
For a full list of BASHing data blog posts see the index page. ![]()
A muggle's guide to AWK arrays: 2
Part 1 of this series looked at a couple of AWK array basics, namely index strings and value strings. This post deals with a very common use of AWK arrays, namely filtering or modifying a file based on information in another file.
Getting multiple files into a single AWK command. AWK commands typically have the form
awk 'pattern {action}' file
and AWK will only carry out the action on a line in the file if the line matches the pattern.
Further, AWK can process more than one file in a single command. It processes the first file given as an argument, then smoothly moves on to the second file and so on:
awk '[some command in here]' file1 file2...
These two rules can be combined to get AWK to build an array from one file, then use the array in a pattern for action on the second file. The standard way of doing this looks like:
awk 'FNR==NR {build an array from file1; next} \
pattern involving array {action on file2}' file1 file2
It's a command structure that puzzles some AWK users so I'll break it down. There are two action/pattern parts to this command. The pattern in the first part is FNR==NR. FNR is a built-in AWK variable that counts the number of lines processed in the currently viewed file. NR counts the total number of lines that AWK processes in the whole command no matter how many files are listed as arguments.
Suppose "file1" has 3 lines and "file2" has 4 lines. Here are the running tallies of FNR and NR as AWK processes first "file1", then "file2":
FNR NR
1 1 file1 being processed FNR equals NR
2 2 file1 being processed
3 3 file1 being processed
1 4 file2 being processed FNR no longer equals NR
2 5 file2 being processed
3 6 file2 being processed
4 7 file2 being processed
AWK starts off processing the first line in "file1". It checks for the pattern FNR==NR and as you can see in the table above, FNR does equal NR for that first line of "file1". The first action can proceed, which is to build an array based on the contents of that first line, then jump to the next line without doing anything else in the command (next).
The same happens with line 2 and line 3. When AWK runs out of lines in "file1", it smoothly moves to "file2" and starts processing the pattern, but FNR==NR no longer applies. FNR is 1 but NR is 4 and the {build array; next} action doesn't happen. Instead AWK moves to the second part of the command and processes the first line in "file2" (and subsequent lines) according to the pattern/action pattern involving array {action on file2}.
Is something from file1 in file2? This is a grep-like use of AWK, similar to a grep -f command. AWK is much faster than grep with big files, however, as demonstrated in an earlier BASHing data post. Here are two small demonstration files:
file1:
Denmark
Finland
Iceland
Norway
Sweden
file2 (tab-separated):
| Country | Population | Land Area (sq km) |
| Germany | 82438639 | 348560 |
| United Kingdom | 66959016 | 241930 |
| France | 65480710 | 547557 |
| Italy | 59216525 | 294140 |
| Spain | 46441049 | 498800 |
| Ukraine | 43795220 | 579320 |
| Poland | 38028278 | 306230 |
| Romania | 19483360 | 230170 |
| Netherlands | 17132908 | 33720 |
| Belgium | 11562784 | 30280 |
| Greece | 11124603 | 128900 |
| Czechia | 10630589 | 77240 |
| Portugal | 10254666 | 91590 |
| Sweden | 10053135 | 410340 |
| Hungary | 9655361 | 90530 |
| Belarus | 9433874 | 202910 |
| Austria | 8766201 | 82409 |
| Serbia | 8733407 | 87460 |
| Switzerland | 8608259 | 39516 |
| Bulgaria | 6988739 | 108560 |
| Denmark | 5775224 | 42430 |
| Finland | 5561389 | 303890 |
| Hungary | 9655361 | 90530 |
| Belarus | 9433874 | 202910 |
| Austria | 8766201 | 82409 |
For the question "Are any of the countries in file1 included in file2?" the command is:
awk -F"\t" 'FNR==NR {a[$0]; next} $1 in a' file1 file2
Here the first action builds an array "a" from "file1" using the whole line ($0) as an index string. No value string is defined, so the value strings are empty. In the second part of the command (which only works on "file2") the pattern is $1 in a, which means The string in field 1 of "file2" is also an index string in array "a". No action is specified, so by default AWK prints any line in "file2" that matches the pattern. The results will be in country order as found in "file2":

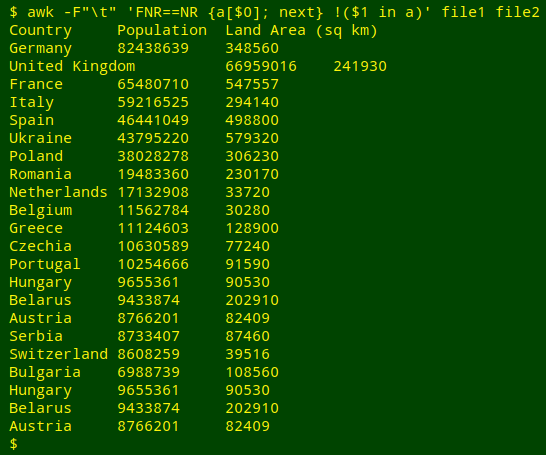
I can also get the lines from "file2" where field 1 is not an index string in the array, by writing !($1 in a) as the pattern:
awk -F"\t" 'FNR==NR {a[$0]; next} !($1 in a)' file1 file2
1 file, 2 passes. You can give AWK the same file twice as separate arguments. That means you can process a file once to build an array, then go through the same file a second time to do something with the information stored in the array:
awk 'FNR==NR {build an array from file; next} \
pattern involving array {action on file}' file file
In a 2018 BASHing data post I showed how this trick was ideal for finding partial duplicates. For example, in the tab-separated file "table" you could look for records in which fields 2,5 and 8 were duplicated:
awk -F"\t" 'FNR==NR {a[$2,$5,$8]++; next} a[$2,$5,$8]>1' table table
In the first pass, AWK builds an array "a" from "table" using a combination of fields 2, 5 and 8 as an index string, and keeps a count (++) of the unique 2-5-8 combinations. In the second pass, AWK checks the array to see if the value string in "a" (the count from the first pass) is greater than one for fields 2, 5 and 8 in the current line. If yes, that line is printed.
The commas separating the fields in the index string tell AWK to use its own, hidden separator (it's the character with hex value 1c) to link the field 2, field 5 and field 8 strings. We don't need to know what that separator is, because the same separator is also used in the second part of the command to link field contents. You could make the separator explicit, if you wanted, for example by building "a" as a[$2 FS $5 FS $8]++ or a[$2":"$5":"$8]++. Commas are simpler.
Last update: 2019-07-12
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License