
For a full list of BASHing data blog posts see the index page. ![]()
Renumber a list after inserting a line — updated
I was writing a long, numbered list in a text editor when Murphy's Law struck. Number 37 in the list, I realised, should really appear after number 14. I could insert a blank after line 14, cut out line 37 and paste it into the blank line 15, but then I would have to renumber all the following lines. Sigh. Maybe I could do that more quickly with some command-line code?
Yes, but... As usual, writing the code took longer than a manual edit would have taken. Also as usual, I had to choose between a range of possible command-line solutions. My first choice was to process the list and modify it with AWK, because I'm AWK-o-philic. My AWK command was ugly. And confusing.
Update. See end of post for a non-ugly AWK solution!
Next option: instead of processing the list as-is, how about taking it apart and rebuilding it?
- Remove the numbering
- Insert the new line
- Renumber the list
And that's what I did, using non-AWK shell tools. Here's "file", a simplified list:
(1) original line 1
(2) original line 2
(3) original line 3
(4) original line 4
(5) original line 5
(6) original line 6
(7) original line 7
(8) original line 8
(9) original line 9
(10) original line 10
And here's the code to insert a new line 6 and renumber the following lines:
INSERT="new line 6"
paste -d"\0" \
<(seq -f "(%g) " $(($(wc -l < file)+1))) \
<(cut -d" " -f2- file | sed "6i\\$INSERT")
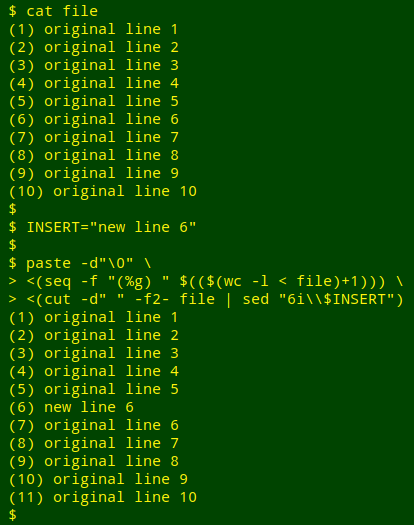
To explain the command I'll start with the last part, cut -d" " -f2- file | sed "6i\\$INSERT", the output of which is redirected to paste. The numbers (n) at the start of each line are separated from the text by a plain space, so I tell cut with -d" " to use as a space as the field delimiter. cut then slices out the text portions of the lines in "file" with -f2-, which means "field 2 and all following fields". The line numbering has been removed.
Next step is to insert some text in a new line following line 6. For this I use sed with its "i\" option. This inserts before the looked-for pattern, which in this case is the line address "6". The string to be inserted is here stored in the shell variable "INSERT". A backslash before the "\" in the "i\" stops the shell from seeing the string to be inserted as the literal string "$INSERT", and the sed command is wrapped in double quotes to allow the shell to expand the "$INSERT" variable. The new line has been inserted.
Now for the renumbering, which is done with the paste + seq method I described in a previous BASHing data post. The seq formatting includes the round brackets I use around my numbers, and the final number for seq to format comes from a bit of BASH arithmetic: $(($(wc -l < file)+1)). This adds 1 to the line count for the original file, obtained with wc -l. The output will have all its lines (originals + new line) correctly numbered.
The last job is done by paste. It joins the redirected seq command and the redirected cut+sed command with a blank space as separator (-d"\0).
Because the code might be useful in future, I rewrote it as a function. The first argument ($1) is the filename, the second ($2) is the line number for the insertion, and the third ($3) is the text to be inserted:
insren() { paste -d"\0" <(seq -f "(%g) " $(($(wc -l < "$1")+1))) <(cut -d" " -f2- "$1" | sed "$2i\\$3"); }
It works:
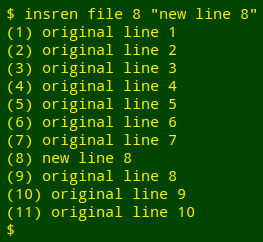
"insren" would need modifying for a different numbering format (in the seq section, and maybe for cut and paste as well), but it suits my habitual (1), (2), (3)... list-numbering style. I've added "insren" to my functions library so I can remember and edit it when needed.
Reader Markus Weihs sent me an AWK solution that's not as confusing as the one I wrote (and am too embarrassed to show here). Slightly modified, his function is:
awkinsren() { awk -v line="$2" -v text="$3" \
'NR == line {ln++; printf ("(%g) %s\n",ln,text)} \
{ln++; $1="("ln")"; print}' "$1"; }
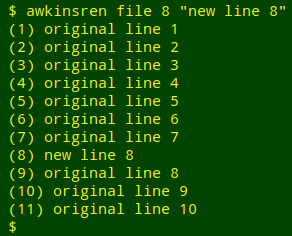
As in the non-AWK "insren", the arguments are the filename (1), the line for insertion (2) and the text for insertion (3). The arguments are first converted from the shell variables "$2" and "$3" to the AWK variables "line" and "text".
The first part of the AWK command has the condition "NR == line", so it only applies when the line for insertion is reached. Otherwise, AWK moves to the second part of the command. Here the counter "ln" counts line numbers. Since AWK by default processes a file line by line, "ln" will be 1 for line 1, 2 for line 2, etc. Having got that count, AWK redefines field 1 as "ln" in round brackets and prints the line. For lines up to the line of insertion, then, there's no change in line numbering.
When the line for insertion is reached, AWK continues the line count with "ln", then uses printf to print the text for insertion preceded by the line number in brackets.
AWK now processes the line following the inserted line. Because the counter "ln" has still been ticking over, this line is printed with the previous number plus 1, i.e. the new "ln" value.
Many thanks, Markus!
Last update: 2019-07-27
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License