
Structure
Kill the carriage returns
Missing-but-expected fields
Empty fields
Empty records
Broken records
Kill the carriage returns
Carriage returns are invisible characters that nowadays mainly appear in files from Windows computers. The reason is that Microsoft ends a line in a text document with two invisible characters, a carriage return (CR) and a linefeed (LF), CRLF. Mac and Linux both end a line with just the linefeed character, LF.
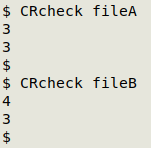
Carriage returns can cause serious errors in data processing, even with many Windows programs. Before you do further checking of a Darwin Core table, you should get rid of any CRs. The CRcheck function first counts all the CRs, and then all the CRs that are part of a CRLF end-of-line. If the two counts are the same, then all the CRs are at the ends of lines. If the first count is bigger, then there are also CRs inside a record or records. Below I show versions of CRcheck for PCRE-enabled grep and older grep:
CRcheck() {
grep -oP "\r" "$1" | wc -l && grep -oP "\r$" "$1" | wc -l
}
CRcheck() {
grep -o $'\r' "$1" | wc -l && grep -o $'\r'"$" "$1" | wc -l
}
Here are two small text files with invisible CRs. They look identical:
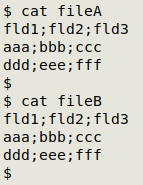
CRcheck shows the two files are different. "fileA" has only end-of-line CRs (one for each of the three lines), while "fileB" also has one internal CR:
The tr utility will delete all the CRs in "fileA":
tr -d '\r' < fileA > fileA-1
However, it's worth checking to see where an internal CR is hiding. It might need replacing with another character rather than just deleting. To locate an internal CR, first delete the end-of-line ones with sed, then use cat and grep to visualise the internal ones as "^M" and give their line numbers:
sed 's/\r$//' [filename] | cat -v | grep -n "\^M"

In this case the one internal CR is at the beginning of line 2 in "fileB". Deleting all the CRs with tr won't create problems. In the real-world example shown below, there were two internal CRs in the CSV "col", both on line 67893. Rather than delete them, I replaced each CR with a single space using sed, but I could also have done the replacing in a text editor.
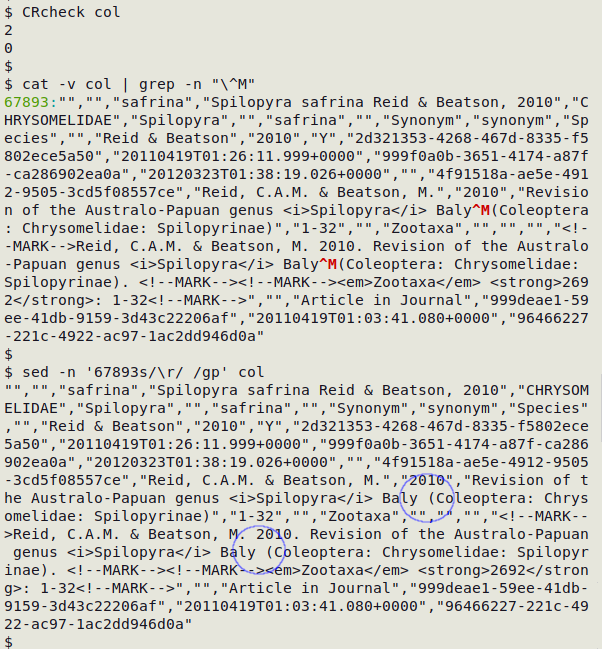
Missing-but-expected fields
Look through the list of fields in the Darwin Core table. Are there fields missing that should be there? Some missing fields may have been empty and were discarded when checking table structure.
GBIF recommends these fields for occurrence tables (from this GBIF webpage):
Required
basisOfRecord
eventDate
occurrenceID
scientificName
Strongly recommended
coordinateUncertaintyInMeters
countryCode
decimalLatitude &decimalLongitude
geodeticDatum
individualCount, organismQuantity & organismQuantityType
kingdom
taxonRank
GBIF recommends these fields for event tables (from this GBIF webpage):
Required
eventDate
eventID
samplingProtocol
samplingSizeValue & samplingSizeUnit
Strongly recommended
coordinateUncertaintyInMeters
countryCode
decimalLatitude & decimalLongitude
geodeticDatum
footprintWKT
locationID
occurrenceStatus
parentEventID
samplingEffort
A missing-but-expected field I sometimes see (miss!) in an measurementorfact.txt table is measurementID. This field should be included so that individual measurement records can be identified.
