TSV This marker means that the recipe only works with tab-separated data tables.
A better uniq count
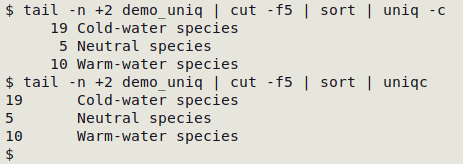
The uniq -c command from "coreutils" counts unique items in a list, then puts the right-justified count one space to the left of the item. For many purposes I've found a left-justified count to be more useful, separated from the data item by a tab. To do this I use the following alias:
alias uniqc="uniq -c | sed 's/^[ ]*//;s/ /\t/'"
Reformat tab-separated items
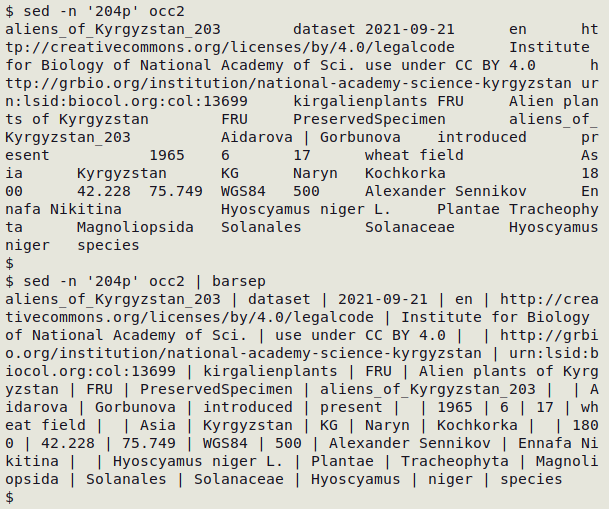
Tab separation is fine for data operations, but can be hard to visualise in outputs, especially if there are blank data items. The "barsep" alias replaces tabs with [space][pipe][space]:
alias barsep="sed 's/\t/ | /g'"
Visualise single spaces
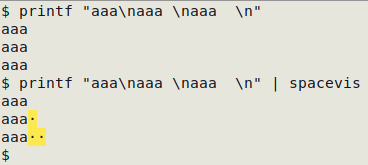
The "spacevis" function replaces each whitespace with a mid-level dot on a yellow background. If piping the result of less paging to "spacevis", use less -R.
spacevis() { sed 's|\x20|\x1b[103m\xc2\xb7\x1b[0m|g'; }
A special date check
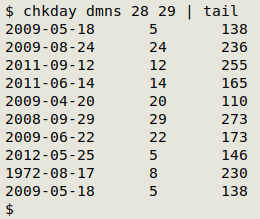
The "chkday" function does a very specialised job: in TSV tables with one field containing an ISO 8601 date (YYYY-MM-DD format) and another field containing the corresponding day number for that date (1 to 365, or to 366 in a leap year), "chkday" looks for disagreements between date and day number. The function returns ISO 8601 date, the given day number and the correct day number. More information here.
Check for disagreement between ISO 8601 date and day number TSV
chkday() { awk -F"\t" -v isodate="$2" -v dayno="$3" 'NR>1 && $isodate != "" && $dayno != "" {split($isodate,a,"-"); b=strftime("%j",mktime(a[1]" "a[2]" "a[3]" 0 0 0")); if (b != sprintf("%03d",$dayno)) print $isodate FS $dayno FS b}' "$1"; }
In the screenshot below, the table "dmns" has the ISO 8601 date in field 28 and the corresponding day number in field 29, but there are numerous disagreements.
A special cross-file check
Some of the TSV pairs I audit have a "referential integrity" failure. The files "event.txt" and "occurrence.txt" share the field eventID. In "event.txt", eventID is the primary key, and in "occurrence.txt" it's a foreign key. Sometimes there are eventID entries in "occurrence.txt" without a corresponding entry in "event.txt", leaving those occurrence records without event details.
To check for this problem I wrote the "chkevoc" script described in this BASHing data post. The script also checks to ensure that there are no blank or duplicate eventID entries in "event.txt", and no blank or duplicate occurrenceID entries (primary key) in "occurrence.txt". The script finds the relevant fields in "event.txt" and "occurrence.txt" by their fieldnames in the header.
The "chkevoc" script could be adapted to any pair of tables where referential integrity needs to be checked.