
For a full list of BASHing data blog posts see the index page. ![]()
Duplicate records differing only in unique identifiers
There's a big data table with lots of fields and lots of records. Each record has one or more unique identifier field entries. How to check for records that are exactly the same, apart from those unique identifiers?
I've been tinkering with this problem for years, and you can read my last, fairly clumsy effort in this BASHing data blog post from 2020. Here I present a much-improved solution, which has also gone into A Data Cleaner's Cookbook as an update.
In 2020, the fastest and most reliable method I used to extract these partial duplicates was with an AWK array and two passes through the table. In the first pass, an array "a" is built with the non-unique-identifier field entries as index string and the tally of each different entry as the value string. In the second pass through the table, AWK looks for records where the value string for the same index string is greater than one, and by default prints the record.
The example table from the 2020 blog post was the TSV "demo":
| Fld1 | Fld2 | Fld3 | Fld4 | Fld5 | Fld6 | Fld7 | Fld8 |
| 001 | 7b03 | 020d | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 002 | 521a | 1da1 | f9eb | 4268 | 9fa8 | fc7357 | 0a31b8 |
| 003 | e6c3 | 0e9b | dc9f | 448b | b1c4 | 7705ca | 772ab5 |
| 004 | 36cf | fd59 | 0c62 | 4eb6 | 82d1 | e30076 | ecedbd |
| 005 | 15c5 | 7874 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 006 | b3fb | 5bad | 3361 | 4259 | a5b0 | 30370c | 953333 |
| 007 | 15c5 | c3d5 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 008 | 7b03 | 7686 | d264 | 4c34 | b0e4 | 364607 | 5af668 |
| 009 | 7ee1 | 8a53 | 5cc5 | 4f57 | 9cf5 | ddc735 | 56eee8 |
| 010 | bd75 | 3324 | 21mz | 41b0 | b1bc | 22964a | b9f2a3 |
| 011 | 15d7 | 1fb2 | 7223 | 4e8f | 8f1f | 8e6b76 | f60cd1 |
| 012 | c3cc | ef6c | 70fb | 4a45 | 9428 | f00f73 | 07e92d |
| 013 | 9ab4 | 991c | 0bd7 | 4f3c | badf | ee145b | 5a6d17 |
| 014 | 6ad5 | 8395 | 19aa | 43c4 | 9cea | 3a3c90 | e84150 |
| 015 | 607c | 3753 | 8a69 | 44bf | b41f | ddb1eb | 4a42ff |
| 016 | 7b03 | f067 | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 017 | 05f1 | 89f3 | 5067 | 6712 | b1c4 | 3b5245 | 4c4e35 |
| 018 | e20d | 5346 | 71a8 | 4b26 | a31d | ab914d | e39049 |
| 019 | 15c5 | 52bd | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 020 | e917 | b879 | 08dd | 4387 | b520 | 814a8a | 10717b |
Fields 1 and 3 of "demo" contain only unique values. Ignoring those two fields, are there any duplicate records in the table? The 2020 command was:
awk -F"\t" 'FNR==NR {a[$2,$4,$5,$6,$7,$8]++; next} \
a[$2,$4,$5,$6,$7,$8]>1' demo demo
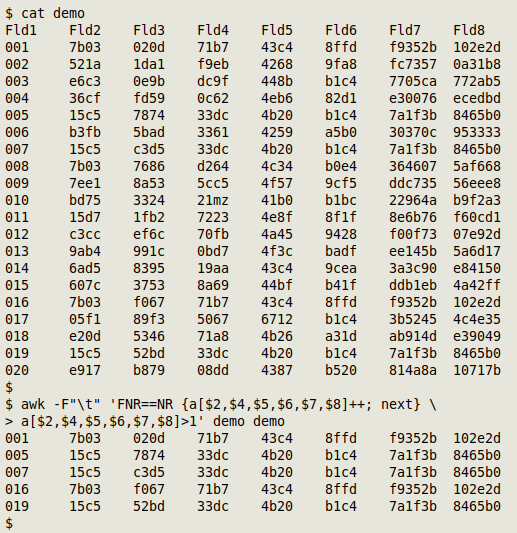
And the output can be sorted to suit.
The method works fine, but what if there are one or two unique identifier fields and 100+ other fields? It's tedious to build an index string like $2,$4,$5,$6,$7,$8....
In my improved method, I don't have to build that string at all. Instead I first set the unique identifier field entries to the arbitrary value "1" in the first pass through the table, then index the just-modified record as $0. In the second pass, I first assign the whole, unmodified record to the variable "x", then repeat setting the unique identifier fields to "1". If the value of the array with the modified record as index is greater than 1, I print "x":
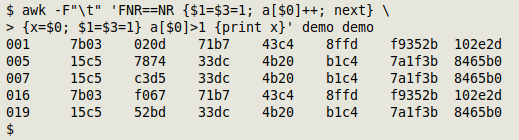
awk -F"\t" 'FNR==NR {[Set UI field(s) = 1; a[$0]++; next} \
{x=$0; [Set UI field(s) = 1]} a[$0]>1 {print x}' table table
The unique identifier field entries can be set to any arbitrary value. I use "1", but the empty string ("") and the string "hippopotamus" (with quotes) would work just as well. The aim is to make those unique identifiers non-unique.
It's a simple change in the code, but it saves a lot of fiddling!
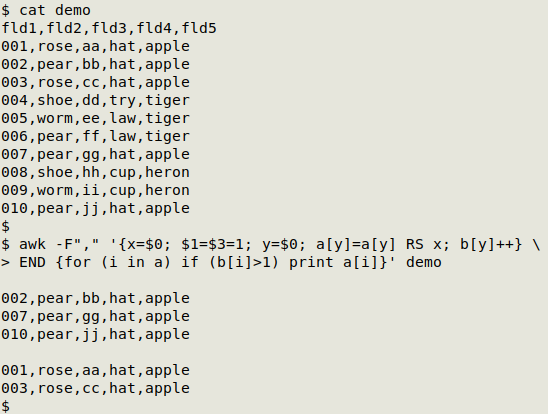
Update. An elegant one-pass variation of this command was suggested by Janis Papanagnou in 2023. The output is sets of partial duplicate records with each set separated by a blank line:
awk -F"\t" '{x=$0; [Set UI field(s) = 1]; y=$0; a[y]=a[y] RS x; b[y]++} END {for (i in a) if (b[i]>1) print a[i]}' table
In the screenshot below, the CSV "demo" has unique IDs in fields 1 and 3:
Last update: 2023-08-19
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License