
For a full list of BASHing data blog posts see the index page. ![]()
Build your own character class inventories — updated
In the middle of 2019, AWK guru Ed Morton offered something interesting on Stack Overflow, namely an AWK script which prints out all the characters on your system that are represented in POSIX character classes, like [:alnum:] and [:punct:].
Morton's script is fairly complicated and I wondered if there was a simpler way to do the same job on my Linux system. A command I came up with is based on GNU AWK's printf. If you specify the format as "%c", printf will print a (decimal) number as a character. For example, the "at" character "@" in ASCII (or UTF-8) encoding has the value 64. If I feed 64 to printf "%c", I get the character "@":

The numbers 0 through 255 define 256 characters. I can feed a list of those 256 numbers to AWK using seq, get the numbers sprintfed as characters into a variable, then test the variable to see which characters match which character class. I can print out the matches, then format the output neatly with paste:
seq 0 255 | awk '{x=sprintf("%c",$0); if (x ~ /[[:digit:]]/) print x}' \
| paste -s -d " "
It works well:

A digression: I don't have to stop at 256. According to the GNU AWK manual, ...when printing a numeric value [with "%c" formatting], gawk allows the value to be within the numeric range of values that can be held in a wide character. This means I can see what multi-byte characters are matched by [:alpha:], for example, in the range 256-511. These multi-byte characters will be printed so long as they're understood by my terminal font, Bitstream Vera Sans Mono Roman:

Alas, not even the versatile AWK can print non-printing characters, like those in [:space:] and [:cntrl:]. To visualise these, Morton mapped them in an array to abbreviations like "NUL". My workaround was to build a tab-separated lookup table called "256chars". It lists each of the first 256 characters either as the character itself or an abbreviation, along with a short description of the character, its Unicode code point and the numerical encoding in decimal, hexadecimal and octal as understood by AWK's printf. I updated the table in January 2020 to include each character's encoding in UTF-8, in hexadecimal. You can download "256chars" here; below is a screenshot of a portion of the table:

I like to know a character's hex value on my system, so I wrote a new command, similar to the one above, which works on "256chars" and prints both the character and its hex value in UTF-8 encoding. I added some ANSI color to emphasise the character:
awk -F"\t" 'NR>1 {x=sprintf("%c",$2); if (x ~ /[[:blank:]]/) \
print "\033[34m"$5"\033[0m "$7}' 256chars | column
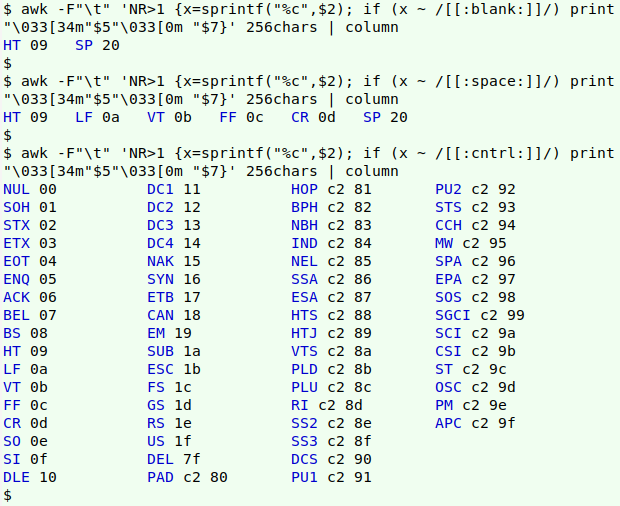
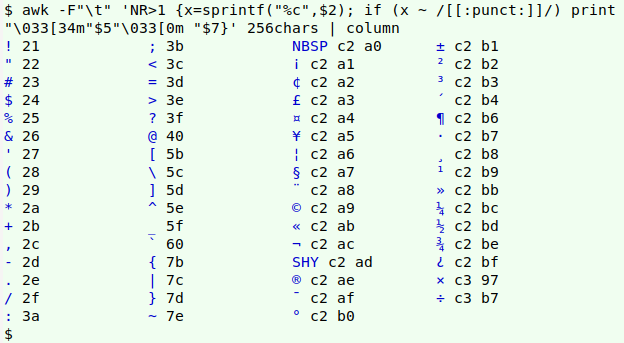
The command also works, of course, on printable characters. Note that the invisible no-break space (NBSP) and soft hyphen (SHY) are treated as printable in [:graph:], [:print:] and [:punct:]:
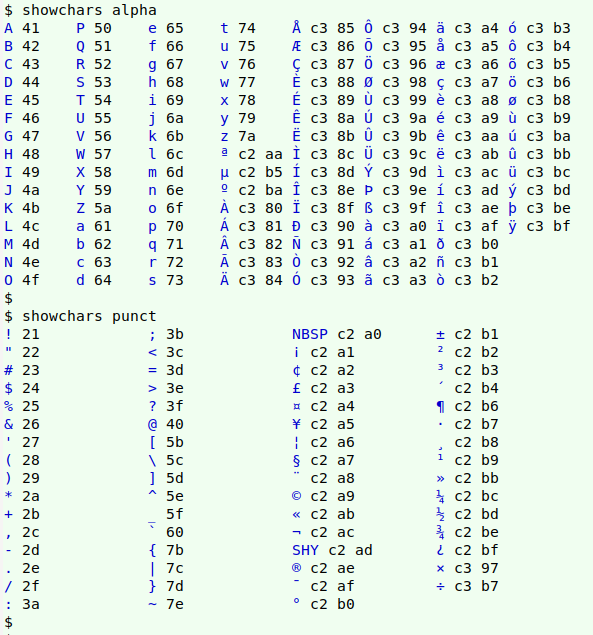
Finally, to simplify the inventorying of character classes this way, I put the command in a function, "showchars". The lookup table "256chars" lives in my "scripts" folder.
showchars() { awk -F"\t" -v foo="$1" 'BEGIN {class=sprintf("[[:%s:]]",foo)} NR>1 {x=sprintf("%c",$2); if (x ~ class) print "\033[34m"$5"\033[0m "$7}' \
~/scripts/256chars | column; }
The argument for "showchars" will be something like "digit". This shell string will be sent to the AWK command as the variable "foo". In the BEGIN statement, AWK will sprintf "digit" as "[[:digit:]]" into the variable "class". Note that in the test if (x ~ class), "class" doesn't have to be put within regex markers ("/").
Last update: 2020-01-05
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License