
For a full list of BASHing data blog posts see the index page. ![]()
How to find almost-duplicates
Update. For an important update on this topic, please see this BASHing data post.
A Data Cleaner's Cookbook explains how to find partial duplicates in a data table using an AWK array.
Here's an example using the tab-separated table "demo" (copy/paste-able as TSV):
| Fld1 | Fld2 | Fld3 | Fld4 | Fld5 | Fld6 | Fld7 | Fld8 |
| 001 | 7b03 | 020d | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 002 | 521a | 1da1 | f9eb | 4268 | 9fa8 | fc7357 | 0a31b8 |
| 003 | e6c3 | 0e9b | dc9f | 448b | b1c4 | 7705ca | 772ab5 |
| 004 | 36cf | fd59 | 0c62 | 4eb6 | 82d1 | e30076 | ecedbd |
| 005 | 15c5 | 7874 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 006 | b3fb | 5bad | 3361 | 4259 | a5b0 | 30370c | 953333 |
| 007 | 15c5 | c3d5 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 008 | 7b03 | 7686 | d264 | 4c34 | b0e4 | 364607 | 5af668 |
| 009 | 7ee1 | 8a53 | 5cc5 | 4f57 | 9cf5 | ddc735 | 56eee8 |
| 010 | bd75 | 3324 | 21mz | 41b0 | b1bc | 22964a | b9f2a3 |
| 011 | 15d7 | 1fb2 | 7223 | 4e8f | 8f1f | 8e6b76 | f60cd1 |
| 012 | c3cc | ef6c | 70fb | 4a45 | 9428 | f00f73 | 07e92d |
| 013 | 9ab4 | 991c | 0bd7 | 4f3c | badf | ee145b | 5a6d17 |
| 014 | 6ad5 | 8395 | 19aa | 43c4 | 9cea | 3a3c90 | e84150 |
| 015 | 607c | 3753 | 8a69 | 44bf | b41f | ddb1eb | 4a42ff |
| 016 | 7b03 | f067 | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 017 | 05f1 | 89f3 | 5067 | 6712 | b1c4 | 3b5245 | 4c4e35 |
| 018 | e20d | 5346 | 71a8 | 4b26 | a31d | ab914d | e39049 |
| 019 | 15c5 | 52bd | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 020 | e917 | b879 | 08dd | 4387 | b520 | 814a8a | 10717b |
Fields 1 and 3 of "demo" contain only unique values. Ignoring those two fields, are there any duplicate records in the table? The Cookbook-style command would be:
awk -F"\t" 'FNR==NR {a[$2,$4,$5,$6,$7,$8]++; next} a[$2,$4,$5,$6,$7,$8]>1' demo demo | sort -t $'\t' -k2 -nk1

Fields in "demo" are tab-delimited (-F"\t"). The FNR==NR condition tells AWK to do the first action on the first file, "demo", and the second action on the second file, also "demo", as explained here.
In the first action, the array "a" is filled using the strung-together fields 2 and 4-8 as index strings (a[$2,$4,$5,$6,$7,$8]), and the count of each unique combination of fields as value string (++). After each line has its fields added to the array (or merely counted if already in the array), AWK moves to the next line (next).
In the second action, AWK checks the value string for the array member corresponding to the fields in the current line. If the value is greater than 1 (meaning there's a duplicate), the line is printed, which is AWK's default action.
All the almost-duplicate lines found by AWK are passed to sort, which in this case sorts first by the second tab-separated field (field 2), then by the serial number in field 1.
It works, but there's a convenience issue here. I had to write out all the fields except 1 and 3 for the array index. Wouldn't it be simpler to write something like this?
{a[expression for all fields except $1 and $3]++; next} ...
It would be simpler, but unfortunately there's no such expression in GNU AWK. You can't invert a selection of fields. In a recent data audit the issue loomed a lot bigger for me than it does in "demo": there were two unique-entry fields and 139 others, and I was looking for the "almost-duplicates" in the 139 non-unique-entry fields! (See the end of this post.)
It's easy enough to determine whether "almost-duplicates" actually exist in a table using cut, sort and uniq. Here's that process using "demo":
cut -f1,3 --complement demo | sort | uniq -D
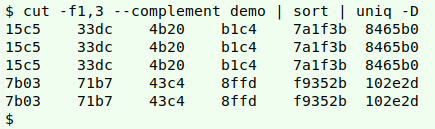
Unfortunately this method doesn't return the whole record, so you don't know where in the table these "almost-duplicates" are lurking.
