
For a full list of BASHing data blog posts, see the index page. ![]()
A muggle's guide to AWK arrays: 1
If (like me) you don't have a degree in computer science and haven't done a lot of programming, you might have the impression that AWK arrays are highly technical things best left for AWK wizards to play with.
I'd agree that AWK arrays can be a little intimidating, but they're very, very useful. In this series of occasional blog posts I hope to make arrays less scary for AWK users. I'll assume that readers already know the basics of AWK syntax and uses, but haven't had much to do with AWK arrays. (Tutorials Point has a nice series of webpages introducing AWK.)
An AWK array and its parts. An AWK array is a collection of key/value pairs. Both the keys and the values are strings, where "string" means any combination of letters, numbers, spaces and punctuation.
The key in an AWK array is called an "index" and every index is unique — there are no duplicate keys in the array.
There are no special requirements for the values in an AWK array. The values can be duplicated (same value for more than one index), or can even be empty strings (blanks).
An AWK array is an unstructured and invisible collection of index/value pairs. It is not a list of pairs or a table of pairs. It's a collection of one-to-one relationships. You can't make those relationships visible with a simple command like "print array". If you like, though, you could imagine that a 5-pair array looks like this:
index3 value-associated-with-index3
index1 value-associated-with-index1
index4 value-associated-with-index4
index5 value-associated-with-index5
index2 value-associated-with-index2
Notice that I haven't put my imaginary list of index/value pairs in numerical order. That's because the index/value pairs in an AWK array aren't sorted. There are ways to sort an array, however, as we'll see later in this series.
How to build an array and see what's in it. Here's a comma-separated table called "table1":
Runs,Against
248,Bangladesh
241,Australia
217,New Zealand
214,Australia
203,Sri Lanka
201,Zimbabwe
194,Pakistan
193,England
179,West Indies
177,England
Cricket-lovers might guess what this is. The table has the 10 highest single-innings runs totals achieved by Sachin Tendulkar during his international Test career.
To build an array from "table1", all I have to do is give the array a name and tell AWK to find the index strings within the square brackets immediately following the array name. For example, I can build the array named "a" indexed with strings from field 2 ("Against") just by writing a[$2] as an AWK command, although I first need to tell AWK that the fields in "table1" are comma-separated (-F","):
awk -F"," '{a[$2]}' table1
Well, that's nice, but I can't see what was in my array "a" because arrays, as mentioned earlier, are invisible collections of relationships.
One way to look inside an array is to scan it with a loop. I'll do that after the array has finished building, in an END statement. For every index string "i" in the array "a", AWK will print "i":
awk -F"," '{a[$2]} END {for (i in a) print i}' table1
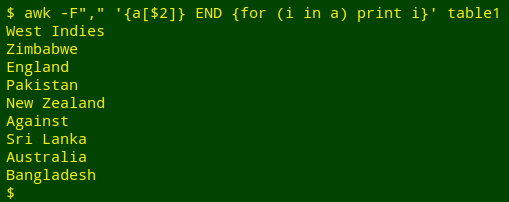
So the array "a" has 9 index strings, one for each of the 9 unique strings in field 2. I don't really want the "Against" string from the header line, so I'll add NR>1 as a condition for building the array. The array will now only be built using lines after the header, and will have 8 unique index strings:
awk -F"," 'NR>1 {a[$2]} END {for (i in a) print i}' table1
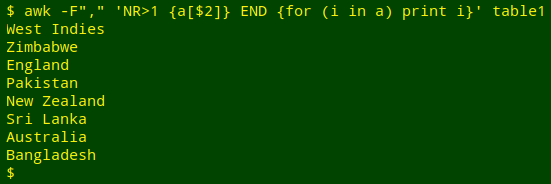
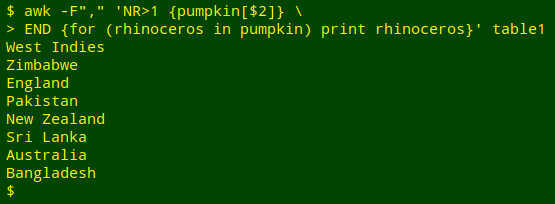
I've used "a" for the array name and "i" for the variable in the loop because that's my habit. The strings "a" and "i" are just labels. I get the same output if I use "pumpkin" for the array name and "rhinoceros" for the variable:
awk -F"," 'NR>1 {pumpkin[$2]} END {for (rhinoceros in pumpkin) print rhinoceros}' table1
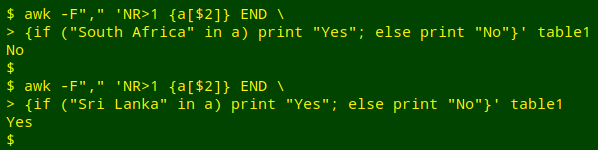
Another way to see what's in the array's collection of index strings is to look for particular items. Again in an END statement, I can ask AWK to print "Yes" if a particular string is an index in "a", and "No" if it isn't:
awk -F"," 'NR>1 {a[$2]} END {if ("[string]" in a) print "Yes"; else print "No"}' table1
Adding values to an array. At the start of this post I described an AWK array as a collection of index/value pairs, but so far we haven't seen any values, just index strings. The values in the array a[$2] were, in fact, empty strings. When you build an array without telling AWK how to get values, it assigns an empty string as the value for each index.
