
For a full list of BASHing data blog posts see the index page. ![]()
DIY primary/foreign key relationships, again — updated
In a blog post in 2020 I described a problem I was finding in linked tables. One table had a primary key field and the other had a foreign key field that should have referred back to the first table. That wasn't always the case, because the tables didn't always come from a database with referential integrity. The tables were sometimes built in spreadsheets and the primary and foreign keys were entered by hand.
The defective tables usually have formatting differences or orphaned foreign keys. The formatting issue is that the primary key is something like "Abc_def_236-ghi" and the foreign key is "Abc-def-236-ghi"; close, but no cigar. Orphaned foreign keys are correctly formatted entries with no match at all in the primary key set.
After seeing these failures often enough, I wrote a script ("chkevoc") that does a health check on the two tables and reports any failed key matches. The script is shown at the end of this post. My working directory for the script will contain the tab-separated tables "event.txt" and "occurrence.txt" with the following structure:
event.txt has
- a primary key field called eventID
occurrence.txt has
- a primary key field called occurrenceID
- a foreign key field called eventID
These three fields can be anywhere in their respective tables. As a result of data entry errors, any of the fields could have blanks or duplicates. Duplicates in the primary key fields, of course, are a no-no, but are OK in the foreign key field.
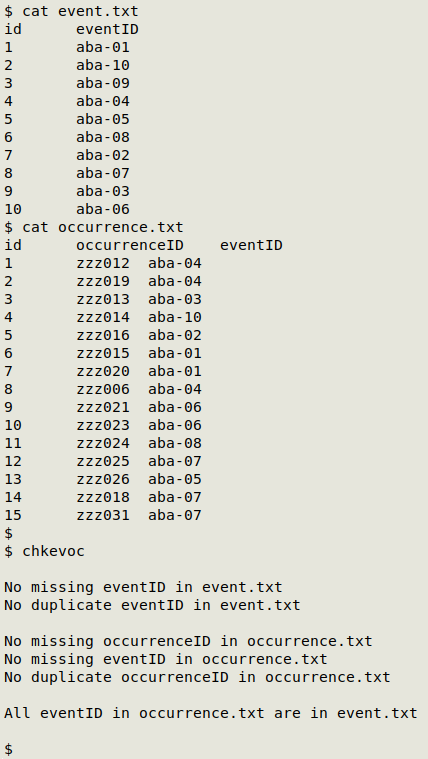
Here's "chkevoc" at work on a perfectly OK couple of demo tables:
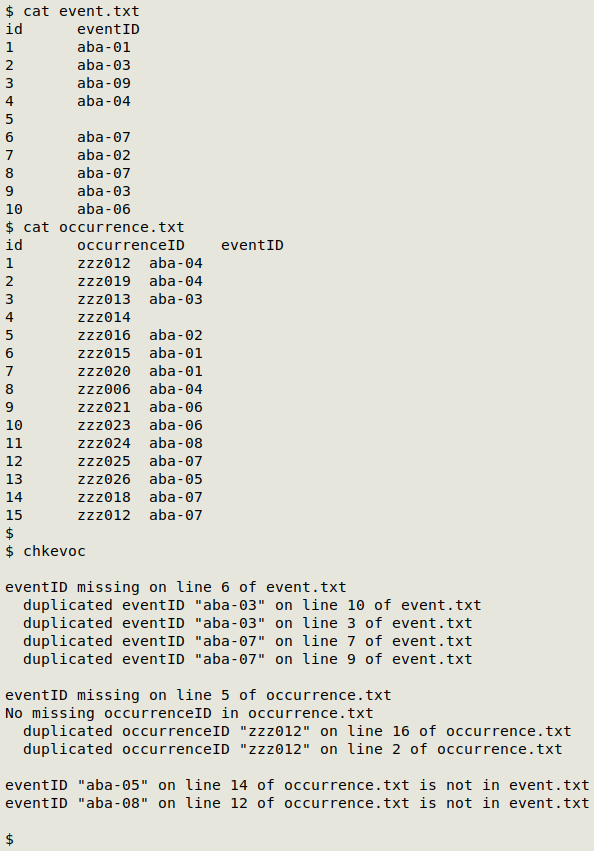
A couple of horrors:
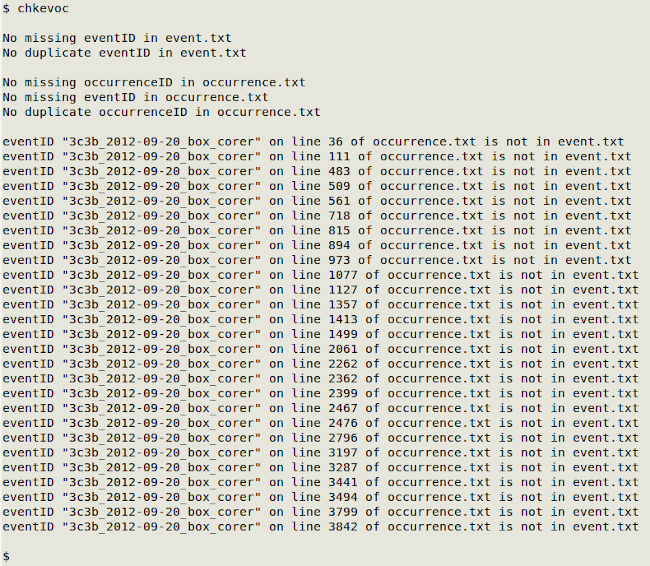
And from a real-world pair of tables (with thousands of records) from my data auditing work:
The script below was cobbled together to be functional, not pretty! Explanatory pseudocode follows the script; email me for more information if interested. In practice, the "chkevoc" output is printed to a file.
