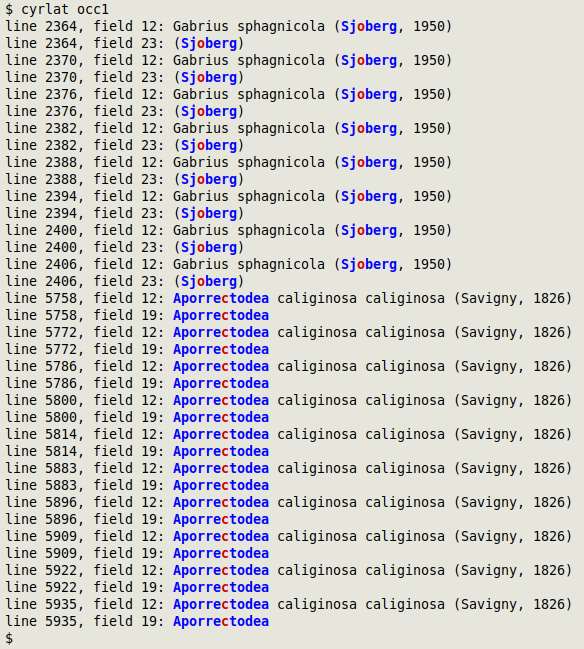
I thought confusions like these were interesting but unimportant oddities until I audited some UTF-8 data files from Russia. Some of the scientific names in those files were made up of mixed Latin and Cyrillic letters. A real-world example was "Aporreсtodea caliginosa caliginosa (Savigny, 1826)", in which the "c" in Aporrectodea was Cyrillic, not Latin.
This had the potential to cause data-parsing errors, so I needed a way to find mixed Latin-Cyrillic words in the files I audit, which are all TSVs, UTF-8-encoded and mostly in Latin script. The function I came up with contains just two AWK commands in series:
cyrlat() { latin=$(printf "[\\u0041-\\u005a\\u0061-\\u007a\\u00c0-\\u00ff\\u0160\\u0161\\u0178\\u017d\\u017e\\u0192]"); cyrillic=$(printf "[\\u0400-\\u04ff]"); awk -F"\t" -v lat="$latin" -v cyr="$cyrillic" '{for (i=1;i<=NF;i++) if ($i ~ cyr && $i ~ lat) print "line "NR", field "i": "$i}' "$1" | awk -v lat="$latin" -v cyr="$cyrillic" '{for (j=1;j<=NF;j++) {if ($j ~ cyr && $j ~ lat) {gsub(lat,"\033[1;34m&\033[0m",$j); gsub(cyr,"\033[1;31m&\033[0m",$j); print}}}'; }
The command is "exploded" and explained below. It finds words containing a mix of Latin and Cyrillic letters, colours the Latin letters blue and the Cyrillic ones red, and prints line number, field number and the whole field with its coloured mixed words. Here's "cyrlat" at work on the data file "occ1":
In "cyrlat" I've used [\u0400-\u04ff] for the Cyrillic range.
The Greek range is [\u0370-\u03ff].
Picking a Latin letter set wasn't so straightforward, because Unicode has several different Latin blocks. I decided to use the Latin letter set encoded in Windows-1252, which has all the English and non-English Latin letters I normally see in my auditing. This "Windows" set has three character ranges and six individual characters: [\u0041-\u005a\u0061-\u007a\u00c0-\u00ff\u0160\u0161\u0178\u017d\u017e\u0192].
"cyrlat" works by first using AWK to find tab-separated fields containing both Latin and Cyrillic letters. For each such field AWK prints the line number, the field number and the whole field. The output is piped to a second AWK command which looks for mixed Latin-Cyrillic words in the field string at the end of the line. AWK colours these mixed words and prints the line. This second step filters out fields containing only all-Latin and all-Cyrillic words.
Breaking down the function's parts:
latin=$(printf "[\\u0041-\\u005a\\u0061-\\u007a\\u00c0-\\u00ff\\u0160\\u0161\\u0178\\u017d\\u017e\\u0192]")
The regex string [\u0041-\u005a...] for the Latin character set is printfed with double backslashes (to preserve the single backslashes) and stored in the shell variable "latin".
cyrillic=$(printf "[\\u0400-\\u04ff]")
The same is done for the Cyrillic set, storing the regex string in the shell variable "cyrillic".
awk -F"\t" -v lat="$latin" -v cyr="$cyrillic"
The first AWK command begins with the instruction that the field separator in the file to be processed is a tab character. The two shell variables are stored in the AWK variables "lat" and "cyr".
for (i=1;i<=NF;i++)
On each line, AWK will loop through the tab-separated fields one by one.
if ($i ~ cyr && $i ~ lat)
AWK checks each tab-separated field to see if it matches (contains) both a Latin letter and a Cyrillic one.
print "line "NR", field "i": "$i
If the field has both kinds of letters, AWK prints the line number, the field number and the whole field, together with explanatory text and punctuation. The entire output from the whole file is piped to the second AWK command.
awk -v lat="$latin" -v cyr="$cyrillic"
This time there's no field separator specified, which means AWK will treat each space-separated word in the line as a field.
for (j=1;j<=NF;j++)
On each line, AWK will loop through the words (space-separated fields) one by one.
if ($j ~ cyr && $j ~ lat)
AWK checks each word to see if it matches (contains) both a Latin letter and a Cyrillic one.
gsub(lat,"\033[1;34m&\033[0m",$j)
If the word has both kinds of letters, AWK substitutes every Latin letter in the word with the same letter made bold and blue.
gsub(cyr,"\033[1;31m&\033[0m",$j)
AWK also substitutes every Cyrillic letter in the word with the same letter made bold and red.
print
Finally, AWK prints the processed output from the first AWK command, with its coloured Latin and Cyrillic letters.
I tried putting the two AWK commands together in a single AWK, but the possible solutions were horribly complicated and suffered from Too-Many-Nested-Brackets Syndrome. If AWKish readers can think of a simple way to combine the two AWK commands, I'd be very interested to hear about it!
The output from "cyrlat" can easily be filtered. For example, I might only be interested in mixed Latin-Cyrillic words in a data field containing scientific names. If that field was field 21 in the TSV "table", I'd do:
cyrlat table | grep "field 21"
Last update: 2021-09-29
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License