
For a list of BASHing data 2 blog posts see the index page. ![]()
Format musings 1: NestedText and indentation
NestedText is a relatively new format (2020 >) for sharing data between applications as uncompressed strings. Strings are its only data types and the NestedText rules allow for special characters (like "{") and syntactical elements (like "<something>") to be parsed as literal strings.
The NestedText documentation is very good and the philosophy behind the format is clearly explained. Interested readers should look at the NestedText rules but what I'd like to muse about in this post is the "Nested" in "NestedText". A key element in NestedText structuring is indentation:
Leading spaces on a line represents indentation. Only ASCII spaces are allowed in the indentation. Specifically, tabs and the various Unicode spaces are not allowed.
There is no indentation on the top-level object.
An increase in the number of spaces in the indentation signifies the start of a nested object. Indentation must return to a prior level when the nested object ends.
Each level of indentation need not employ the same number of additional spaces, though it is recommended that you choose either 2 or 4 spaces to represent a level of nesting and you use that consistently throughout the document. However, this is not required. Any increase in the number of spaces in the indentation represents an indent and a decrease to return to a prior indentation represents a dedent.
An indented value may only follow a list item or dictionary item that does not have a value on the same line. An indented value must follow a key item.
Maybe not surprisingly, NestedText has an associated Python writer and reader. Python depends on rule-based indentation, and indentation errors in Python code are very common. They're common, I suspect, because indentation is an invisible structural element in the code.
In my genuinely humble opinion (IMGHO), structuring code or data with invisible characters is a mistake. Unlike NestedText, popular formats like JSON and XML use visible characters or strings to define levels in a data structure. Again IMGHO, this makes it harder to stuff up the structure, although it's still possible. Indentation is unnecessary in these other formats and is only used to help with readability; parsers ignore the indents.
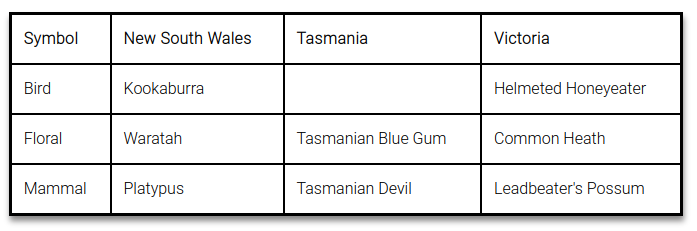
Let's see what a simple 2-dimensional data table looks like in various formats:
| Symbol | New South Wales | Tasmania | Victoria |
| Bird | Kookaburra | Helmeted Honeyeater | |
| Floral | Waratah | Tasmanian Blue Gum | Common Heath |
| Mammal | Platypus | Tasmanian Devil | Leadbeater's Possum |
If you copy and paste the table into a text editor you'll have a TSV. A NestedText version of the table might look like this:
Symbol: Bird
New South Wales: Kookaburra
Tasmania:
Victoria: Helmeted Honeyeater
Symbol: Floral
New South Wales: Waratah
Tasmania: Tasmanian Blue Gum
Victoria: Common Heath
Symbol: Mammal
New South Wales: Platypus
Tasmania: Tasmanian Devil
Victoria: Leadbeater's Possum
A JSON version with indentation for readability:
[
{
"Symbol": "Bird",
"New South Wales": "Kookaburra",
"Tasmania": "",
"Victoria": "Helmeted Honeyeater"
},
{
"Symbol": "Floral",
"New South Wales": "Waratah",
"Tasmania": "Tasmanian Blue Gum",
"Victoria": "Common Heath"
},
{
"Symbol": "Mammal",
"New South Wales": "Platypus",
"Tasmania": "Tasmanian Devil",
"Victoria": "Leadbeater's Possum"
}
]
The same in JSON Lines format:
{"Symbol":"Bird","New South Wales":"Kookaburra","Tasmania":"","Victoria":"Helmeted Honeyeater"}
{"Symbol":"Floral","New South Wales":"Waratah","Tasmania":"Tasmanian Blue Gum","Victoria":"Common Heath"}
{"Symbol":"Mammal","New South Wales":"Platypus","Tasmania":"Tasmanian Devil","Victoria":"Leadbeater's Possum"}
I put the JSON into an online JSON-to-HTML-table converter and got this, which again yields the original TSV if I copy-and-paste:
I'm not sure how best to convert my NestedText version back into a table, but I'll try with text tools. First I'll copy and paste the NestedText above into a text editor and save it as "statesymbols.nt"; the 4-space indents are preserved in this file.
Next I'll use a couple of AWK commands to reconstruct the TSV, then display it with csvlook from the csvkit package:
awk '!/^ / {print ""; printf ("%s",$0)} \
> /^ / {gsub(/^[ ]{4}/,"\t"); printf ("%s",$0)}' statesymbols.nt \
> | awk -F"\t" '{gsub(/: |:/,"\t")} \
> NR==2 {print $1,$3,$5,$7; print $2,$4,$6,$8} \
> NR>2 {print $2,$4,$6,$8}' OFS="\t" | csvlook

The first AWK command looks for lines in "statesymbols.nt" not beginning with a space (!/^ /), and in a NestedText file that would be the first line. AWK first prints a blank line, then the full line without a newline at the end (print ""; printf ("%s",$0)). If the line does begin with a space (a nested line) (/^ / ), AWK first replaces the initial 4 spaces I've used for indentation with a tab (gsub(/^[ ]{4}/,"\t")), then again prints the line without a newline at the end (printf ("%s",$0)).
The result is a series of lines with tab-separated blocks. The first block is the top-level line, and succeeding blocks are the nested elements. This result is passed to a second AWK command that specifies the tab character as field separator ( -F"\t"). The first action in the command replaces colons and colons+space with tabs ({gsub(/: |:/,"\t")}) and this applies to all lines. AWK looks first at line 2 (line 1 is blank) (NR==2) and prints the header, then the first line of the table by selecting the appropriate fields (print $1,$3,$5,$7; print $2,$4,$6,$8). For succeeding lines AWK prints just the value items (NR>2 {print $2,$4,$6,$8}). The output is tab-separated (OFS="\t").
Note that this ad hoc solution starts by getting rid of the indentations and only works with a single level of nesting, a known number of nested elements and a known number of spaces for indentation. A NestedText file with several levels of data would be a lot harder to deal with, just as multi-level JSON is difficult. Maybe NestedText needs a jq?
Next post:
2025-07-25 GNU sed's handy -z option
Last update: 2025-07-18
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License