
For a full list of BASHing data blog posts see the index page. ![]()
An unexpected character replacement
As a data auditor I'm used to seeing non-ASCII characters appearing as replacement characters, question marks and mojibake:

A few weeks ago I found a replacement in GBIF that I'd never seen before: M<fc>ller. It was a hexadecimal value for the character "ü" enclosed in angle brackets. That particular hex value for "ü" appears in Windows-1252 and other encodings, but what program did this replacement? And why?
Suspecting the worst, I did a search for other angle-bracket-enclosed strings in the dataset. The search turned up a lot of data items which had originally contained a non-breaking space, and which now contained that character's Unicode representation in brackets, for example Laevicardium<U+00A0>. Excluding these, the result is shown here:
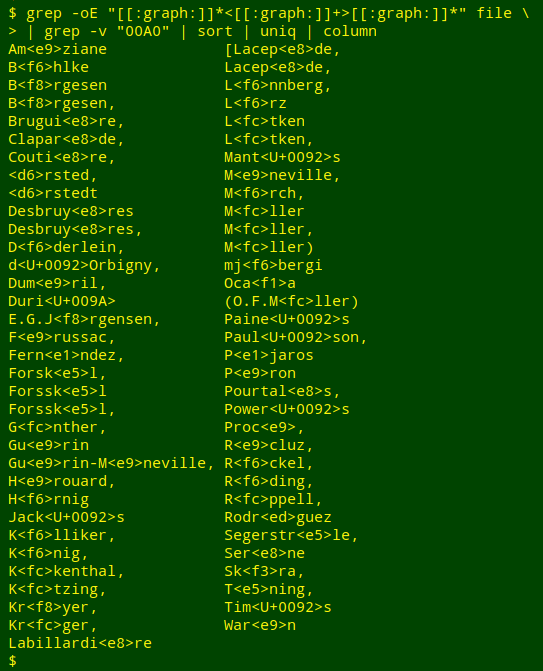
The first grep command searches for strings matching the regex [[:graph:]]*<[[:graph:]]+>[[:graph:]]* which in plain English is zero or more graphic characters (printable characters but not a space), followed by a left angle bracket, followed by 1 or more graphic characters, followed by a right angle bracket, followed by zero or more graphic characters. The "-o" option extracts the matching strings from their lines, and the "-E" option puts grep in "extended regular expression" mode to allow use of "+" for "1 or more".
The characters replaced by hexadecimal values all seemed to be in Windows -1252 encoding:

The Unicode replacements are a bit less obvious, as both are control characters. "U+0092" is PU2 (private use 2) and "U+009A" is SCI (single character introducer). The first one appears in places you would expect a single quote, and a right single quote has the Windows-1252 encoding "92" in hexadecimal. So why didn't that appear as "<92>"?
The same happened with the other Unicode replacement, "U+009A". The original was "Duriš" (it should actually have been "Ďuriš", but that's another issue), and that final "s" with a caron is encoded in Windows-1252 with the hex value "9a".
Baffled, I went to the website of the organisation in the USA that managed the dataset sent to GBIF. There was an Excel version of the data available for download, and when I opened it all the original non-ASCII characters were present and none had been replaced.
I then contacted the US scientists who compiled the data and sent it to GBIF. The dataset started out as a Microsoft Excel file, presumably in Windows-1252 encoding. This was converted into a CSV, then loaded into the R environment for adding additional information required by GBIF, then exported from R as a text file with the command option fileEncoding = "UTF-8".
The culprit seems to be R. For example, the text-cleaning function replace_non_ascii will generate output with hexadecimal values within angle brackets. I'm not sure whether that tool or some other R "text cleaner" was also doing the incorrect Unicode replacements.
In the meantime, I've added another data check to my auditing routine: look for weird character replacements in angle brackets.
Last update: 2019-10-18
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License