
For a list of BASHing data 2 blog posts see the index page. ![]()
Mapping with gnuplot, part 4
In a post in the first BASHing data series I showed how to build a basemap using gnuplot. I've since worked out a better way to do this job, and also fixed a failure in the code, as explained below.
I build a basemap by preparing a plain text file with an ordered list of "x" (decimal longitude) and "y" (decimal latitude) values, space- or tab-separated. The coordinates mark the nodes either of multilines or polygons. In both cases gnuplot will simply join one point to the next with a line, drawing the basemap.
An easy way to get the ordered coordinate pairs is to load a shapefile into QGIS and use the MMQGIS plugin to extract node coordinates with the plugin's "Geometry Export to CSV File" option. This option builds two CSVs for each shapefile, one for the nodes and one for the associated attributes. It's the nodes CSV I'm interested in.
As an example I'll use the Bermuda "Administrative Areas" shapefiles from the Download data by country service provided by DIVA-GIS. One of these is a polygon shapefile with the boundaries of Bermuda's nine parishes and two incorporated municipalities. Here's how those polygons look in QGIS:
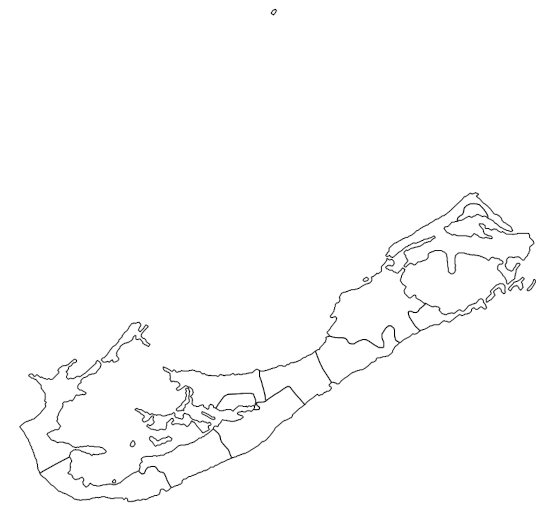
The MMQGIS export for this shapefile, "temp1-node.csv", has a header line and four comma-separated fields:
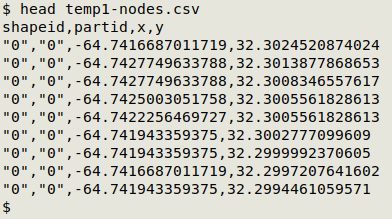
I want to delete the header line and the first two fields, round off the last two fields to 4 decimal places and space-separate them, and separate the 11 shapeID values ("0" to "10") with blank lines so that gnuplot knows where one polygon ends and another begins. I can do this job with a pair of AWK commands:
awk -F"," 'NR>1 {a[$1]=a[$1] RS $0} END {for (i in a) print a[i]}' temp1-nodes.csv | awk -F"," 'NR>1 {if ($0=="") print; else printf("%0.4f %0.4f\n",$3,$4)}' > bermuda1
See end of post for explanation.
If I plot "bermuda1" with gnuplot I get the polygons I want , but I also get extraneous lines, where gnuplot has joined polygon vertices unnecessarily:
gnuplot <<EOF
set term wxt size 600,600 position 300,100 persist
set size ratio 1.1
set style line 1 lc rgb "gray" lw 0.5
set style line 2 lc rgb "black" lw 0.5
set format x "%0.2f"
set format y "%0.2f"
set xrange [-64.9:-64.6]
set yrange [32.2:32.5]
set xtics 0.05
set ytics 0.05
set tics nomirror out font "Sans, 10"
set grid linestyle 1
plot "bermuda1" with lines linestyle 2 notitle
EOF
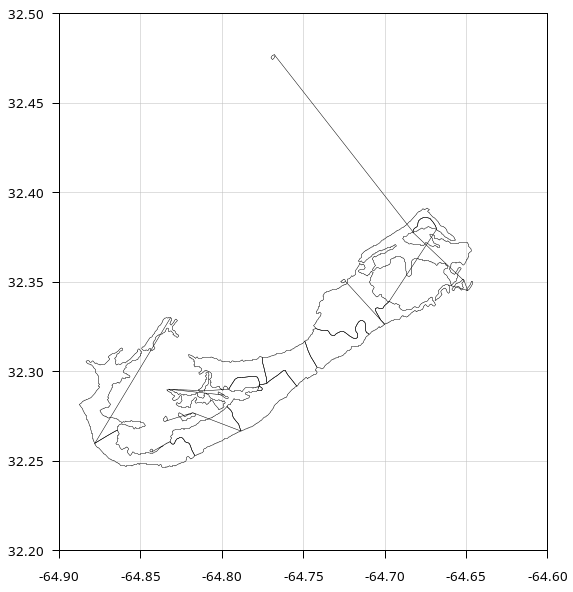
Why the extraneous lines? Because most of the polygons are divided into parts, with each part getting a separate partid:
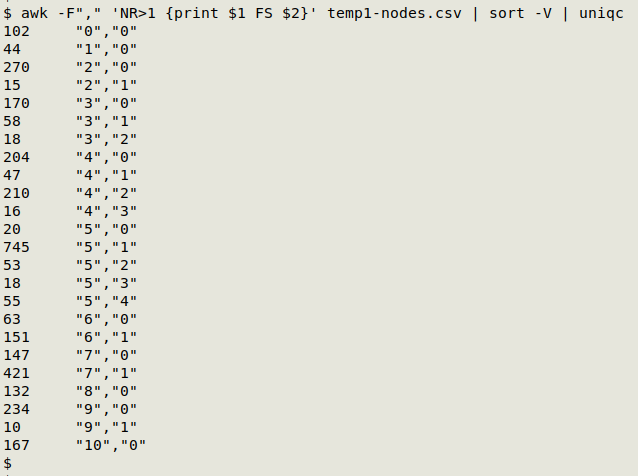
alias uniqc="uniq -c | sed 's/^[ ]*//;s/ /\t/'"
A minor tweak to the first AWK command fixes that:
awk -F"," 'NR>1 {a[$1$2]=a[$1$2] RS $0} END {for (i in a) print a[i]}' temp1-nodes.csv | awk -F"," 'NR>1 {if ($0=="") print; else printf("%0.4f %0.4f\n",$3,$4)}' > bermuda2
See end of post for explanation.
