
For a full list of BASHing data blog posts see the index page. ![]()
Targeted string replacements with sed and AWK
Global replacement of A with B with sed or AWK might be a mistake unless you're 100% sure that you really, truly want to replace every instance of A with B in the data file. Even more risky (says he, who has done it more than once to his regret) is globally replacing over a whole set of files:
sed 's/A/B/g' *.txt

Base image found here, source unknown.
It's much safer to do replacements targeted at particular instances of A in a file. This post reviews a few strategies for using sed and AWK for targeted string replacements. I can't consider every possible replacement case, but I hope the examples I give are useful.
For demonstration purposes, here's the tab-separated table "reds". What I'll do is replace the underlined "red" words with "white".

| Fld1 | Fld2 | Fld3 |
| red wine | red tape | red shift |
| red hot | red dog | red flag |
| red ink | red fox | red meat |
| red deer | red book | red rice |
To replace the first "red" in line 2, I address line number 2 and occurrence number 1 (in that line). If I leave out the occurrence address, sed replaces the first "red" it finds and then stops looking:

sed '2s/red/white/1' reds
sed '2s/red/white/' reds
In line 3, replacing the second "red" in line 3 uses occurrence address "2":
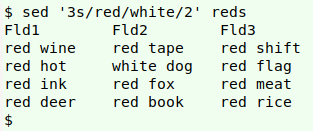
sed '3s/red/white/2' reds
The two replacements in line 4 offer a good demonstration of sed's occurrence-address logic. Once sed has done a replacement in a line, it restarts the count of occurrences. That's why the first command shown below doesn't simply repeat the replacement of the second occurrence. The third command uses a feature of GNU sed: putting "g" after the occurrence address means "that occurrence and all others to the end of the line":
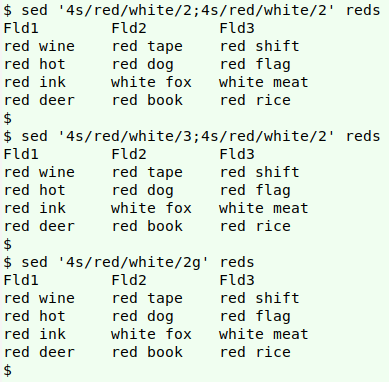
sed '4s/red/white/2;4s/red/white/2' reds
sed '4s/red/white/3;4s/red/white/2' reds
sed '4s/red/white/2g' reds
The line 5 replacement of the first and third "red"s uses occurrence-address logic again:
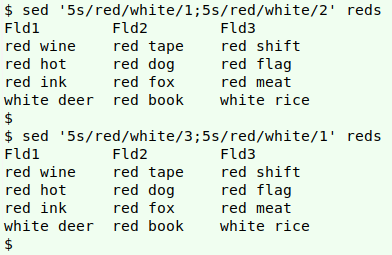
sed '5s/red/white/1;5s/red/white/2' reds
sed '5s/red/white/3;5s/red/white/1' reds
Combining the commands:

sed '2s/red/white/;3s/red/white/2;4s/red/white/2g;5s/red/white/1;5s/red/white/2' reds
Note that in the second version in the screenshot I enclosed the command in double quotes rather than single quotes, to allow use of BASH's interrupted line feature (" \").
Another approach to targeting is to "hook" the strings to be replaced to their context, in other words to a nearby string. In this case I want to replace the "red"s that precede the words:
wine,dog,fox,meat,deer,rice #The order doesn't matter
There isn't an easy way to do this with sed, but I can fill an AWK array "a" with the "hook" words as index strings, then do a replacement whenever "red" and a space are followed by one of the index strings in the array:

awk 'FNR==NR {a[$0]; next} {for (i in a) sub("red i","white i")} 1' <(echo "wine,dog,fox,meat,deer,rice" | tr ',' '\n') reds
The array "a" is built from the redirection <(echo "wine,dog,fox,meat,deer,rice" | tr ',' '\n'), where each word becomes an index string in the array. For each of those index strings, AWK substitutes "white "[word] for "red "[word]. The final instruction "1" tells AWK to print all lines in the file.
AWK is also a better choice than sed for replacements if you want to target a string in a particular line and field, without knowing (or caring) if the string to be replaced is elsewhere in the line. For example, to replace just the "red" in "red dog":
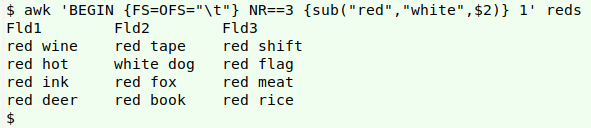
awk 'BEGIN {FS=OFS="\t"} NR==3 {sub("red","white",$2)} 1' reds
Finally, here's AWK doing all my required replacements, with the targets grouped by field:

awk 'BEGIN {FS=OFS="\t"} \
> NR==2 || NR==5 {sub("red","white",$1)} \
> NR==3 || NR==4 {sub("red","white",$2)} \
> NR==4 || NR==5 {sub("red","white",$3)} \
> 1' reds
PUZZLE in last post:
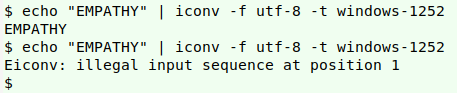
In the second echoed EMPATHY, the "M" isn't a Latin capital letter m (hex 4d). It's a Greek capital mu (hex ce 9c), which isn't on the Windows-1252 codepage. The two "M" letters are homoglyphs and are part of a Unicode triplet of letters that look the same but have different encodings in UTF-8. The third "M" is a Cyrillic capital em (hex d0 9c).
There are 11 letters that form Latin/Greek/Cyrillic triplets: ABEHKMOPTXY. The longest common English word I know that can be made with these 11 letters is EMPATHY.
Last update: 2020-04-08
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License