To add values to an array, write an instruction immediately after the square brackets that contain the source of the index strings. One such instruction is "++", as in a[$2]++. This tells AWK that the value associated with each index string is the number of times that index string appeared as the array was built. To see the "++" values for array "a", I'll put a loop in an END statement and tell AWK to print not only the index string for each "i", but also the value string for each "i", which is written a[i]:
awk -F"," 'NR>1 {a[$2]++} END {for (i in a) print i, a[i]}' table1
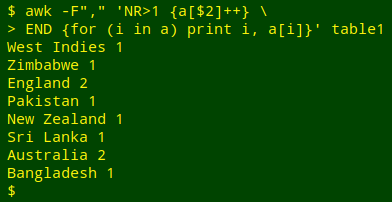
The output is a tally of the country names in field 2, with names and counts (index strings and value strings) separated by a single space (the default AWK separator).
Another instruction for adding values to an array is "=". For example, I can tell AWK with a[$2]=$1 that the values in the array "a" are the contents of field 1 ("Runs"):
awk -F"," 'NR>1 {a[$2]=$1} END {for (i in a) print i, a[i]}' table1
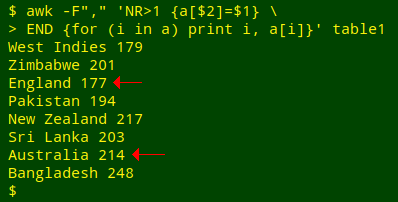
Whoops, that didn't work. Or rather, it only worked for the countries appearing just once in the table. For Australia and England, which each appear twice in "table 1", the runs in the value column are just the last ones that AWK found as it went through the table line-by-line. In other words, AWK refreshed the array with a new value when the index string appeared for a second time.
To get the cumulative total of runs for each country, the correct instruction is "+=". That tells AWK to add the latest value for each index to the already existing value for that index.
awk -F"," 'NR>1 {a[$2]+=$1} END {for (i in a) print i FS a[i]}' table1
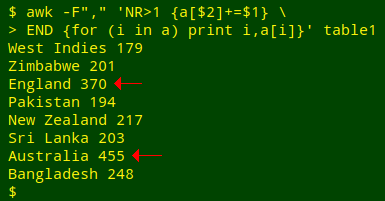
That's better! There are other ways to designate index strings and to add values in an AWK array, and I'll give examples later in this series.
Exercise: grouping and ungrouping with arrays
Here's an unsorted list of Australian plant names, "gensp":
Acacia verticillata
Eucalyptus amygdalina
Acacia melanoxylon
Eucalyptus viminalis
Banksia marginata
Melaleuca ericifolia
Acacia dealbata
Melaleuca squarrosa
Banksia serrata
Eucalyptus obliqua
What I'd like to do is group these names by genus, with the species names in a comma-separated list after the genus name and a colon. The "starting off" command is:
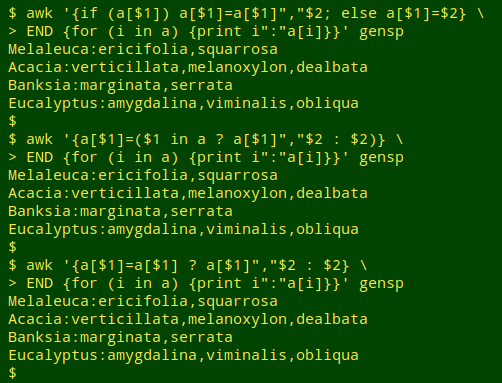
awk '{if ($1 in a) a[$1]=a[$1]","$2; else a[$1]=$2} \
END {for (i in a) {print i":"a[i]}}' gensp
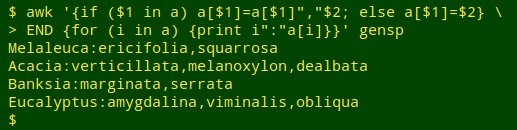
As AWK processes "gensp" line by line, it checks to see whether field 1 (genus) is already an index of array "a" (if ($1 in a)).
