
For a full list of BASHing data blog posts see the index page. ![]()
Hunting gremlins
In the UTF-8 files I audit, the only invisible characters I expect to see... er... not see... are whitespace (hexadecimal 20), horizontal tab (09) and newline (linefeed; 0a). All others I call "gremlins". They include carriage return (0d), no-break space (c2 a0), soft hyphen (c2 ad) and another 62 control characters.
Gremlins are a nuisance. One gremlin causes a shell to hang. Less evil gremlins lurk inside apparently OK strings and cause the strings to be processed weirdly. In the file "demo1", two of the strings contain no-break spaces (in different places), two contain soft hyphens (in different places) and three have no gremlins. Watch what happens when I sort and uniquify "demo1":
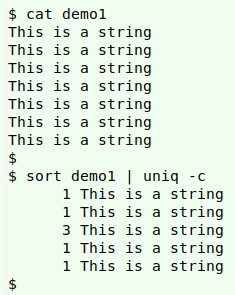
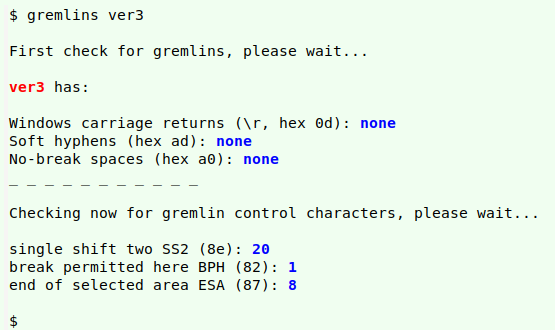
I detect and count gremlins with a shell script called "gremlins", shown here in A Data Cleaner's Cookbook. The first part of the script reports on carriage returns, soft hyphens and no-break spaces. The second part of the script looks for other control characters, and reports their abundance and their "core" hexadecimal values (main byte). (In UTF-8 encoding, the gremlins with "core" hex values from 80 up are two-byte characters with hex c2 as the first byte.)
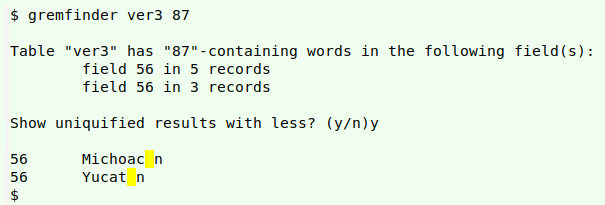
Tallying up gremlins is well and good, but before getting rid of them I need to know what they're doing in the file. For this I have another script, "gremfinder", shown below and in the Cookbook. The command takes as its arguments the name of the tab-separated table (TSV) and the "core" hex value of the gremlin in question, as reported by the "gremlins" script. The "gremfinder" automatically adds a c2 byte to the "core" hex value where needed in UTF-8 encoding, and locates gremlins by field. It generates a TSV with record (line) number, field number and data item containing the gremlin); the TSV is named "[selected hex value]-list-[filename]".
If wanted, the script then prints a uniquified list of data items in each field, with the invisible gremlin visualised as a space with yellow background coloring. Here's the result for ESA (core hex 87) in the table "ver3":
And here's the ESA gremlin log with line (record) number, field number and data item, as seen in my shell (left) and in Geany text editor (right):
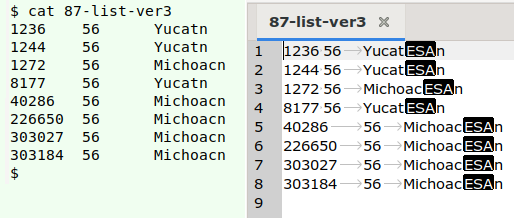
In this case the ESA's have replaced the á in Michoacán and Yucatán, so a global replacement in the file would be the correct fix (not just deleting the gremlin!). In UTF-8 encoding, á is hex c3 a1:
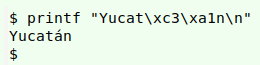
sed 's/\xc2\x87/\xc3\xa1/g' ver3 > ver4
á to ESA is a reconstructable replo. My guess is that the character started out on an Apple machine, where á has the hex value 87 in Macintosh encoding (Mac Roman). This was then read (somewhere non-Mac) as the C1 control code ESA, hex value 87, and converted to UTF-8 as c2 87.
The "gremfinder" script:
#!/bin/bash
yelbkg=$(printf "\033[103m")
reset=$(printf "\033[0m")
if ((128 > $(printf "%d" "0x$2"))); then
char=$(printf "\x$2")
else
char=$(printf "\xc2\x$2")
fi
awk -F"\t" -v grem="$char" '$0 ~ grem {for (i=1;i<=NF;i++) \
{if ($i ~ grem) {print NR FS i FS $i}}}' "$1" \
| sort -t $'\t' -nk2 -nk1 > "$2"-list-"$1"
echo
echo "Table \"$1\" has \"$2\"-containing words in the following field(s):"
cut -f2- "$2"-list-"$1" | sort | uniq -c | sed 's/[ ]*//;s/[ ]/\t/' \
| awk -F"\t" '{print "\tfield "$2" in "$1" records"}'
echo
read -p "Show uniquified results with less? (y/n)" foo
echo
if [ "$foo" == "n" ]; then
exit 0
else
cut -f2- "$2"-list-"$1" | sort -n | uniq | sed "s/$char/${yelbkg} ${reset}/g" | less -RX
fi
exit 0
The variables "yelbkg" and "reset" allow for visualising the gremlin later in the script. (See this BASHing data post.)
The "if/else" test asks whether the decimal value of the gremlin's "core" hex value is less than 128, which is 80 in hexadecimal. If yes, then the variable "char" is the gremlin as printfed with the "core" hex value alone. If not, "char" is the gremlin printfed with hex c2 followed by the "core" value.
The shell variable "char" is passed to AWK as the AWK variable "grem". AWK then looks for lines which contain the gremlin ($0 ~ grem). On those lines only, AWK searches field by field (for (i=1;i<=NF;i++)), and if it finds the gremlin in a field (if ($i ~ grem)), AWK prints the line (record) number, a tab, the field number, a tab, and the whole data item (print NR FS i FS $i). The resulting log of gremlin occurrences is sorted first by field number, then line number, then saved as the TSV log [selected hex value]-list-[filename].
In the next part of the script, echo reports an introduction to some results, namely the count of records with the gremlin in each field where it occurs. The count and field number are passed to AWK for printing.
The next "if/else" asks whether the script should display a uniquified list of data items by field. If the answer is "n", the script exits. If the answer is "y", the last 2 fields from the gremlin log (field number and data item) are cut out and passed to sort -n (for a numerical sort by field) and uniq. This uniquified list is then sent to sed for replacement of the gremlin by a space with a yellow background.
The final printing to screen is done using less with two options: -R to allow ANSI escape colors, and -X to allow the print to persist on screen (return to prompt by pressing "q").
Last update: 2020-01-22
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License