
For a full list of BASHing data blog posts see the index page. ![]()
Gremlin detection bigly improved and a NUL problem avoided
"Gremlin" is my name for an invisible character other than a plain whitespace, a linefeed or a horizontal tab. Gremlins can cause errors in data processing and can also make it harder to detect duplicate records in a data table.
A few years ago I wrote a gremlin-detector script (called "gremlins") for A Data Cleaner's Cookbook that works on UTF-8-encoded plain text files. The script has since had a few minor updates, but I've now rewritten "gremlins" from scratch to make it faster and more informative. This post explains the new script, which is presented in full at the bottom of this webpage.
Overview of the script. The purpose of the script is to find and tally both the number of gremlins of each kind, and the number of lines (records) in which they occur. For practical purposes I've split the gremlins into the ones I often find in data tables, and all the rest. The four common gremlins are carriage returns, non-breaking spaces, soft hyphens and zero-width spaces; this is the "base" set. The "other" gremlins are the 61 remaining C0 and C1 control characters excepting NUL.
Script details. The script begins by creating temp files for the "base" and "other" gremlins, "/tmp/basegrem" and "/tmp/othergrem". Each line in these files gives the Unicode code point for the gremlin (uNNNN format) followed after a pipe separator by the common name for the gremlin, its usual abbreviation and its Unicode and hexadecimal representations.
In the next two commands, grep searches the file-to-be-checked for the "base" and "other" gremlins, saving the lines where these occur in the temp files "base" and "other".
The next command is a while loop that reads the four Unicode code points for the "base" gremlins one by one, these having been clipped out of "/tmp/basegrem" using cut -f1 -d"|":
while read line; do awk -v STR="$line" -v CHAR="$(printf "\\$line")" 'FNR==NR {a[$1]=$2; next} $0 ~ CHAR {cnt++; n+=gsub(CHAR,"")} END {print a[STR]": "(n==0 ? "\x1b[1;34mnone\x1b[0m" : "\x1b[1;34m"n" in "cnt" records\x1b[0m")}' FS="|" /tmp/basegrem base; done <<<"$(cut -f1 -d"|" /tmp/basegrem)"
Each of the code points in turn is passed to an AWK command which stores the code point in the AWK variable "STR". AWK also generates the gremlin character with printf "\\$line" and stores the character in the AWK variable "CHAR".
AWK then builds an array "a" from "/tmp/basegrem" with the Unicode code points as index strings and the corresponding gremlin info as value strings. With the array built, AWK turns to the "base" temp file with the lines that grep found to have "base" gremlins. If the line contains the while loop's currently selected character ($0 ~ CHAR), AWK carries out two actions. The first is to start a counter that records the number of lines in "base" containing that character (cnt++).
The second action is to increment a variable "n" that counts the number of times the gremlin appears in the line. This number is the output from AWK's gsub function, here used to delete the gremlin and return the number of deletions (n+=gsub(CHAR,"")).
Having processed all the lines in "base" for that particular gremlin, in an END statement AWK prints the result of a ternary operator. If "n" is zero (none of that particular gremlin were found in "base"), AWK prints the gremlin info from the array "a", and "none", with the "none" styled bold and blue by ASCII color escapes. If "n" is greater than zero, AWK prints the gremlin info, the number of gremlin characters and the number of lines in which they were found, again using bold and blue styling (print a[STR]": "(n==0 ? "\x1b[1;34mnone\x1b[0m" : "\x1b[1;34m"n" in "cnt" records\x1b[0m")).
With the "base" gremlins dealt with, the script does a special check for NUL characters as described in the next section of this post. If any NULs are found, the result is printed in a new temp file, "/tmp/others".
Next, for the "other" gremlins the script repeats the while loop command it used for the "base" gremlins, with a difference. Instead of printing a "none" result if no gremlins are found, AWK prints nothing. The END statement only checks to see if "n" is greater than zero (if (n>0) print a[STR]": \x1b[1;34m"n" in "cnt" records\x1b[0m"}). If true, the gremlin info, gremlin tally and line tally are appended to "/tmp/others" and the while loop moves on to the next of the 61 control characters.
The script now checks to see if "/tmp/others" is empty or not. If it contains lines, the file is catted to screen. If "/tmp/others" is empty, the script printfs "No NULLs or gremlin control characters found". Temp files are then deleted and the script exits.
