
For a full list of BASHing data blog posts, see the index page. ![]()
Mojibake detective work
A dataset I recently audited contained multiple UTF-8 encodings of the same characters. For example, the dataset contained three different °, three different ' and three different ".
Let's look at the quote marks first, with both Unicode and hexadecimal escapes. My terminal font is Noto Mono Regular:

To human eyes, the differences are no big deal. All three versions of the quote marks are readable and understandable. But my locale is UTF-8. What happens when the same characters are displayed in a non-UTF-8 locale, like the widely used windows-1252?
Answer: mojibake. According to the string-functions.com analyser:
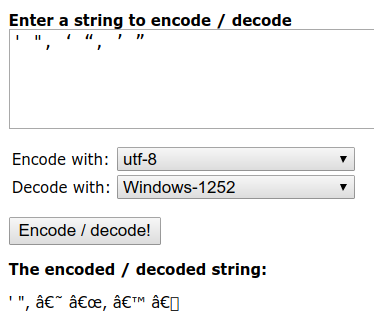
Notice that the one-byte ' and " came through just fine. The others... Well, it's logical. In a windows-1252 locale, the multi-byte UTF-8-encoded characters will be interpreted one byte at a time. Hex e2 is "Latin small a with circumflex", â, and hex 80 is "Euro sign", €. Hex 98, 9c, 99 and 9d are (respectively) ~ (small tilde), œ (Latin small ligature œ), ™ (trademark sign) and "undefined".
The lesson here is that single and double quotes are portable between UTF-8 and windows-1252 if you use their simplest encoding. The fancy characters used in the dataset I was auditing (left and right single quote marks, left and right double quote marks) are going to cause trouble as data is moved from locale to locale.
The degree symbol, however, is troublesome no matter what you do. Here are the three versions of "degree" I found in that dataset:
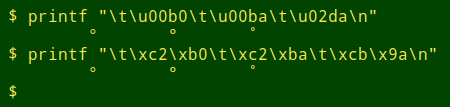
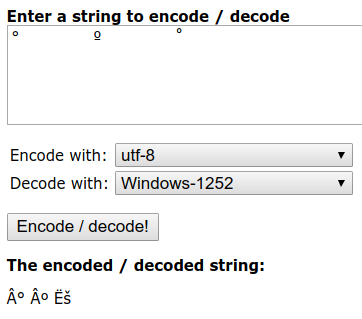
The problem with the simplest UTF-8 encoding, hex c2 b0, is that in windows-1252 the degree symbol is even simpler, namely hex b0, and hex c2 is "Latin capital A with circumflex", Â.
A UTF-8-encoded degree that's gone into a windows-1252 (or iso-8859-1) locale and then been reimported into UTF-8 will look like ° and will need repairing. And a windows-1252 degree that's gone into UTF-8 is just not interpretable:
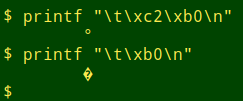
I see a lot of mojibake in my data auditing work. This UTF-8 file ("ver3") had four instances of the same garble:
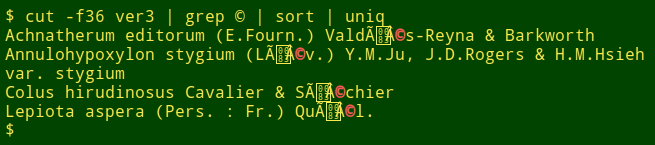
The correct strings are "Valdés-Reyna", "(Lév.)", "Séchier" and "Quél." How did "e" with an acute accent get so messed up?
I suspect that the strings started out in UTF-8 encoding, where é is hex c3 a9. The strings then went into windows-1252, where each byte was read separately, giving é. The strings returned to UTF-8, where à became c3 83 and © became c2 a9. The poor strings now went back to windows-1252, and a byte-by-byte reading gave à (c3), the control character "no break here" (83),  (c2) and © (a9). Finally, the strings went to a program that encoded into UTF-8 each of those windows-1252 characters separately.
My guess, then: UTF-8 > windows-1252 > UTF-8 > windows-1252 > UTF-8.
Another odd character was showcased in a previous BASHing data blog:
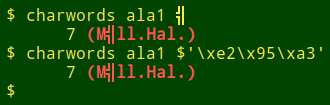
The original character was a small "u" with an umlaut, ü. That's hex fc in windows-1252 and c3 b3 in UTF-8. How it came to be e2 95 a3 is a mystery for a mojibake detective to solve...
The best online resource I've found for understanding character sets and encodings is What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text.
Last update: 2018-08-06
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License