
For a full list of BASHing data blog posts, see the index page. ![]()
Return of the mojibake detective

Last year in BASHing data I gave an example of mojibake detective work. A UTF-8 dataset I was auditing ("ver3") had the name "Séchier" in it. Somehow the "e" with an acute accent had disappeared and become 4 other characters in my UTF-8 locale, namely Ã, the invisible control character "no break here", Â and ©. Here's a byte-by-byte breakdown in hexadecimal using xxd:
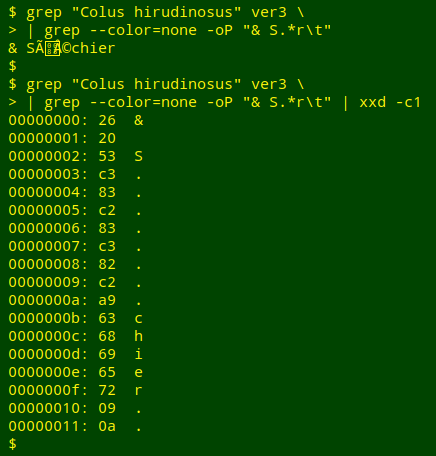
I'll never know the encoding history of that word for certain, but a possible history is UTF-8 > windows-1252 > UTF-8 > (Windows?) > UTF-8, like this:

Three more cases for the mojibake detective are shown below...
An incorrect identification. This example appeared in a Stack Overflow post in January 2018:
IDENTIFICAÌàÌÄO instead of identificação
The string "IDENTIFICAÌàÌÄO" occurred in a UTF-8 file. Because there's a lowercase character (à) in the string, it seems likely that the gibberish-ing happened when the string was all uppercase, i.e. "IDENTIFICAÇÃO". Because 2 characters had become 4, I also suspected that 2-byte characters had been read 1 byte at a time. This led me to a possible explanation involving Windows-to-Mac-to-Windows encoding changes:

There's an archived webpage from Indiana University with a handy comparison table including Mac Roman and Windows 1252.
A muddled mycologist. The bolete mushroom Xerocomellus rubellus (Krombh.) Šutara was classified by the Czech mycologist Josef Šutara, whose last name begins with a capital S with a caron. In the UTF-8 file I was auditing, that character was replaced by �, an uninterpretable character that had the hex value 8a. That's the hex value of the C1 control character "VTS" (vertical tabulation set or line tabulation set) in some common encodings.
My guess is that the string started out in windows-1252 encoding, where Š has the hex value 8a. The file was then converted to iso-8859-1, where 8a is "VTS". In UTF-8 encoding, "VTS" has hex value c2 8a.
A corrupted state. Another UTF-8 file I examined had a strange corruption in the name of the German state Baden-Württemberg. At first glance the "ü" had been replaced by a comma and a blank space, but an xxd breakdown shows something more complicated:
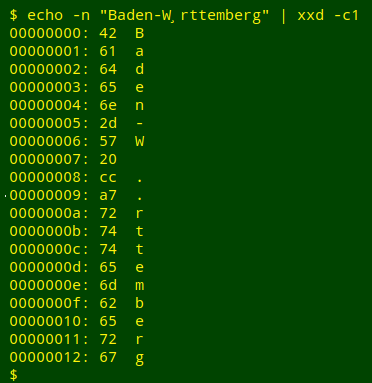
The "comma" is actually a combining cedilla (hex cc a7) — a cedilla used as an attachment to another character. In the place name it combines with the preceding blank space (hex 20). If the space is omitted, the cedilla combines with the preceding "W":
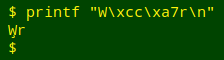
For more on combining characters, see this BASHing data post from 2018.
The hex value fc gives "ü" in windows-1252 encoding, while the same hex value in the legacy Mac-Roman encoding is a cedilla. So possibly:

I don't know what program added the blank space before the cedilla, though. It might have happened either in the Windows-to-Mac conversion or the Mac-to-UTF-8 conversion, and it could well have been a font-dependent action. This mojibake is still an unsolved crime...
Last update: 2019-07-05
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License