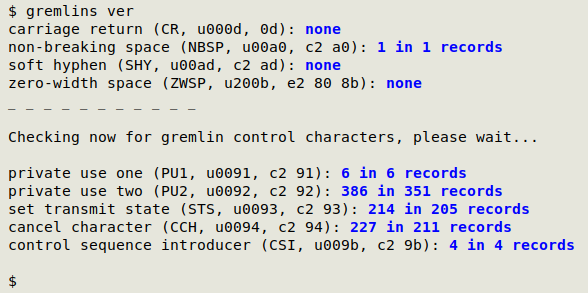
The screenshot below shows "gremlins" working on the data table "ver":
The NUL byte problem. The NUL character (the 00000000 byte) doesn't play nicely with some shell tools, like grep:
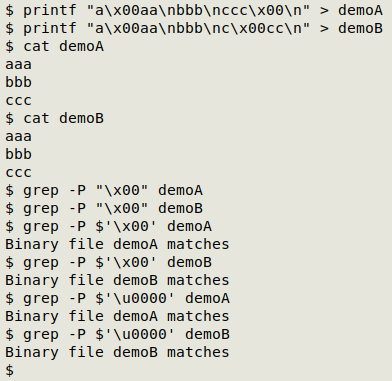
And although AWK detects NULs, it can't use the null byte as in the other commands in the script, because BASH objects:

The script treats NUL as a special case and does a direct search for the character on the whole file-to-be-checked:
awk '/\x00/ {cnt++; n+=gsub(/\x00/,"")} END {if (n>0) print "null (NUL, u0000, x00):\x1b[1;34m "n" in "cnt" records\x1b[0m"}' "$1" > /tmp/others

Here I've "salted" the "ver" table with a couple of NULs in one of the records:
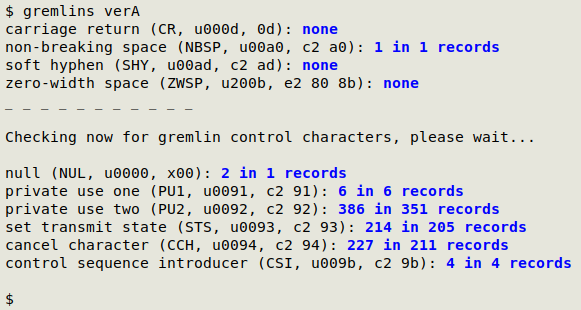
Script. "gremlins" below. It processed "verA" (216707 records, 223.1MB) in 1.5 seconds on my desktop (6 core Intel Core i5-9500T, 8GB RAM).
#!/bin/bash
echo "u000d|carriage return (CR, u000d, 0d)
u00a0|non-breaking space (NBSP, u00a0, c2 a0)
u00ad|soft hyphen (SHY, u00ad, c2 ad)
u200b|zero-width space (ZWSP, u200b, e2 80 8b)" > /tmp/basegrem
echo "u0001|start of heading (SOH, u0001, 01)
u0002|start of text (STX, u0002, 02)
u0003|end of text (ETX, u0003, 03)
u0004|end of transmission (EOT, u0004, 04)
u0005|enquiry (ENQ, u0005, 05)
u0006|acknowledge (ACK, u0006, 06)
u0007|bell (BEL, u0007, 07)
u0008|backspace (BS, u0008, 08)
u000b|vertical tab (VT, u000b, 0b)
u000c|form feed (FF, u000c, 0c)
u000e|shift out (SO, u000e, 0e)
u000f|shift in (SI, u000f, 0f)
u0010|data link escape (DLE, u0010, 10)
u0011|device control 1 (DC1, u0011, 11)
u0012|device control 2 (DC2, u0012, 12)
u0013|device control 3 (DC3, u0013, 13)
u0014|device control 4IDC4 (u0014, 14, )
u0015|negative acknowledge (NAK, u0015, 15)
u0016|synchronous idle (SYN, u0016, 16)
u0017|end of transmission block (ETB, u0017, 17)
u0018|cancel (CAN, u0018, 18)
u0019|end of medium (EM, u0019, 19)
u001a|substitute (SUB, u001a, 1a)
u001b|escape (ESC, u001b, 1b)
u001c|file separator (FS, u001c, 1c)
u001d|group separator (GS, u001d, 1d)
u001e|record separator (RS, u001e, 1e)
u001f|unit separator (US, u001f, 1f)
u007f|delete (DEL, u007f, 7f)
u0080|padding character (PAD, u0080, c2 80)
u0081|high octet preset (HOP, u0081, c2 81)
u0082|break permitted here (BPH, u0082, c2 82)
u0083|no break here (NBH, u0083, c2 83)
u0084|index (IND, u0084, c2 84)
u0085|next line (NEL, u0085, c2 85)
u0086|start of selected area (SSA, u0086, c2 86)
u0087|end of selected area (ESA, u0087, c2 87)
u0088|horizontal tab (HTS, u0088, c2 88)
u0089|horizontal tab with justification (HTJ, u0089, c2 89)
u008a|line tabulation set (VTS, u008a, c2 8a)
u008b|partial line down (PLD, u008b, c2 8b)
u008c|partial line up (PLC, u008c, c2 8c)
u008d|reverse index (RI, u008d, c2 8d)
