
For a full list of BASHing data blog posts see the index page. ![]()
How to use patsplit (GNU AWK)
patsplit was introduced in version 4.0 of GNU AWK. It's a string splitter, and it allows you to dissect a string more flexibly than you can with AWK's substr function.
Given a string, patsplit breaks the string into pieces that match a regex and stores the pieces in an array. It returns the number of pieces.
patsplit(string,array,regex)
Simple uses. Here the string to be split is "a4b33c19d":
(1) Print the number of pieces that are 1 or more digits long:
awk '{n=patsplit($0,z,/[0-9]+/); print n}' <<< "a4b33c19d"
awk '{patsplit($0,z,/[0-9]+/); print length(z)}' <<< "a4b33c19d"

(2) Print just the second piece:
awk '{patsplit($0,z,/[0-9]+/); print z[2]}' <<< "a4b33c19d"
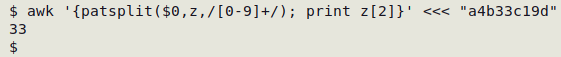
(3) Print the first and last piece:
awk '{n=patsplit($0,z,/[0-9]+/); print z[1],z[n]}' <<< "a4b33c19d"

(4) In the CSV "x37ffi,a4b33c19d,brr9lm7", print the first and last piece in the second field:
awk -F"," '{n=patsplit($2,z,/[0-9]+/); print z[1],z[n]}'
<<< "x37ffi,a4b33c19d,brr9lm7"

Separators. The patsplit function can store the separator following the target regex, in a separate array:
patsplit(string,array-with-targets,regex,array-with-separators)
(5) Print the targets and their following separators in serial order:
awk '{n=patsplit($0,z,/[0-9]+/,x); \
for (i=0;i<=n;i++) print i,z[i],x[i]}' OFS="|" <<< "a4b33c19d"
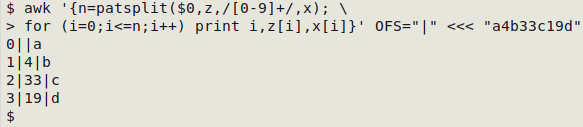
The first target is "4" and the following separator is "b". The "zeroth" separator is "a" but there is no "zeroth" target.
(6) Print the pieces that aren't digits, and their following separators, in serial order:
awk '{n=patsplit($0,z,/[^0-9]+/,x); \
for (i in z) print i,z[i],x[i]}' OFS="|" <<< "a4b33c19d"

The first target is "a" and its following separator is "4". There is neither a "zeroth" separator nor a "zeroth" target.
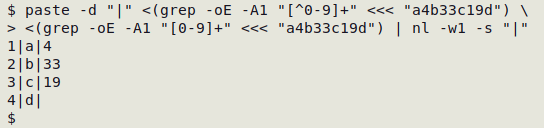
Alternatives. In the shell, there are always alternative ways to process text. For example, I can duplicate that last patsplit command's output (6) with paste, grep and nl:
I can also do string splitting with AWK's split function. Like patsplit, split stores targets and separators in two arrays:
split(string,array-with-targets,regex for separator,array-with-separators)
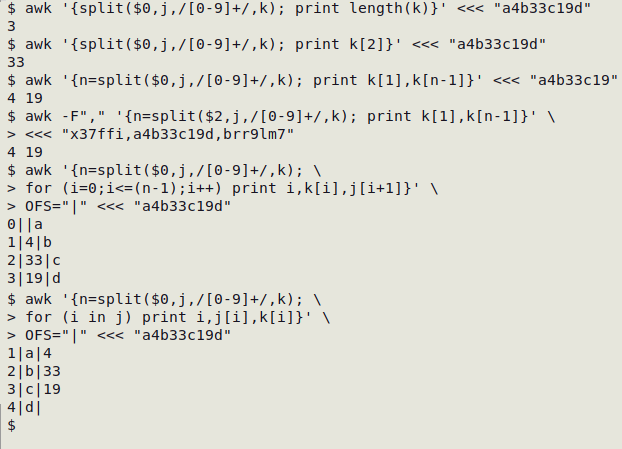
And here are the split versions of examples 1-6:
awk '{split($0,j,/[0-9]+/,k); print length(k)}' <<< "a4b33c19d"
awk '{split($0,j,/[0-9]+/,k); print k[2]}' <<< "a4b33c19d"
awk '{n=split($0,j,/[0-9]+/,k); print k[1],k[n-1]}' <<< "a4b33c19"
awk -F"," '{n=split($2,j,/[0-9]+/,k); print k[1],k[n-1]}' \
<<< "x37ffi,a4b33c19d,brr9lm7"
awk '{n=split($0,j,/[0-9]+/,k); \
for (i=0;i<=(n-1);i++) print i,k[i],j[i+1]}' \
OFS="|" <<< "a4b33c19d"
awk '{n=split($0,j,/[0-9]+/,k); \
for (i in j) print i,j[i],k[i]}' \
OFS="|" <<< "a4b33c19d"
I haven't yet seen a string-splitting task that couldn't be done with a split tweak, although there are probably splits that are more easily done with patsplit. However, I still think it's good that GNU AWK has both splitters in its toolbox, because I suspect I'll someday need to do an ugly split for which patsplit is the perfect tool.
Last update: 2022-02-02
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License