
For a full list of BASHing data blog posts see the index page. ![]()
Show Unicode code points for UTF-8 characters
Like the title says, I wanted to show the Unicode code points (formatted \uxxxx) for a set of UTF-8 characters. There are programs that do just that in a number of programming languages, but I wanted to do the job with garden-variety shell tools.
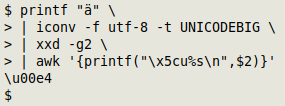
The solution I've chosen is based on a 2019 SuperUser suggestion from Brazilian developer Danilo G. Veraszto. The trick is to first convert the character to "UNICODEBIG" (big-endian Unicode) encoding with iconv. I pass the output to xxd, set to put a space between every two bytes (-g 2):

The last step is to extract the second, space-delimited field with AWK and printf it with a leading backslash and a "u":
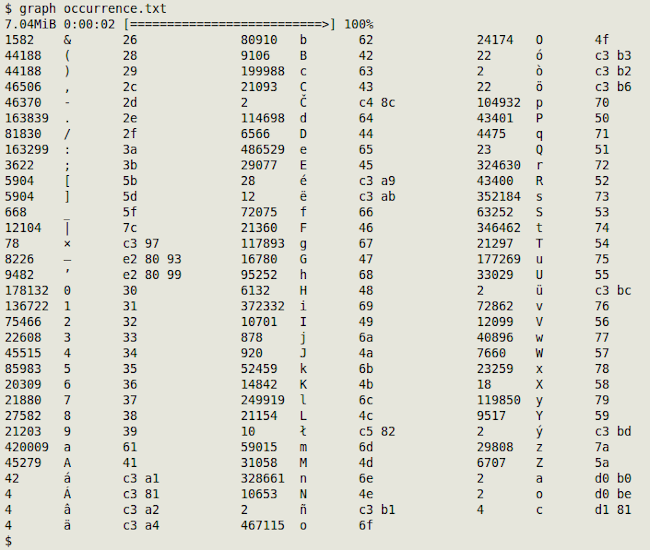
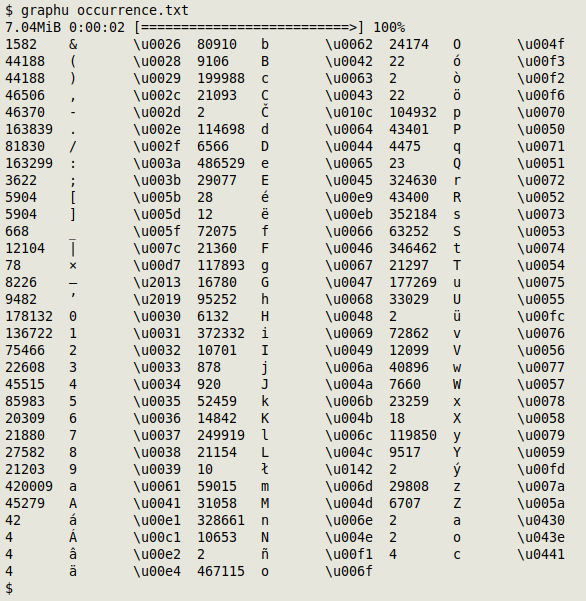
I've incorporated the iconv > xxd > AWK chain in a script I use called "graphu". It's a modification of "graph", which takes a UTF-8 encoded file and returns a sorted, tab-separated and columnated tally of all the characters in the POSIX graph class in the file, plus their hexadecimal representations. The modified script, called "graphu", does the same with code points:
Last update: 2021-09-15
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License