
For a list of BASHing data 2 blog posts see the index page. ![]()
Finding near-duplicate spelling variants
This week's post follows on from an earlier one where I looked for near-duplicates like "a4" and "a-4" in a large table. This time I was looking for spelling variants of a certain kind, namely the "ASCII-ised" versions of non-ASCII characters like ü and ß as ue and ss.
Both the original and ASCII versions of such a string might be anywhere in a long list of strings in a particular field in a large table. What I wanted to generate was grouped non-ASCII and ASCII strings, together with the unique ID for the record containing each.
That will be clearer if I give a simplified example. The table below ("table") has four fields. Field 1 has a unique ID for each record, and field 3 contains strings which may or may not have original and ASCII versions of particular strings, like "bär" and "baer":
fld1,fld2,fld3,fld4
001,Xa1,ess,dei
002,oHa,öls,zee
003,OoV,baer,che
004,noh,baer,iib
005,ho7,müh,iTi
006,dai,sew,moo
007,weY,eß,cho
008,Ahs,öls,ein
009,Moh,elf,aiY
010,jo7,zip,ig8
011,eej,bär,Pha
012,ohh,iff,boL
013,ohw,aff,een
014,voo,rag,aev
015,xa8,aff,Oos
016,oof,sew,ahS
017,aez,oels,Ang
And here's the output I want:
013,aff #Latin small ligature "ff", U+FB00
015,aff
003,baer
004,baer
011,bär
001,ess
007,eß
002,öls
008,öls
017,oels
KLUDGE ALERT Readers are warned that the following hack is ugly and long-winded. Can you think of a shorter, more elegant solution? Email me and I'll update this post (and credit you, if you wish).
To do this job I'll first build a comma-separated look-up table ("forms") with eight pairs of original and ASCII character versions that might be present in my file of interest:
ä,ae
ö,oe
ü,ue
æ,ae
œ,oe
ff,ff
fl,fl
ß,ss
I'm only interested in fields 1 and 3 in "table", so I'll cut them out:
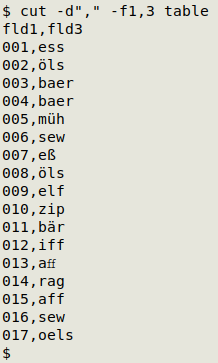
Next I'll use an AWK command to add a third field containing either the ASCII data items in field 2 (unmodified), or the ASCII versions of non-ASCII strings. (Explanation below.)
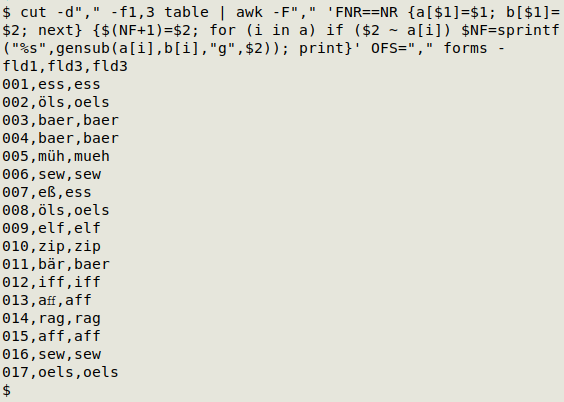
I sort the 3-field table to get the ordering I want, by 3rd-field string and 1st-field code.
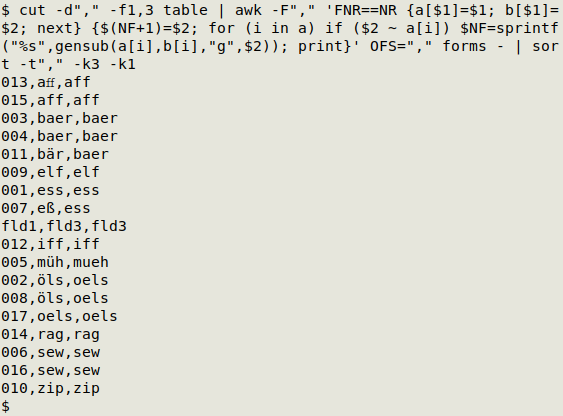
Another AWK command next, this time to space the groups by 3rd-field entry. (Explanation below.)
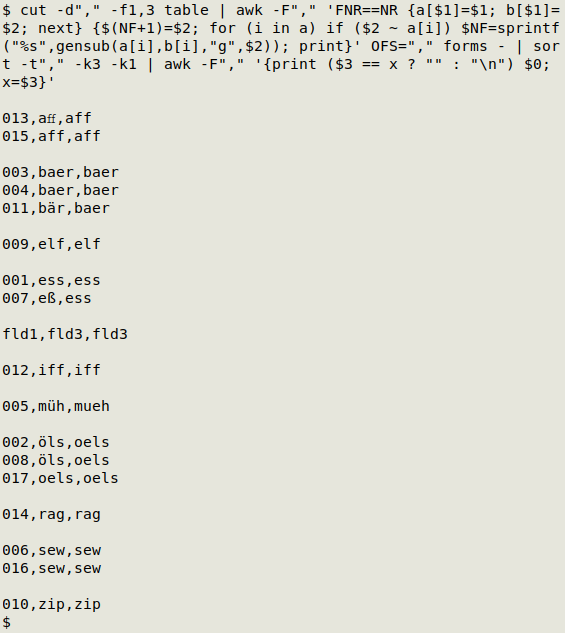
Now for a final AWK command to filter the output, retaining only multi-line groups with a non-ASCII character somewhere inside. (Explanation below.) The header line is excluded automatically when I do this.
