A "typo" is a text error in typing or typesetting, usually caused by a human pressing the wrong key on a keyboard. What I call a "replo" is a text error caused by a computer replacing one or more characters with a question mark, a replacement character (�) or what looks like gibberish. As described below, replos can be sorted into three categories based on data cleaning strategies.
Reversible replos
A reversible replo appears when your text-viewing software is set to the wrong character encoding. When you convert the text to the correct encoding, the original characters appear. For example, suppose I tell my terminal to print a certain string of 1-byte characters:

I get 3 replos, each a replacement character, because my terminal program was expecting that the string would be UTF-8 encoded (like everything else on my Linux system) but the string was actually in a different encoding. I can repair the replacements with iconv. In this case, the 1-byte characters I used were in Mac OS Roman encoding (not the more familiar Windows-1252 or Latin-1 = ISO 8859-1):
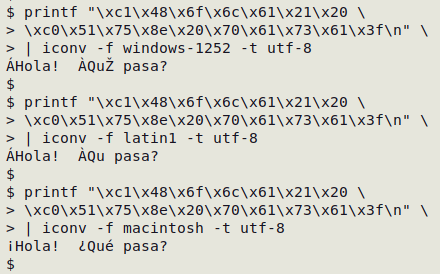
Finding the correct original encoding of a replo can be challenging, but for reversible replos iconv is an efficient data-cleaning tool. Wikipedia has a helpful page on common Western encodings.
Reconstructable replos
A reconstructable replo is a job for a data detective. It's a character (or characters) related to the original by a chain of encoding conversions, and if you can puzzle out the chain, you can often reconstruct the original. Here's an interesting real-world example:
The word I found is seen below as it appears in Geany text editor. It's a good example of mojibake gibberish. There are four visible replos in a row between "S" and "chier".
Saving the word in the variable "string", I can find the hex values of the replos with xxd:
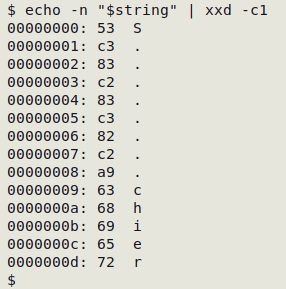
The replos are Latin capital A with tilde (Ã, hex c3 83), the control character "no break here" (NBH, c2 83), Latin capital letter A with circumflex (Â, c3 82) and the copyright sign (©, c2 a9). How did they get there?
My guess was that the word started out in UTF-8 encoding, where é has the 2-byte hex value c3 a9. The word then went into a Windows-1252 program and each byte was read separately, giving é in Windows-1252 encoding. The transformed word was then processed in a UTF-8 locale, where à became c3 83 and © became c2 a9. The word was again processed by a Windows-1252 program, and again the 2-byte characters were read byte-by-byte. This gave à (c3), the control character "no break here" (83),  (c2) and © (a9). Finally, the strings went to a program that encoded into UTF-8 each of the 1-byte Windows-1252 characters separately. In summary, the word Séchier experienced the encoding history UTF-8 > windows-1252 > UTF-8 > windows-1252 > UTF-8.
For more reconstructions from mojibake, see these BASHing data posts:
Mojibake detective work (2018-08-06)
Return of the mojibake detective (2019-07-05)
More mojibake fun (2020-04-01)
Mojibake bonanza (2020-12-16)
Mojibake madness (2021-05-19)
I also recommend this webpage compiled by Tex Texin for decoding Windows-1252 replos in UTF-8.
Another kind of reconstructable replo occurs when a program replaces a character with its hex or Unicode value inside angle brackets, for example Müller becoming M<fc>ller, where fc is the hex value for "u" with an umlaut in Windows-1252 and some other encodings (in UTF-8 the hex value is c3 bc). For more on "angle bracket replos", see this BASHing data post.
Researchable replos
A researchable replo is one where guessing the encoding and trying to reconstruct conversions are hopeless tasks. The original character has been replaced with a perfectly valid new character, such as a question mark, which has no relation whatsoever to the original. Some research is needed to clean the data.
I sometimes find researchable replos when auditing data tables containing personal names from eastern Europe. An example was "Zapa?owicz". From context it could have been the surname of a botanist, and some googling turned up Hugo Zapałowicz (1852-1917), a Slovenian botanist and traveller. To be certain, I would have needed to check with the compiler of the data file I was auditing, since "Zapanowicz" is another European surname. The curious original character is "latin small letter l with stroke", Unicode U+0142, hex value c5 82.
Because a question mark replo is no different from an original question mark, the only way I know to find a replo "?" is to search for all words with a "?", then scan the results for likely replos. I do this with the function "qwords", which excludes URLs (these often contain "?"):
List words with leading, trailing or included question marks
qwords() { grep -o "[^[:blank:]]*?[^[:blank:]]*" "$1" | grep -v "http" | sort | uniq -c | less -X; }
As an example, the large data table "ver1" contains 52769 "?" (see here). Running "qwords" on the table generates a tallied list of only 214 strings. Scanning the list, I find these likely replos:
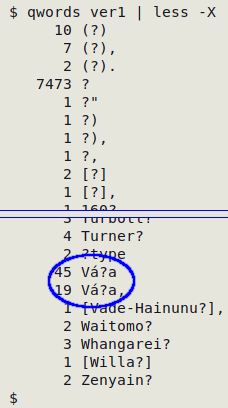
A tally of unique data items containing the string puts the string in context:

Googling on one of these scientific names, I learn that the string is the surname of the Czech paleobotanist Jiří Váňa, where the "?" replo has replaced a Latin small letter n with caron, hex c5 88. I can use that hex value to do a global replacement with sed:
sed 's/Vá?/Vá\xc5\x88/g' ver1
demonstrated here:

Another valid-character replo is the replacement character, �. The function "rcwords" is similar to "qwords", although the syntax for grep is a little more complicated:
List words with leading, trailing or included replacement characters
rcwords() { grep -o "[^[:blank:]]*["$'\xef\xbf\xbd'"][^[:blank:]]*" "$1" | sort | uniq -c | less -X; }