Here's the "bermuda2" plot:
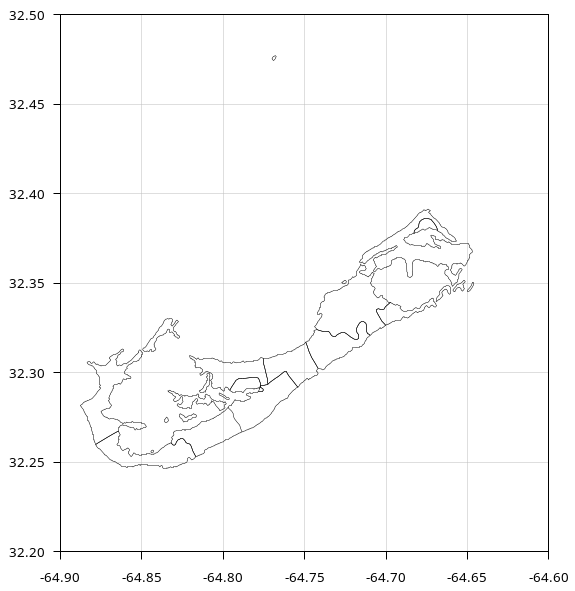
A final adjustment to the AWK commands is to tidy the output by deleting any duplicate lon/lat pairs that were generated when coordinates were rounded to four decimal places:
awk -F"," 'NR>1 {a[$1$2]=a[$1$2] RS $0} END {for (i in a) print a[i]}' temp1-nodes.csv | awk -F"," 'NR>1 {if ($0=="") print; else if (!b[$0]++) printf("%0.4f %0.4f\n",$3,$4)}' > bermuda3
See end of post for explanation.
In this case there weren't many duplicates to eliminate, but in other plots I've done there were quite a few.
To show how the AWK commands work I'll use this "demo" file:
fld1,fld2,fld3
0,0,a
0,0,b
0,1,c
1,0,d
1,0,d
1,1,e
1,1,f
2,0,g
2,0,h
2,0,h
2,0,i
2,1,j
For the principle behind the first command I'm indebted to AWK wizard Janis Papanagnou. Here's the first version, above, of the first command:
$ awk -F"," 'NR>1 {a[$1]=a[$1] RS $0} END {for (i in a) print a[i]}' demo
0,0,a
0,0,b
0,1,c
1,0,d
1,0,d
1,1,e
1,1,f
2,0,g
2,0,h
2,0,h
2,0,i
2,1,j
After ignoring the header line, AWK builds an array "a" indexed with the first field, then in an END statement it prints out each of the array's value strings. Each value string is a stack of lines, in their original order, with separate stacks for each of the three index strings (0, 1, 2). The stacks are built by adding to the existing array value a newline and the current line (a[$1]=a[$1] RS $0). The first time AWK encounters a particular index string, there is no existing array value, so the array value is just a newline and the current line. In this way each stack begins with a blank line, separating the stacks.
(An alternative command for ordered tables that does this job would be
awk -F"," 'NR>1 {print ($1 == x ? "" : "\n") $0; x=$1}' demo
Here AWK ignores the header line and tests each succeeding line before printing the line. The test is Does field 1 equal "x"?. The test makes no sense for the first line because "x" has not yet been defined, so AWK just prints the first line, then sets "x" equal to the contents of field 1. At the second line field 1 equals "x", so AWK prints an empty string, i.e. nothing, before that second line. At the third line, field 1 doesn't equal "x", so AWK prints a newline before the third line, thus creating a blank line when field 1 changes.)
The second version of the first AWK command makes the index string a concatenation of the first and second fields:
$ awk -F"," 'NR>1 {a[$1$2]=a[$1$2] RS $0} END {for (i in a) print a[i]}' demo
0,0,a
0,0,b
1,0,d
1,0,d
0,1,c
2,0,g
2,0,h
2,0,h
2,0,i
1,1,e
1,1,f
2,1,j
(The alternative command for ordered tables with the concatenation trick would be
awk -F"," 'NR>1 {print ($1","$2 == x ? "" : "\n") $0; x=$1","$2}')
Note that the stacks aren't ordered by first and second fields, because arrays aren't ordered in AWK. This doesn't matter for gnuplot plotting, because each stack will be plotted separately.
The final version of the command is:
$ awk -F"," 'NR>1 {a[$1$2]=a[$1$2] RS $0} END {for (i in a) print a[i]}' demo \
> | awk -F"," 'NR>1 {if ($0=="") print; else if (!b[$0]++) printf("%0.4f %0.4f\n",$3,$4)}'
The added AWK command prints blank lines but gets rid of the duplicate lines without changing the order of the output. It works by adding a condition, if (!b[$0]++) (the "b" is an arbitrary label), which has been discussed at length in a Stack Exchange post here and another here. It's an elegant AWK way to remove duplicate lines without changing the line order in a file.
Last update: 2024-03-08
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License