
For a full list of BASHing data blog posts, see the index page. ![]()
iconv and illegal input sequences
Character encoding is a big topic and this post isn't going to cover it all. In fact, I'm only going to deal with one particular problem — what to do when you're converting a file with the iconv utility and you get a error message like this:

What just happened? One possibility is that "file" has been corrupted, and it now contains a sequence of bytes that doesn't correspond to a character in any encoding. The more likely explanation is that the file "file" is perfectly OK and iconv is doing its job properly. You told it to convert a windows-1252 file, but the file is in fact not in windows-1252 encoding, and iconv has found a byte sequence that's meaningless in windows-1252.
You can tell iconv to ignore with the -c option any characters it regards as illegal. That's not a very satisfactory workaround, because you lose information, as shown below:
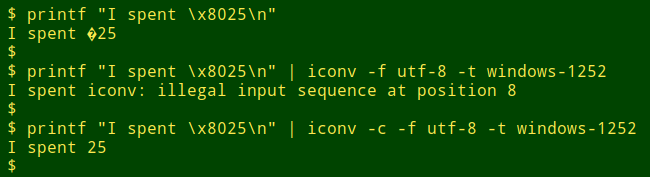
This is a screenshot from my terminal, which works in a UTF-8 environment. Given that first printf command, the terminal doesn't know what to do with a character with a hex value of 80, so it replaces the unknown character with a �, which logically enough is called "the replacement character".
Second command: in trying to convert the "\x80" character from UTF-8 to windows-1252, iconv also doesn't know what to do and throws up an error message. Notice that iconv says that the character represented by "\x80" is at position 8 in the string, although it looks like it's at position 9. This is because iconv counts character positions from 0.
Finally, if I run iconv with the -c option, the character disappears. Not helpful. Did I spend 25 dollars? Euros? Yen?
Actually, the character with a hex value of 80 is a perfectly good part of the windows-1252 character set. If I convert the string from windows-1252 to utf-8, the mystery is solved. iconv converts the hex 80 in windows-1252 to its multi-byte UTF-8 equivalent, hex e2 82 ac, as shown by xxd:

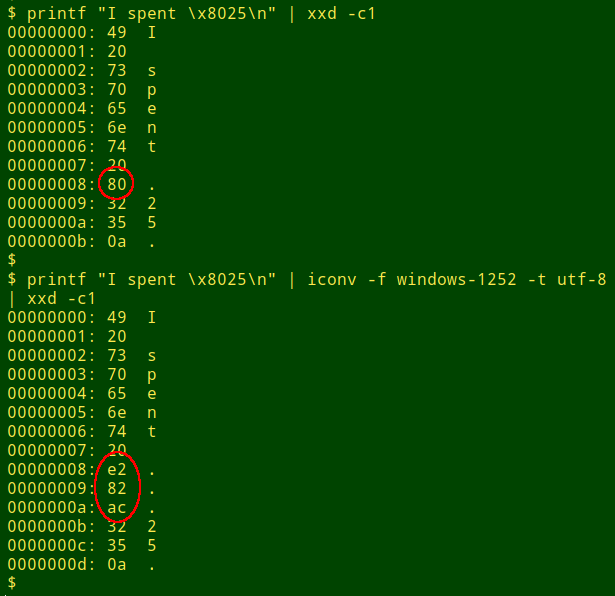
So the iconv "illegal input" issue may not be a problem if you know in advance the character encoding of the file to be converted. Unfortunately, standard Linux utilities like file and uchardet don't always give reliable answers about a file's encoding. Here's a simple example. I'll save as the file "test" the string "€25", but for "€" I'll use its ISO 8859-15 hex value, a4:
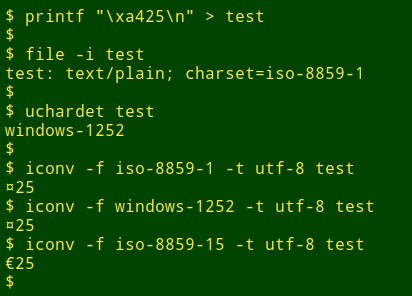
As you can see, both file and uchardet got the encoding wrong, but given the correct encoding, iconv did the conversion correctly.
If you get that iconv error message you could try some other "from" encodings to see if that fixes the problem. But that won't help if the file is corrupted in some way. Here's a more general workaround, detailed here for a sample conversion. Before it got corrupted, the original was a 6-line windows-1252 file:
A powerful postwar short story
from Germany is Wolfgang Borchert's
"Die Küchenuhr" (1947), set
on a public bench in
an unnamed town or city
where three people meet.
but the "ü" has since been replaced, and iconv is complaining:

At the point it which it gives up, iconv will have successfully converted all previous characters in "file". I can go straight to the roadblock by asking AWK to show the unfinished last line of the new file and its line number:

Next, I use xxd to find the hex value of the problematic character in the identified line in the original file:
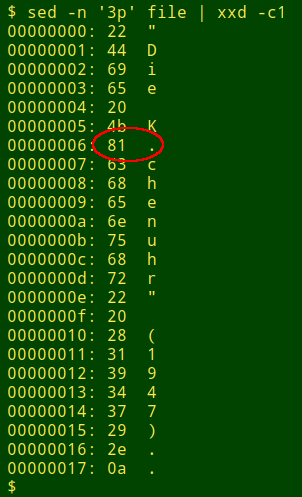
The roadblock character has a hex value of 81. (It's the control character "High Octet Preset".) I re-run the conversion, this time using sed to replace the roadblock character with a "ü" (windows-1252 hex value fc) in line 3 of the original file:
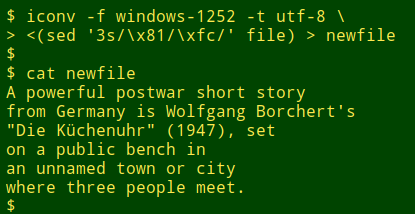
In this case I knew what the character was before it got corrupted, but I'm not always so lucky. Sometimes the original character(s) will be obvious from context or from external data sources, but I might have to check with the data manager or compiler.
There may be other instances of the same character problem in the file. After the first iconv halt and its fix, my practice is to check for other appearances of the illegal character using "gremfinder" or a similar tool from the Cookbook, and then do the necessary substitutions. It also often happens that iconv stops at a completely different "illegal input sequence" further into the file's conversion. If that happens I repeat the last line / xxd / sed procedure with the new "illegal" until iconv can do the file conversion successfully.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License