
For a list of BASHing data 2 blog posts see the index page. ![]()
Making an archive job a lot easier
I often receive .zip archives for audit with several files inside, only one or two of which I want uncompressed ("inflated"). While GUI tools like xarchiver are fine for inspecting archive contents, selecting files and extracting them, I usually want to work with the resulting files on the command line.
Most of the archives contain Darwin Core data in files with rather long filenames, so I also want my working copies of the uncompressed files to have two-letter filenames, like "occurrence.txt" copied to "oc", to reduce typing time.
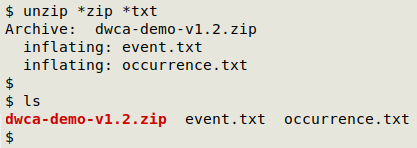
Here's an example, the archive "dwca-demo-v1.2.zip". The command unzip -l lists the files in the archive, and note that unzip understands wildcards:

To extract just "event.txt" and "occurrence.txt", I can again use a wildcard:
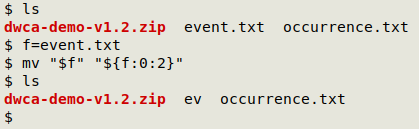
A quick way to rename a file with just the first two letters of the filename is with a BASH-ism, "mv $[filename] ${[filename]:0:2}".
So, putting all this together I have a shell function "dz" for working with Darwin Core archives:
dz() { for i in *txt; do unzip -q *zip "$i"; done && for j in *txt; do mv "$j" "${j:0:2}"; done && ls; }
The first for loop gets unzip to look for a ZIP file and extract to the current directory any compressed files with "txt". I use the -q option with unzip to suppress messages going to stdout. When unzip has finished its work, a second for loop renames the uncompressed files with the first two letters of the original filename. Finally, ls lists the contents of the current directory.
Here's "dz" at work on a different archive:

For a keyboarder like me, "dz" saves a lot of time. I use it in a working directory containing only the one ZIP file of interest and no .txt files.
Next post:
2025-06-13 How to hide a number in plain sight
Last update: 2025-06-06
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License