u008e|single shift two (SS2, u008e, c2 8e)
u008f|single shift three (SS3, u008f, c2 8f)
u0090|device control string (DCS, u0090, c2 90)
u0091|private use one (PU1, u0091, c2 91)
u0092|private use two (PU2, u0092, c2 92)
u0093|set transmit state (STS, u0093, c2 93)
u0094|cancel character (CCH, u0094, c2 94)
u0095|message waiting (MW, u0095, c2 95)
u0096|start of protected area (SPA, u0096, c2 96)
u0097|end of protected area (EPA, u0097, c2 97)
u0098|start of string (SOS, u0098, c2 98)
u0099|single graphic character introducer (SGCI, u0099, c2 99)
u009a|single character introducer (SCI, u009a, c2 9a)
u009b|control sequence introducer (CSI, u009b, c2 9b)
u009c|string terminator (ST, u009c, c2 9c)
u009d|operating system command (OSC, u009d, c2 9d)
u009e|privacy message (PM, u009e, c2 9e)
u009f|application program command (APC, u009f, c2 9f)" > /tmp/othergrem
grep -P '\x{000d}|\x{00a0}|\x{00ad}|\x{200b}' "$1" > base
grep -P "[\x01-\x08\x0b\x0c\x0e-\x19\x1a-\x1f\x7f\x80-\x9f]" "$1" > other
while read line; do awk -v STR="$line" -v CHAR="$(printf "\\$line")" 'FNR==NR {a[$1]=$2; next} $0 ~ CHAR {cnt++; n+=gsub(CHAR,"")} END {print a[STR]": "(n==0 ? "\x1b[1;34mnone\x1b[0m" : "\x1b[1;34m"n" in "cnt" records\x1b[0m")}' FS="|" /tmp/basegrem base; done <<<"$(cut -f1 -d"|" /tmp/basegrem)"
printf "_ _ _ _ _ _ _ _ _ _ _ \n"
printf "\nChecking now for gremlin control characters, please wait..."
echo
awk '/\x00/ {cnt++; n+=gsub(/\x00/,"")} END {if (n>0) print "null (NUL, u0000, x00):\x1b[1;34m "n" in "cnt" records\x1b[0m"}' "$1" > /tmp/others
while read line; do awk -v STR="$line" -v CHAR="$(printf "\\$line")" 'FNR==NR {a[$1]=$2; next} $0 ~ CHAR {cnt++; n+=gsub(CHAR,"")} END {if (n>0) print a[STR]": \x1b[1;34m"n" in "cnt" records\x1b[0m"}' FS="|" /tmp/othergrem other; done <<<"$(cut -f1 -d"|" /tmp/othergrem)" >> /tmp/others
echo
if [ -s /tmp/others ]; then
cat /tmp/others
else
printf "No NULs or gremlin control characters found\n\n"
fi
echo
rm /tmp/basegrem /tmp/othergrem /tmp/others base other
exit 0
If you're not familiar with AWK you may be wondering why AWK's search for lines with NUL is done with just /\x00/ as a pattern, but the search for a character represented by an AWK variable is done with $0 ~ CHAR, especially since /\x00/ is AWK shorthand for $0 ~ /\x00/.
See the screenshot below. The condition "foo" just means that the variable "foo" exists. Since that's true for every line, AWK prints all the lines. If the condition is that the current line matches "foo", only one line is printed. If the variable is put between "regex slashes" (/foo/), AWK interprets "foo" as a string to be matched or searched for, and the string "foo" doesn't exist in the 3 lines being processed.

Last update: 2021-12-08
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License