
For a full list of BASHing data blog posts, see the index page. ![]()
Combo characters
There are two different ways to represent a Latin "a" with an umlaut in Unicode. You can use the single character ä, or a plain a plus an umlaut (diaeresis) ¨. The second choice involves a combining character, and I call the resulting combination a "combo":

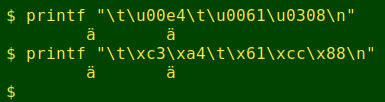
As you can see in the screenshot above, the single and combo characters look the same in my terminal (UTF-8 locale), but they're not the same. In "file" (screenshot below), the ä in the first and third lines is a single, and the ä in the second line is a combo. Watch what happens when I do a search with grep:
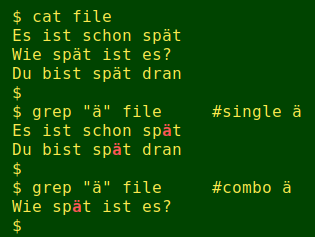
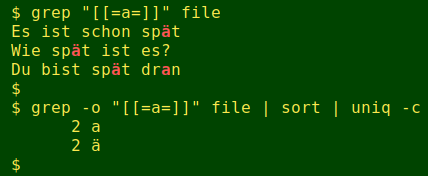
A search for all "a-like" characters turns up the four occurrences in "file", but grep, sort and uniq misclassify the combo in line 2 as a plain "a":
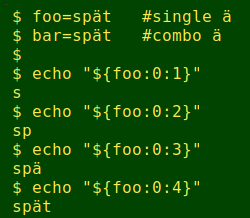
Searches aren't the only operations that combos mess up. Extracting substrings also becomes problematic, as shown here with the BASH substring syntax:
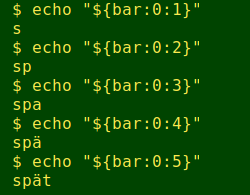
Unfortunately for data processing on the command line, there are many, many combining characters in Unicode. Some can even appear in more than two equivalent combos:
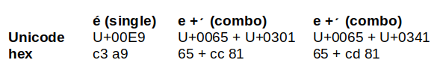

To avoid data processing problems caused by combos, it's best to convert them to their "single" versions. This is sometimes called "Unicode normalization" and there's a fair-sized technical literature on the subject.
For data auditing purposes I first check for the presence of combos before converting them to singles with awk or sed. I don't know of a simple general way to search for all the many combos, but the combining characters most used with Latin letters are in the Unicode block Combining Diacritical Marks, which runs from code point U+0300 to U+036F (hex cc 80 > cc bf and cd 80 > cd af).
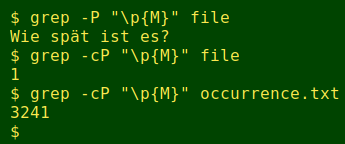
If your grep supports Perl-type syntax, there's an easy way to search for these particular combining characters, as shown below, because they're all in the Unicode regex category "Mark". It's a good idea to count the lines with combining characters first, rather than have a vast number of results in your terminal. For example, the file "occurrence.txt" (see next screenshot) has 3241 lines with combining characters!
grep -P "\p{M}" file
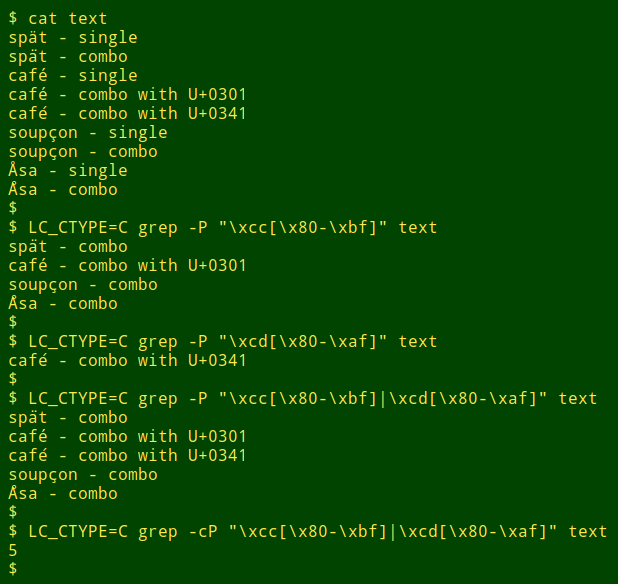
You can also search with grep using the hex value ranges of the combining characters, but you may need to change the locale for the command to allow grep to match individual bytes. Here I'm searching the file "text", and I've gone from UTF-8 to "C" in the individual commands:
LC_CTYPE=C grep -P "\xcc[\x80-\xbf]|\xcd[\x80-\xaf]" file
After I've detected the presence of combos, I use AWK (GNU AWK 4) to get their context. The following command breaks lines into words (strings separated by spaces or tabs) and lists words with combos after their line numbers. Note that AWK here has the option "-b", which acts like the locale change for grep and forces AWK to treat all input data as 1-byte characters.
awk -b '{for (i=1;i<=NF;i++) \
{if ($i ~ /\xcc[\x80-\xbf]/ || $i ~ /\xcd[\x80-\xaf]/) print NR,$i}}' file
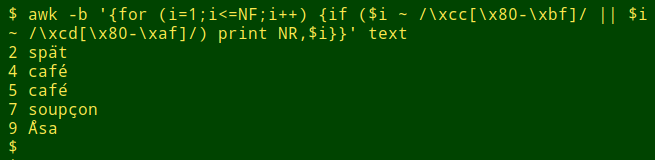
A variation of that AWK command sorts and counts the words with combos. As shown below, all 3241 lines in "occurrence.txt" with combos have the same combo-containing word.
awk -b '{for (i=1;i<=NF;i++) \
{if ($i ~ /\xcc[\x80-\xbf]/ || $i ~ /\xcd[\x80-\xaf]/) print $i}}' file | sort | uniq -c

Finally, for conversion purposes I need to know the hex values of the combos, and for that I like to use xxd:
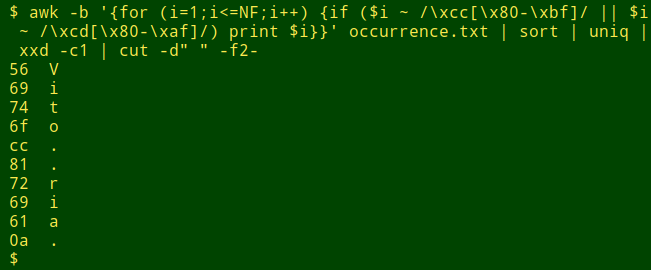
What happens next depends on the particular dataset I'm auditing, but in any case sed is a fast and reliable character converter. Here it's converting the combo ó, hex 6f cc 81, to the single ó, hex c3 b3:

Last update: 2018-06-09
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License