UPDATE 2021-03-25.The original version of this script only printed the line address of the last record in "occurrence.txt" that had an eventID not found in "event.txt". The updated version (below) lists all such lines.
#!/bin/bash
echo
awk -F"\t" 'NR==1 \
{for (i=1;i<=NF;i++) if ($i ~ /eventID/) pkev=i} \
NR>1 \
{if ($pkev !~ /[[:alnum:]]/) \
{mee=1; print "eventID missing on line "NR" of event.txt"} \
{pke[$pkev]++; pkedupe[$pkev][NR]}} \
END {PROCINFO["sorted_in"]="@ind_str_asc"; \
if (mee==0) print "No missing eventID in event.txt"; \
for (i in pke) {for (j in pkedupe[i]) {if (pke[i]>1) \
{dupev=1; print " duplicated eventID \"" i "\" on line " j " of event.txt"}}} \
if (dupev==0) print "No duplicate eventID in event.txt"}' \
event.txt
echo
awk -F"\t" 'NR==1 \
{for (r=1;r<=NF;r++) {if ($r ~ /eventID/) fkoc=r; \
else if ($r ~ /occurrenceID/) pkoc=r;}} \
NR>1 \
{if ($pkoc !~ /[[:alnum:]]/) \
{moo=1; print "occurrenceID missing on line "NR" of occurrence.txt"}} \
{if ($fkoc !~ /[[:alnum:]]/) \
{meo=1; print "eventID missing on line "NR" of occurrence.txt"}} \
{pko[$pkoc]++; pkodupe[$pkoc][NR]} \
END {PROCINFO["sorted_in"]="@ind_str_asc"; \
if (moo==0) print "No missing occurrenceID in occurrence.txt"; \
if (meo==0) print "No missing eventID in occurrence.txt"; \
for (m in pko) {for (n in pkodupe[m]) {if (pko[m]>1) \
{dupoc=1; print " duplicated occurrenceID \"" m "\" on line " n " of occurrence.txt"}}} \
if (dupoc==0) print "No duplicate occurrenceID in occurrence.txt"}' \
occurrence.txt
echo
awk -F"\t" 'ARGIND==1 && FNR==1 \
{for (s=1;s<=NF;s++) if ($s ~ /eventID/) pk=s} \
ARGIND==1 && FNR>1 \
{ev[$pk]} \
ARGIND==2 && FNR==1 \
{for (t=1;t<=NF;t++) if ($t ~ /eventID/) fk=t} \
ARGIND==2 && FNR>1 && !($fk in ev) \
{miss=1; print "eventID \""$fk"\" on line "FNR" of occurrence.txt is not in event.txt"} \
END {if (miss != 1) \
print "All eventID in occurrence.txt are in event.txt"}' \
event.txt occurrence.txt
echo
exit
event.txt:
- Get the field number for the eventID field from the header line. The search is with "~" rather than "==" because fieldnames sometimes have leading or trailing spaces.
- In all subsequent records, check that eventID is alphanumeric. If not (blank, or with just spaces or punctuation), set the flag "mee" and print a message that the eventID entry on that line is missing.
- Build an array with eventID as index string to count occurrences of each entry.
- Build an array-of-arrays with eventID and line number as index strings.
- In an END statement
(a) use a PROCINFO setting to sort array index strings alphabetically
(b) check if the flag "mee" is set. If not, print a message that no eventID entries are missing
(c) walk through the array of arrays and check if any of the index strings appears more than once. If so, set the flag "dupev" and print a message with the duplicated entry and its line number. If "dupev" isn't set, print a message that there are no duplicate eventID entries.
occurrence.txt:
- Same procedure as for event.txt, but check both eventID and occurrenceID for missing entries, and occurrenceID for duplicates.
event.txt and occurrence.txt:
- Processing event.txt, get the eventID field number from the header line and build an array from subsequent records with eventID entries as index strings.
- Processing occurrence.txt, first get the eventID field number from the header line.
- Next, for all subsequent lines, check to see if the eventID is in the array from event.txt. If it isn't, set the flag "miss" and print a message with the missing eventID and its line number.
- In an END statement, check to see if "miss" isn't set. If it isn't, print a message that all eventID entries in occurrence.txt are also in event.txt.
Last update: 2021-03-03
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License