
For a full list of BASHing data blog posts see the index page. ![]()
Four kinds of data anomalies
Datasets sometimes contain perfectly well-formed items that really don't belong with the other items in their field. In my data auditing work, anomalous items are typically out of range, out of place, out of match or out of date. Below are some real-world examples.
Out of range. These anomalies are numerical or geographical outliers and can usually be detected by sorting and uniquifying the contents of a field (or by quickly plotting coordinates in a GIS program). They show up at the endpoints of a sort and I find them with the toptail function. In the example below, an ISO 8601 date field (15) in a TSV ("set1") has out-of-range dates at both the bottom and top of the range:

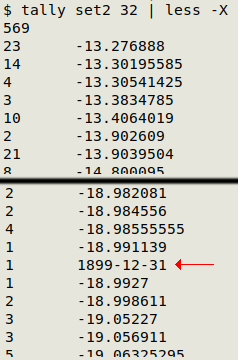
Out of place. An example of this kind of anomaly is shown below, where a sorted-and-uniquified tally of "set2" shows a well-formed ISO 8601 date lurking among the decimal latitudes of field 32. It doesn't belong there!
Out of match. These are surprisingly common but can be hard to detect. An out of match anomaly occurs when a data item in field "A" is matched with a valid but wrong data item in field "B".
I look for out-of-match anomalies in tidy datasets using the one2many function. In the example below, field 38 ("A") in "set3" holds hundreds of scientific names for insects, while field 43 ("B") contains the names of the insect orders to which those species belong. Each species name should be matched to one and only one order, but one2many has found records with more than one match. ("Blattaria" is incorrect.)

The first field in the return is number of records, the second holds data items from field "A" and the third holds the corresponding data items from field "B". Note that out-of-match anomalies might not be detected in untidy datasets, where there are variant spellings or formats for some of the field "A" data items.
Another function (one2manyLL) checks for out-of-match anomalies in field "C" for paired data items in fields "A" and "B". I've so far only used one2manyLL for checking latitude ("A") - longitude ("B") pairs against entries in another field ("C").
Out of date. Obsolete data items might be detected with a tally, but only if you're familiar with the class of data items concerned. Easily spotted out-of-date anomalies might be "Burma" in a field with country names, or "World Wrestling Federation" (WWF) in a field with sporting organisations. A more reliable method is to compare data items with those in an up-to-date lookup table. For that job I use AWK, putting the up-to-date items from the lookup table in an array, then looking for items in the data table that aren't in the array.
Here's an example. "set4" is a 1,639,385-record, 81-field TSV of insect specimens in a museum in the UK, and field 58 contains the scientific names of the insect orders to which each specimen belongs. My lookup table, "lookup", is copied from Wikipedia and is a tab-separated list of currently accepted insect orders (field 1) and estimated numbers of species in each (field 2):
awk -F"\t" 'FNR==NR {a[$1]; next} NR>1 && !($58 in a) \
{print $58}' lookup set4 | sort | uniq -c
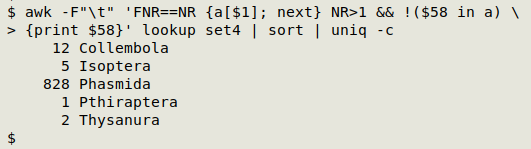
OK, "Pthiraptera" is a misspelling of "Phthiraptera". The other 4 anomalies are obsolete names:
- "Collembola" are no longer classified as insects
- "Isoptera" (termites) are now regarded as social cockroaches, in "Blattodea"
- "Phasmida" has been widely replaced by "Phasmatodea"
- "Thysanura" has been split into "Archaeognatha" and "Zygentoma"
Last update: 2021-02-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License