An interesting workaround is based on replacing the unique-entry field contents with the "zero or more of any one character" regex expression ".*", then getting a list of duplicate records, uniquifying it and searching for the unique records in the original table. As with the AWK array method, two passes through the table are required.
In the first pass through "demo", AWK does the replacement of field 1 and field 3 contents with ".*". The result is piped to sort and uniq, with uniq's -d option returning just one example of each of the duplicates:
awk 'BEGIN {FS=OFS="\t"} NR>1 {$1=$3=".*"; print}' demo | sort | uniq -d
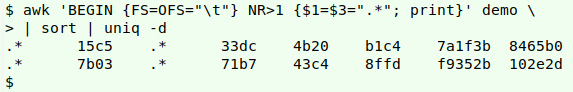
AWK needs to be told that both the input and output field separator is a tab (BEGIN {FS=OFS="\t"}) because each line will be rebuilt in the action part of the command. The action applies to lines after the header (NR>1) and consists of setting the values of fields 1 and 3 to the string ".*", then printing the line.
The "-d" option for uniq isn't as familiar to many users as the "-D" option. "-D" prints all duplicate lines (only). "-d" also prints only duplicate lines, but only one example from each group of duplicates.
Now to search for the two records above, which have the regex expression ".*" in place of unique field 1 and field 3 entries. I can do that either with grep -f, using as a reference file a redirection from the first pass, or with a while loop to read the redirection one line at a time and pass it to AWK for matching in "demo":
grep -f <(awk 'BEGIN {FS=OFS="\t"} NR>1 {$1=$3=".*"; print}' demo | sort | uniq -d) demo | sort -t $'\t' -k2 -nk1
while read line; do awk -v FIND="$line" '$0 ~ FIND' demo; done < <(awk 'BEGIN {FS=OFS="\t"} NR>1 {$1=$3=".*"; print}' demo | sort | uniq -d) | sort -t $'\t' -k2 -nk1
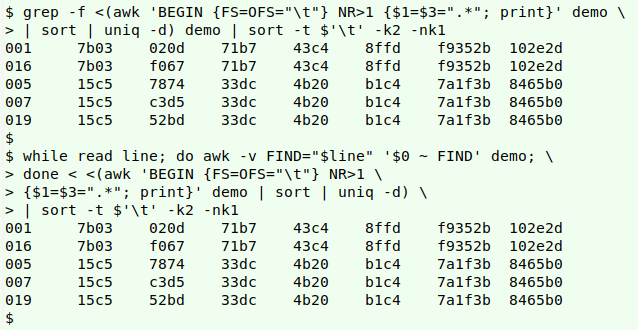
In the while loop command, each line in the list of duplicates is fed to AWK as the shell variable "$line" and replaced with the AWK variable FIND (-v FIND="$line"). As AWK goes through "demo" line by line, it checks to see if the current line is a regex match for the line from the list of duplicates ($0 ~ FIND), and if it is, the current line is printed. Each of the unique entries in fields 1 and 3 is matched by ".*".
Both these methods work, but they fail spectacularly if there are any strings in the "almost-duplicates" lines that grep or AWK can interpret as regex (other than ".*"). There aren't any such strings in "demo", but there were lots in my audit table, and I had to fall back on the array method (see top of page). The array was indexed with
$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12,$13,$14,$15,$16,$17,$18,$19,$20,
$21,$22,$23,$24,$25,$26,$27,$28,$29,$30,$31,$32,$33,$34,$35,$36,$37,
$38,$39,$40,$41,$42,$43,$44,$45,$46,$47,$48,$49,$50,$51,$52,$53,$54,
$55,$56,$57,$58,$59,$60,$61,$62,$63,$64,$65,$66,$67,$68,$69,$70,$71,
$72,$73,$74,$75,$76,$77,$78,$79,$80,$81,$83,$84,$85,$86,$87,$88,$89,$90,
$91,$92,$93,$94,$95,$96,$97,$98,$99,$100,$101,$102,$103,$104,$105,
$106,$107,$108,$109,$110,$111,$112,$113,$114,$115,$116,$117,$118,
$119,$120,$121,$122,$123,$124,$125,$126,$127,$128,$129,$130,$131,
$132,$133,$134,$135,$136,$137,$138,$139
where the excluded unique-entry fields were 1 and 82. AWK processed the audit table (139 fields, 810000+ records) in less than 15 seconds on my desktop PC (quad core i5, 8G RAM).
The index string formula for the array comes from echo "\$$(seq -s ",$" 139)", from which I manually deleted "$1," and "$82,".
Last update: 2021-12-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License