
For a full list of BASHing data blog posts see the index page. ![]()
Introducing the replo
A typo is a text error in typing or typesetting, usually caused by a human pressing the wrong key on a keyboard.
What I call a replo is a text error caused by a computer replacing one or more characters with a question mark, mojibake, a replacement character or some other unwelcome substitute.
I've wanted an umbrella term for those replacements for a long time, because I see them so often when auditing data. "There are some character encoding and conversion failures in your dataset" sounds too clinical. "You've got replos!" is snappier and more general. I'll get blank looks, of course, until the word "replo" becomes better known...
The replos I see come in three flavours: reversible, reconstructable and researchable.
A reversible replo appears when your text-viewing software is set to the wrong character encoding. When you set the encoding correctly, the original characters appear. For example, suppose I tell my terminal to print a certain string of 1-byte characters:

I get 3 replos, each a replacement character. Why? Because my terminal program was expecting that the string would be UTF-8 encoded, like everything else on my Debian Linux system, and the string was in a different encoding.
I can reverse the replacements with a program like iconv. I tell iconv that I want the string converted to UTF-8 (so my terminal program can understand it), and I also tell it what the original encoding is. In this case, the 1-byte characters I used were in Mac OS Roman encoding (not the more familiar Windows-1252 or Latin-1 = ISO 8859-1):
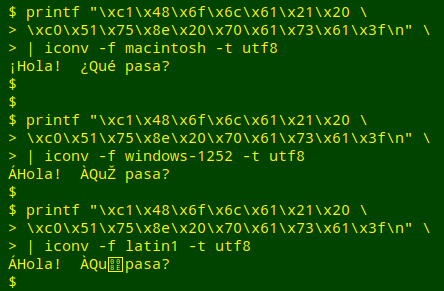
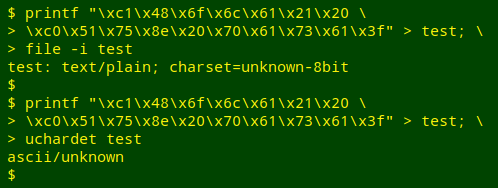
Finding the correct original encoding of a file full of replos can be challenging; neither file nor uchardet would have been much help in this case (see next screenshot). A handy comparison chart of common Western encodings is here in Wikipedia.
A reconstructable replo is a job for a detective. It's a character (or characters) related to the original(s) by a chain of encoding conversions, and if you can puzzle out the chain, you can often reconstruct the original.
The string below, as seen in Geany text editor, has 4 replos:

A first step would be to pipe the string to xxd, to see what its bytes are, in hexadecimal:
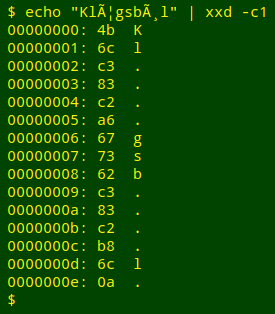
The "c3" and "c2" bytes that begin each 2-byte replo are common in the basic Unicode characters. It's also common to see a leading capital A with tilde (Ã) in strings that originally had a 2-byte Unicode character and were converted to 1-byte Windows-1252 encoding, because in that encoding à has hex value "c3".
See this webpage for a handy table of UTF-8-to-Windows-1252 "mistakes".
A reasonable guess, then, is that the string was originally in UTF-8, with 2-byte characters. It was converted to Windows-1252, at which point each of the bytes became a separate character. Then the string was converted back to UTF-8, and each of the 1-byte Windows-1252 characters was expanded to a Unicode 2-byte character.
Working backwards:
- "c3 83" in UTF-8 was "c3" in Windows-1252 = Ã
- "c2 a6" in UTF-8 was "a6" in Windows-1252 = ¦ (broken bar)
- "c3 83" in UTF-8 was "c3" in Windows-1252 = Ã
- "c3 b8" in UTF-8 was "b8" in Windows-1252 = ¸ (cedilla)
So the original 2-byte UTF-8 characters that Windows-1252 saw as 1-byte characters were "c3 a6" and "c3 b8". "c3 a6" in UTF-8 is æ (latin small letter ae) and "c3 b8" in UTF-8 is ø (latin small letter o with stroke).
The original string was therefore Klægsbøl, the Danish name for the German locality Klixbüll (just over the Denmark/Germany border). Here's the command-line version of the second part of the conversion chain:

For similar replo reconstructions, see this BASHing data post.
A researchable replo is one where guessing the encoding and trying to reconstruct conversions are hopeless tasks. The original character has been replaced with a perfectly valid new character which has no relation whatsoever to the original. Here's a researchable replo I recently came across:
Zapa?owicz
From context it might be the surname of a botanist, and some googling research turned up Hugo Zapałowicz (1852-1917). To be certain, I'd check with the compiler of the data file I was auditing, since "Zapanowicz" is another European surname.
The replo "?" replaced a "latin small letter l with stroke", Unicode U+0142.
Last update: 2019-11-01
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License