
For a full list of BASHing data blog posts see the index page. ![]()
Long, narrow tables vs short, wide ones
The shape of a dataset is hugely important to how well it can be handled by different software. The shape defines how it is laid out: wide as in a spreadsheet, or long as in a database table. Each has its use, but it’s important to understand their differences and when each is the right choice.
In the quote above from data analyst Robert Kosara, two rather different kinds of data tables were being compared. But what about the same table in long vs short layout? Would the shape be "hugely important" for processing on the command line?
To satisfy my curiosity, I built a list (called "source") of 1,000,000 20-character passwords using pwgen. I added the -y option to allow pwgen to include non-alphanumeric characters.
pwgen 20 -y -N 1000000 > source
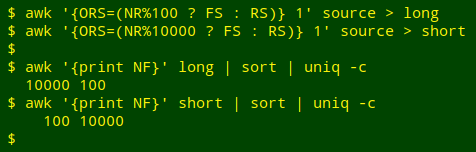
I then used AWK to construct a "long" table of 10,000 rows with 100 space-separated columns each, and a "short" table of 100 rows with 10,000 space-separated columns each:
awk '{ORS=(NR%100 ? FS : RS)} 1' source > long
awk '{ORS=(NR%10000 ? FS : RS)} 1' source > short
Finding strings in the table. For my first test I generated a more-or-less random selection of 10 passwords from "source":
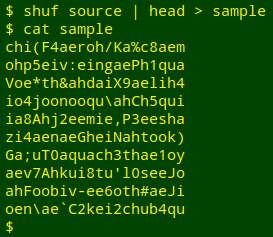
I then put the list of 10 passwords into an AWK array, and timed how long it took for AWK to find the passwords and give their locations:
time (awk 'FNR==NR {a[$0]=$0; next} \
{for (i=1;i<=NF;i++) \
{if ($i in a) print a[$i]"\tline "NR"\tfield "i}}' sample long)
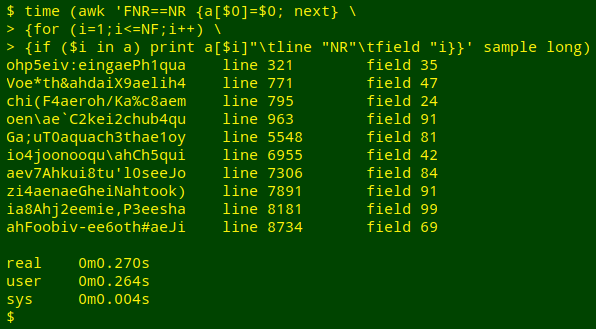
I did this 10 times each for "long" and "short" and averaged the results. There wasn't a big difference:
long: 0.266s (0.229 - 0.285)
short: 0.252s (0.219 - 0.307)
Adding up all the numbers in the table. For this second test I used an AWK trick explained in an earlier BASHing data post, except that to get a grand total, I didn't re-set the "sum" variable to zero at the end of each line:
time (awk -v FPAT="[0-9]+" '{for (i=1;i<=NF;i++) \
> sum+=$i} END {print sum}' long)
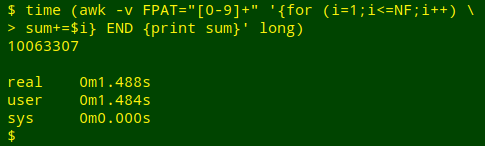
The 10-runs-each times didn't differ:
long: 1.471s (1.419 - 1.517)
short: 1.468s (1.420 - 1.504)
Tallying characters in the table. Here I used the graph script from the Cookbook to tally up the 20,000,000 1-byte characters in the table and give their hex values. The pv program embedded in the script did the timing, and it counted 10 seconds for each job:
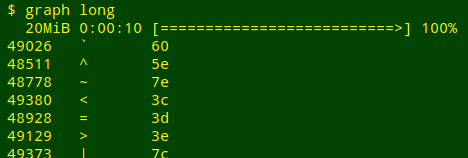
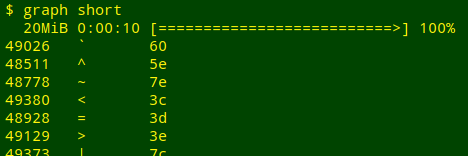
Conclusion. Long and narrow vs short and wide? For the table processing I do, mainly with AWK, it doesn't seem to matter.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License