
For a full list of BASHing data blog posts see the index page. ![]()
Character equivalence classes 2: the nature of equivalence
In part 1 of this 2-part series I showed how to use POSIX equivalence classes in searching and replacing. But what does "equivalence" actually mean?
It's complicated, but equivalence classes based on Unicode are derived mainly from the script in which the characters appear, not by the appearance of the characters. For example, suppose I create a string using the UTF-8 characters for "A" and "a" in the Latin and Cyrillic scripts:
foo=$(printf "Latin\u0041\u0061 Cyrillic\u0410\u0430")

The "Aa" characters might look the same, but sed knows the difference:
sed 's/[[=a=]]/B/g' <<<"$foo" #Latin "a"
sed 's/[[=а=]]/B/g' <<<"$foo" #Cyrillic "a"

To explore equivalence classes further, I built a large set of the characters in which "somethings like" might be lurking. I did that with a command (below) explained in an earlier BASHing data post. The variable "set1024" contains all the visible characters in the decimal range 0 to 1023, in a single long string:
set1024=$(seq 0 1023 | awk '{x=sprintf("%c",$0); \
if (x ~ /[[:graph:]]/) print x}' | paste -s -d "\0")
Next, I ran through the 26 Latin alphabet letters with a for loop, to see what the "something like" is for each of them in that big character set:
for i in {a..z}; do grep -o "[[=$i=]]" <<<"$set1024" \
| paste -s -d "\0"; done
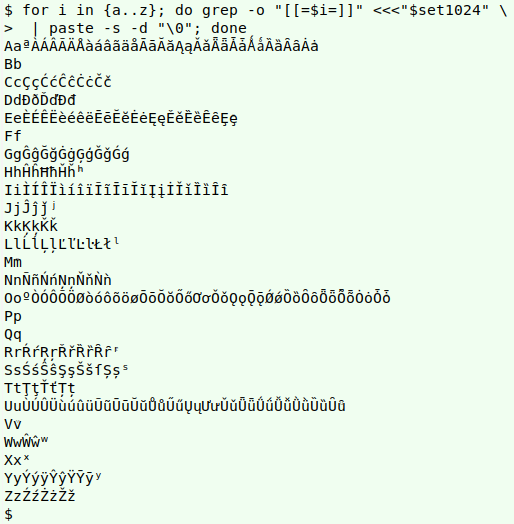
UTF-8 can encode a huge number of characters and "set1024" isn't an upper limit for alphabets with "a-like" characters. I still get "something like a" equivalents in "set1000000", like the 4-byte character with hex value f0 9f 85 b0 (negative squared Latin capital letter a; U+1F170).
So there are lots of "something likes" for some letters, but not for others. There aren't many "something likes" for digits, either, among the first 1024 visible UTF-8 characters:
for i in {0..9}; do grep -o "[[=$i=]]" <<<"$set1024"; done \
| paste -s -d "\0"

But high in the stratospheric regions of UTF-8, up to 1000000, there are some truly peculiar "something like" numerical characters. I wonder how those equivalences were decided?

Rendering here is with Bitstream Vera Sans Mono Roman.
Last update: 2020-06-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License