Another group of missing-but-expected fields are the fields corresponding to verbatim... fields. Important ones:
If there is | there should also be
verbatimEventDate | eventDate
verbatimTaxonRank | taxonRank
verbatimDepth | minimumDepthInMeters and maximumDepthInMeters
verbatimElevation | minimumElevationInMeters and maximumElevationInMeters
verbatimLatitude | decimalLatitude
verbatimLongitude | decimalLongitude
Empty fields
A Darwin Core table might have a complete header but have only blank data items in some fields. These fields aren't completely empty because they have a field name in the header, so they're "pseudo-blank". The empties script will identify any pseudo-blank fields and list them with their field numbers in a new file, [filename]_emptyfields. It also offers the option of building a new table without the pseudo-blank fields. This is very useful if there are a lot of empty fields, because field-by-field processing time will be much faster without those pseudo-blanks.
Here empties works on the file "occ1", and the first five of the 43 empty fields are shown from "occ1_emptyfields":
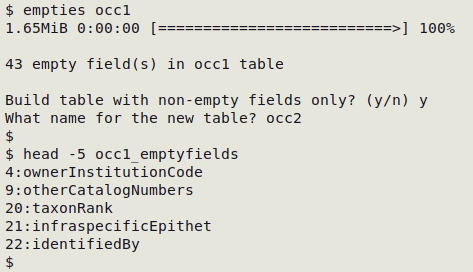
An alphabetically sorted, comma-separated line of the empty fields can be built with this command:
cut -d":" -f2 [filename]_emptyfields | sort | tr '\n' ',' | sed 's/,$/\n/'
Empty records
Blank records are fairly rare in Darwin Core tables, but they should be deleted if they occur because they have no useful data and will confuse the line numbering. The following command will find any records that do not contain letters or numbers, and will also print their line numbers.
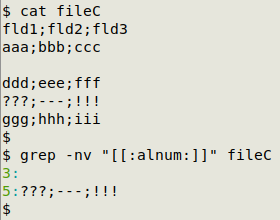
grep -nv "[[:alnum:]]" [filename]
In the screenshot below, "fileC" has one entirely blank line (line 3) and one line with only punctuation (line 5):
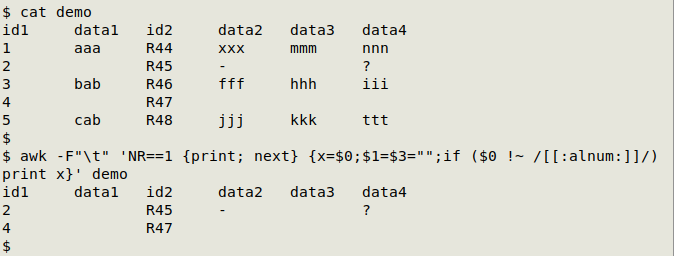
Another kind of blank record has unique ID fields filled in, but no other information (letters or numbers). In the screenshot below, the TSV "demo" has two ID fields and four data fields. The "demo" records with no data except ID codes can be found with this command:
awk -F"\t" 'NR==1 {print; next} {x=$0;[ID field or fields]="";if ($0 !~ /[[:alnum:]]/) print x}' [filename]
Broken records
In a Darwin Core table with N fields, every record should have exactly N fields. A record with more or fewer than N fields is broken and needs fixing before any further data checking or cleaning is done.
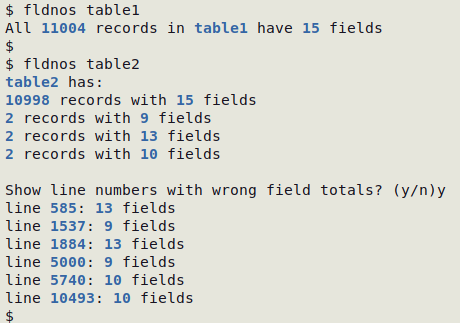
The interactive script fldnos works with any number of records in a TSV. In the screenshot below, "table1" is OK and "table2" is not OK:
There are command-line ways to repair records with the wrong number of fields (see here), but I find it quicker and easier to use a text editor.