
For a full list of BASHing data blog posts, see the index page. ![]()
Growing the Cookbook's "broken" function
A Data Cleaner's Cookbook describes "broken" records and recommends a function that checks for "brokenness":
broken() { awk -F"\t" '{print NF}' "$1" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/' | sort -nr; }
This tallies the number of fields in all the records in a tab-separated data table, including the header, and reports number of records[tab]number of fields in descending order of frequency. In the screenshot below, "fileA" has 10985 lines with 15 fields each, while "fileB" has 10980 lines with 15 fields, 5 lines with 2 fields and 5 lines with 14 fields:
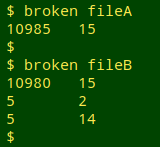
In a table with N fields, every record should have exactly N fields. A record with more or fewer than N fields is broken and needs fixing before any further data auditing or cleaning is done. I can see that "fileB" has a problem, but the broken function hasn't said which records are defective. In the past I used AWK to search for records with the "wrong" number of fields:
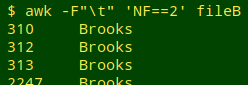
This wasn't a very satisfactory way to proceed, because (among other things) it didn't show when broken records were related, as happens when a record is split over multiple lines.
After having this issue on my "to do" list for a few years, I finally hacked together one of my famously ugly scripts, shown at the bottom of this page and called fldnos. If the table being checked has the same number of tab-separated fields in all records, fldnos says so:

If the table being checked doesn't have the same number of fields in all records, fldnos tallies them the way broken did and asks if I want a line-by-line list of broken records:
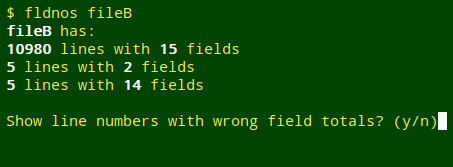
If I say no ("n"), fldnos exits. If I say yes ("y"), fldnos prints the list in order of line numbers:
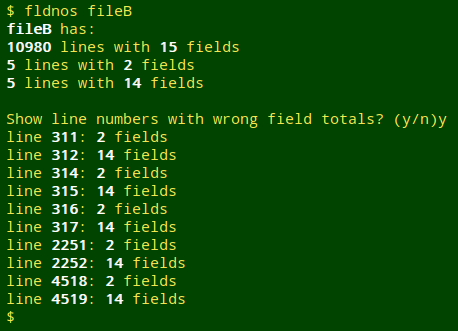
The pattern of results for "fileB" is the expected one for an embedded newline within a field. Here it's turning a 15-field record into a 2-field record followed immediately by a 14-field record, as shown in the screenshot below for lines 311 and 312:
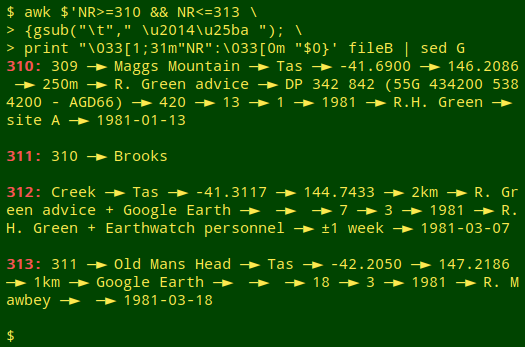
Some fancy terminal printing here. I've coloured the line number and colon with ANSI escape codes, replaced each tab character in the output with a space, an em dash, a "black right-pointing pointer" and a space, and double-spaced the output with sed G. See this BASHing data post for an explanation of the "$" before the AWK command string.
For a fix of broken records caused by embedded newlines, see this BASHing data post.
The fldnos script:
#!/bin/bash
gray="\033[1;37m"
reset="\033[0m"
var1=$(awk -F"\t" '{print NF}' "$1" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/' | sort -nr)
var2=$(echo "$var1" | wc -l)
if [ "$var2" -eq "1" ]; then
printf "All $gray$(echo "$var1" | cut -f1)$reset lines in $gray$1$reset have $gray$(echo "$var1" | cut -f2)$reset fields\n"
else
printf "$gray$1$reset has:\n"
echo "$var1" | awk -F"\t" -v GRAY="$gray" -v RESET="$reset" '{print GRAY $1 RESET" lines with "GRAY $2 RESET" fields"}'
echo
read -p "Show line numbers with wrong field totals? (y/n)" var3
case "$var3" in
n) exit 0;;
y) echo "$var1" | sort -nr | tail -n +2 | cut -f2> /tmp/wrongs
awk -F"\t" -v GRAY="$gray" -v RESET="$reset" 'FNR==NR {arr[$0]; next} (NF in arr) {print "line "GRAY FNR RESET": "GRAY NF RESET" fields"}' /tmp/wrongs "$1"
rm /tmp/wrongs;;
esac
fi
exit 0
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License