
For a full list of BASHing data blog posts see the index page. ![]()
Yet another gremlin: the zero-width space
The gremlin detector script in A Data Cleaner's Cookbook now looks for zero width spaces (U+200B, hex e2 80 8b, ​).
Like a soft hyphen (SHY), a zero-width space (ZWSP) is usually non-printing and invisible, and indicates for a Web browser or word-processing program where a string of visible characters can be broken when wrapping a line. With SHY, the program will add a hyphen at the end of the wrapped line, while a ZWSP just means "You can break the string here when wrapping".
Also like a SHY (and a no-break space (NBSP)), a ZWSP can cause problems where it isn't needed. A quick googling for "problem with zero width space" turned up ZWSP-caused issues with
- coding a URL with an unexpected ZWSP (2021)
- rendering in Obsidian knowledge-graphing software (2020)
- compiling a Kotlin program (2020)
- starting a Kubernetes deployment (2020)
- working with javascript and JSON (2011-2020)
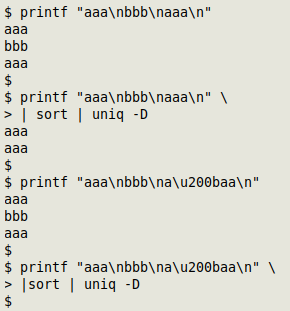
A ZWSP is a nuisance in data auditing because it's a formatting character that can hide duplicates in data content. In the second case below, there's a ZWSP in one of the "aaa" strings. The two "aaa" lines are no longer recognised as duplicates by uniq:
For locating scattered, invisible characters like ZWSPs in the data files I audit (they're all TSVs, UTF-8 encoded), I've started using the "heremark" function below, which accepts a Unicode character as "uxxxx" in its second argument. "heremark" is similar to the gremfinder script but replaces the character with the marker "{HERE}".
heremark() { char=$(printf "\\$2"); awk -F"\t" -v find="$char" '$0 ~ find {for (i=1;i<=NF;i++) if ($i ~ find) {gsub(find,"\33[31;1m{HERE}\33[0m",$i); print "line "NR", field "i":\n"$i}}' "$1"; }
The second argument is stored in the variable "char" together with a backslash as prefix (char=$(printf "\\$2")).
The shell variable "char" is assigned the AWK variable "find" (-v find="$char"), and note that in this function, AWK is told that the field separator is a tab (-F"\t").
AWK looks for and selects in the first argument ("$1") just those lines containing the looked-for character ($0 ~ find), and loops through the fields in that line one by one (for (i=1;i<=NF;i++))
If any of the fields in that line contains the character (if ($i ~ find) ), AWK replaces all instances of the character in that field with "{HERE}" in bold and red (gsub(find,"\33[31;1m{HERE}\33[0m",$i)). AWK then prints the line number and the field number, followed (next line) by the field with its replaced characters (print "line "NR", field "i":\n"$i).
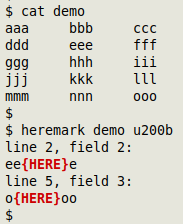
The file "demo" has a ZWSP buried in the "eee" and "ooo" strings:
An easy way to delete all ZWSPs in a file is with sed:
sed 's/\xe2\x80\x8b//g' file > file_without_ZWSPs
sed $'s/\u200b//' file > file_without_ZWSPs
The second command is explained in this BASHing data post.
There's also a webpage devoted specifically to removing ZWSPs from pasted-in strings! It's based on a (java)script with the instruction input.replace(/\u200B/g, "").
| No-break space | NBSP | u00a0 |
| Soft hyphen | SHY | u00ad |
| Zero-width space | ZWSP | u200b |
Last update: 2021-09-01
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License