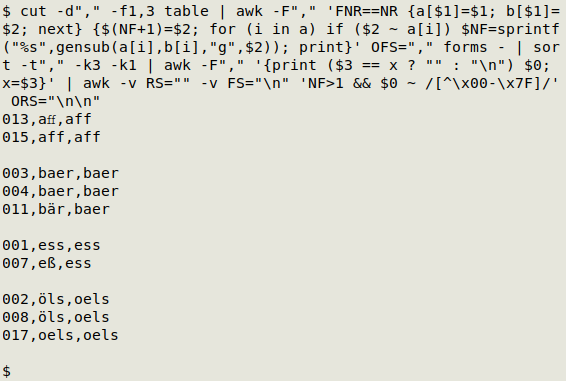
The last step is to delete that 3rd field.
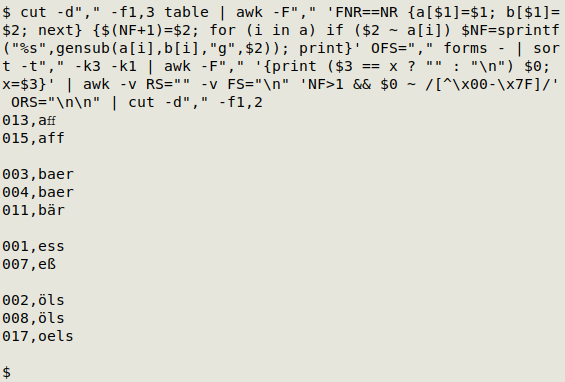
The six commands I chained together are shown here and explained below:
cut -d"," -f1,3 table | awk -F"," 'FNR==NR {a[$1]=$1; b[$1]=$2; next} {$(NF+1)=$2; for (i in a) if ($2 ~ a[i]) $NF=sprintf("%s",gensub(a[i],b[i],"g",$2)); print}' OFS="," forms - | sort -t"," -k3 -k1 | awk -F"," '{print ($3 == x ? "" : "\n") $0; x=$3}' | awk -v RS="" -v FS="\n" 'NF>1 && $0 ~ /[^\x00-\x7F]/' ORS="\n\n" | cut -d"," -f1,2
In a real-world case, "table" and "forms" were tab-separated, "forms" had a longer list of pairs and I retained two fields besides the UI field and the field of interest. On my desktop, the command chain took 6 seconds to process 367185 records. Below are a couple of examples of what I found after export to a text file, with tabs replaced by space-pipe-space:

First AWK command:
awk -F"," 'FNR==NR {a[$1]=$1; b[$1]=$2; next} {$(NF+1)=$2; for (i in a) if ($2 ~ a[i]) $NF=sprintf("%s",gensub(a[i],b[i],"g",$2)); print}' OFS="," forms -
AWK first builds two arrays from "forms", both indexed by the non-ASCII character. Array "a" has the non-ASCII character as its value string, and array "b" has the character's ASCII version.
AWK now moves on to the cut "table", represented in the argument string by "-". First AWK duplicates field 2 as field 3: field 2 was the last field, $NF, and the new third field is $(NF+1). Next it looks to see if field 2 matches any of the index strings in array "a". If there's a match, then AWK replaces the non-ASCII character (a[i]) in field 2 with its ASCII version (b[i]) and prints the result in the new last field ($NF), field 3. The result is that field 3 contains only ASCII versions of the field 2 items.
Second AWK command:
awk -F"," '{print ($3 == x ? "" : "\n") $0; x=$3}'
At each line, AWK checks to see if the 3rd field equals "x". If that's true, AWK prints an empty string (nothing). If not true, AWK prints a newline, creating a space between groups. In both cases AWK prints the whole line and re-sets "x" to equal the current line's 3rd field. Since "x" is undefined for the first line, AWK prints the line. The result is neat spacing by 3rd-field group, but note that this command requires that field 3 is sorted.
Third AWK command:
awk -v RS="" -v FS="\n" 'NF>1 && $0 ~ /[^\x00-\x7F]/' ORS="\n\n"
AWK here views the output from the last command as one record per space-separated group, with each line in the group being a field. It filters the records so that the only ones printed have more than one field and also a non-ASCII character. The spacing between records is re-set to two newlines.
Last update: 2024-04-05
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License