
For a full list of BASHing data blog posts see the index page. ![]()
How to guess the field separator in a table
So I download the table "blahblahblah.csv" for data auditing. Muttering a quick prayer to MIME, the goddess of file formats, I open the table. Yes! With joy in my heart I see that despite the ".csv" filename suffix, the table is actually tab-separated, not comma-separated. Once again I've escaped the dreaded Curse of the CSV Monster.
But did I have to actually open the file to check the format? Is there a command-line method for determining what field separator has been used in an unopened table?
I'm not sure, but I have a method for guessing the likely field separator. The method relies on the fact that in most of the data tables I see, there's a single header line containing the field names, and those field names only rarely contain repeats of likely separators.
In other words, the field names are usually something like
collection number
field number
basis of record
family
genus
species
subspecies
or occasionally:
Document.DataConcealment
Document.DataSecureLevel
Document.DataSecureReasons
Document.PartialDocument
Document.CollectionID
Document.Quality.CollectionReliabilityRating
Document.Quality.Issue.Issue
Missing from header lines (or only sparsely present) are the usual field separators, which are tab, comma, pipe, colon and semicolon. If I extract the header line from a table, search for those 5 characters and tally them up, then the character with the biggest tally is probably the field separator.
I can do this with a command chain, using grep with the PCRE option "-P":
head -1 table | grep -oP "[,;|:\t]" | sort | uniq -c
I'll try out the command chain with a slightly insane header line, a CSV with added punctuation, including a tab:
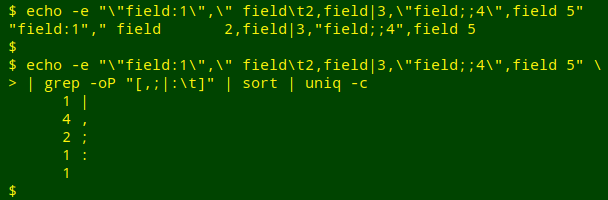
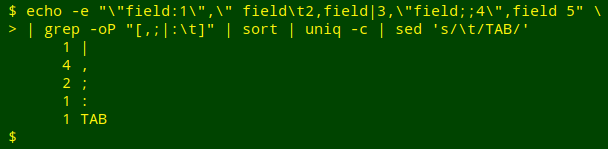
It worked, but because the tab is a non-printing character, it isn't visible in the tallies. I can fix that by replacing the tab with "TAB" using sed:
head -1 table | grep -oP "[,;|:\t]" | sort | uniq -c | sed 's/\t/TAB/'
The output from the command chain can be piped to sort -nr and head -1 to get just the biggest tally, not the full list of five tallies. I'll store the full command chain as the function "detsep" (determine separator):
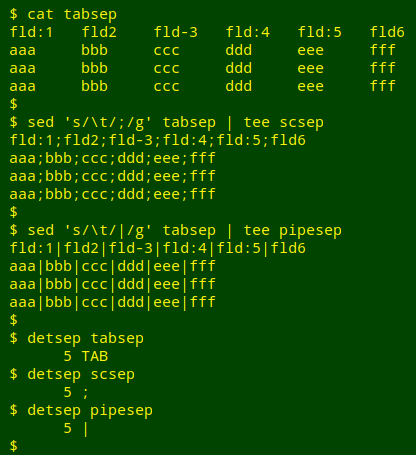
detsep() { head -1 "$1" | grep -oP "[,;|:\t]" | sort | uniq -c | sed 's/\t/TAB/' | sort -nr | head -1; }
And here's "detsep" at work on the tables "tabsep" (tab-separated), "scsep" (semicolon-separated) and "pipesep" (pipe-separated):
If your grep doesn't support the Perl-type regex option, try
grep -o "[,;|:$(printf '\t')]"
or
grep -o $'[,;|:\t]'
For an explanation of why the second alternative works, see this BASHing data post.
Last update: 2019-10-04
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License