Whitespace is the default field separator for AWK, so field 1 in "gensp" is the genus name and field 2 is the species name.
If the genus name is already in array "a", then the value for that index string is redefined as the existing value followed by a comma followed by the contents of field 2 (species) (a[$1]=a[$1]","$2). If field 1 is not already in "a", then a[$1] is given the value found in field 2, the first species name for that genus (else a[$1]=$2).
The END statement goes through the array as usual. First AWK prints the index string, then a colon, then the value for that index.
When the first line is processed, array "a" doesn't exist yet, so the command follows the "else" instruction.
I called this the "starting-off" command because it needs some work to get the names alphabetically sorted. Before I fix that, note that there are other ways to write the same command. Instead of checking, for example, to see if the genus string is an index yet in "a" (if ($1 in a)), I could ask whether a[$1] exists yet (if (a[$1]):
awk '{if (a[$1]) a[$1]=a[$1]","$2; else a[$1]=$2} \
END {for (i in a) {print i":"a[i]}}' gensp
I could also use a C-style conditional expression...
[test for condition] ? [if condition met, do this] : [if condition not met, do this]
...which in this case would look like:
awk '{a[$1]=($1 in a ? a[$1]","$2 : $2)} \
END {for (i in a) {print i":"a[i]}}' gensp
or a bit more cryptically:
awk '{a[$1]=a[$1] ? a[$1]","$2 : $2} \
END {for (i in a) {print i":"a[i]}}' gensp
This uses a coding shorthand. a[$1]=a[$1] is a test to see if a value exists yet for a[$1] in the array "a", which is automatically created when a[$1] is first fed to AWK.
All three variations give the same result as the if/else command:
The simplest way to alphabetise the grouped results is to first sort "gensp", before the file is passed to AWK. That will sort the species names in the output, but not the genus names, so a second sort on the AWK output is needed:
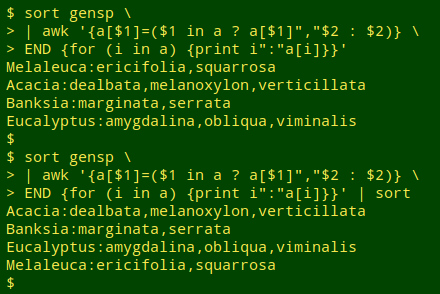
OK, that's the original list transformed into groups the way I wanted. But how could I "ungroup" the output and return to a space-separated list of genus/species names?
With an array. Here's the grouped list as the file named "grouped":
Acacia:dealbata,melanoxylon,verticillata
Banksia:marginata,serrata
Eucalyptus:amygdalina,obliqua,viminalis
Melaleuca:ericifolia,squarrosa
and this command will do the ungrouping:
awk -F":" '{n=split($2,a,","); for (i=1;i<=n;i++) print $1" "a[i]}' grouped
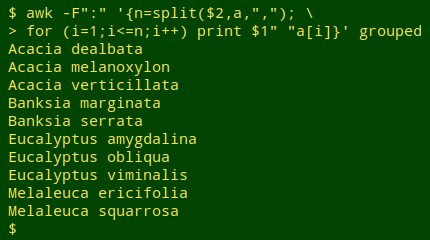
The command uses AWK's split function, which breaks up strings and puts the pieces as values into an array indexed with the numbers 1, 2, 3 etc.
split takes three arguments: the string to be split, the name of an array in which to store the pieces, and the character on which to do the splitting. In the command I've told AWK that the field separator is a colon (-F":"), and the string being split on each line is the comma-separated list of species names after the colon, field 2. The array name is "a" and the character on which to split the string is ",".
In the first line of "grouped", the string to be split is dealbata,melanoxylon,verticillata and the array will contain:
a[1] (the value of the array "a" for index "1") is dealbata
a[2] is melanoxylon
a[3] is verticillata
The split function actually returns a number, namely the number of pieces it puts into the array. In the command I've called this number "n", and for that first line "n" is 3. With the for loop for (i=1;i<=n;i++), AWK goes through the array "a" in numerical order of index from 1 to "n". For each array index, AWK prints the genus name ($1), a space and the array value for that numerical index.
In the second line of "grouped" there are only two species names, so "n" is 2, not 3. Is that a problem? No. The AWK command works line by line. The split command for each line re-builds the array "a" with new index numbers, new values and a new "n", and a new for loop for each line feeds the print instruction.
Last update: 2019-06-07
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License