
For a list of BASHing data 2 blog posts see the index page. ![]()
Finding identifier codes with and without extra characters
Think of the list below ("file") as a field from a merger of data tables. One table had identifier codes in the format [letter][number], while the other had [letter]-[number]. You can see there are "near-duplicate" codes, like "a4" and "a-4". How to find all those near-duplicate pairs?
b2
d-5
a-4
a2
c6
d4
c4
d-3
d6
a3
b5
b7
d5
a4
c1
d2
d-2
a5
a-6
d1
You could do that job by eye with the list above, but I was working recently with a table with ca 270 000 different identifier values, and I needed a command-line solution. I chose
paste file <(sed 's/-//' file) | sort -r | awk -F"\t" 'a[$2]++' | sort

The first command pastes together the original list and the same list with hyphens deleted by sed, with the two lists tab-separated:
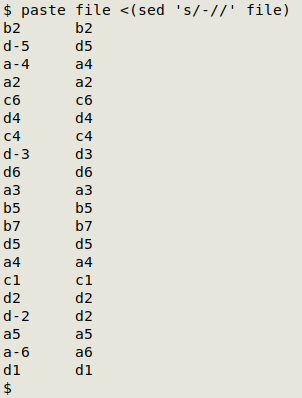
The next command takes advantage of an interesting feature of the GNU sort command. Watch what happens here:

Notice the sorting isn't character-by-character. If it was, the two "a-" strings would be grouped together. In my command-line solution I reversed the sort order with the -r option:
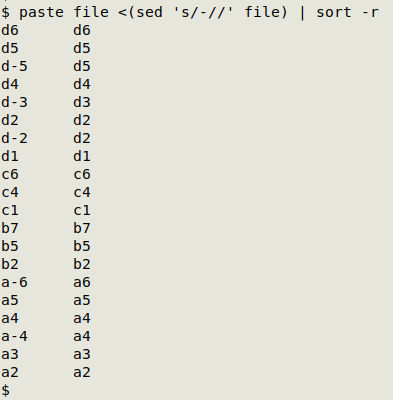
Now as you go down the first field (the original list, sorted in reverse order), the first occurrence of a near-duplicate is [letter][number], followed by its [letter]-[number] version.
The next command uses GNU AWK with the field separator specified as a tab. The AWK command consists entirely of a condition, with the default action being to print any lines that match that condition. The condition is a[$2]++. As an array value, that would be a count of the number of occurrences of each of the unique entries in field 2. Here, as a condition, it simply asks "Is this value already in the array?". If yes, the condition is TRUE.
As AWK works through the 2-field list it notes for the first time at line 3 that yes, it's seen the entry "d5" in field 2 before (on line 2), so it prints line 3, which contains the near-duplicate pair "d-5" and "d5". Printing happens again for lines 7 and 18.
The final command is a sort of the AWK output, for tidiness.
Last update: 2024-02-02
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License