
For a full list of BASHing data blog posts see the index page. ![]()
CSV to table, table to CSV
The title of this post may sound a little strange. A data CSV is already a table, isn't it? With fields separated by commas?
True, but the data ops demonstrated below aren't so simple. The first one comes from a 2019 Stack Exchange question. Given this CSV (I'll call the file "datacsv")...
ATGC,CD3,56
ATGC,CD4,67
ATGC,IgD,126
ATGC,IgM,127
AGTC,CD3,67
AGTC,CD4,78
AGTC,IgD,102
AGTC,IgM,89
TCGA,CD3,334
TCGA,CD4,123
TCGA,IgD,456
TCGA,IgM,80
CGTA,CD3,54
CGTA,CD4,32
CGTA,IgD,82
CGTA,IgM,117
...how could you build a table with the first field as column headers, the second field as row headers and the third field as values? The highest-voted answer used an AWK script with three for loops, but the job can be done a lot easier with GNU datamash:
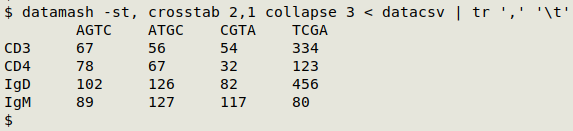
datamash -st, crosstab 2,1 collapse 3 < datacsv | tr ',' '\t'
The two datamash general options used here are s for sorting, and t, for a comma as input field delimiter. The crosstab operation builds a pivot table using unique field 2 entries for row headers and unique field 1 entries for column headers. The values in field 3 are left unchanged by the collapse operation.
The datamash output is comma-separated and I've used tr to change those commas into tabs. It's possible to get the same result with another datamash option, --output-delimiter=$'\t', but that's more typing!
The reverse operation is to "decompose" a 2x2 table into its component triplets, namely row value, column value, table value, and comma-separate the values. To demonstrate I'll use a made-up example, "datatable", which is tab-separated:
| Team | 2017 | 2018 | 2019 | 2020 |
| Firedolls | 16 | 9 | ||
| Wonder Women | 14 | 19 | 11 | 15 |
| Panthers | 22 | 20 | 19 | |
| Queen Bees | 12 | 10 | 17 | |
| Fembots | 18 | 22 | 29 | 20 |
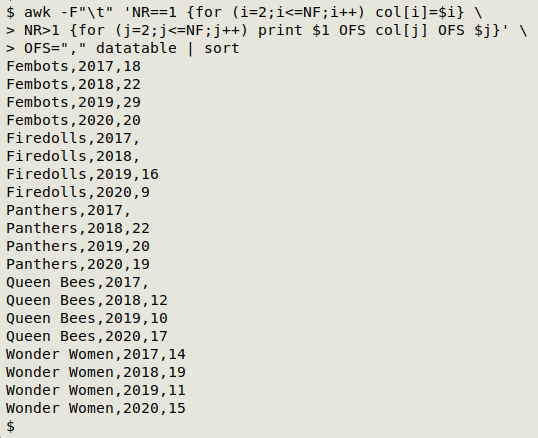
awk -F"\t" 'NR==1 {for (i=2;i<=NF;i++) col[i]=$i} \
> NR>1 {for (j=2;j<=NF;j++) print $1 OFS col[j] OFS $j}' \
> OFS="," datatable | sort
The input field separator is first set to a tab (-F"\t"). AWK then works through the header row (NR==1) with a for loop. Beginning with the second field (i=2), AWK builds an array "col" with the field number as the index string and the field entry as the value string. In this way the value of col[2] is "2017", the value of col[3] is "2018", and so on.
Next, AWK works through the remaining lines (NR>1) one by one with another for loop beginning with the second field. For each such entry it prints: the entry in the first field ($1), which is the row header, then an output field separator (OFS; not defined yet), then the "col" value corresponding to that field number (col[j]), then an output field separator, and finally the entry itself ($j). AWK also prints a newline, which is the default for the print operation.
I've defined the output field separator as a "pseudo-argument" after the AWK command (OFS=",") followed by the main argument, "datatable". The AWK output is then passed to sort.
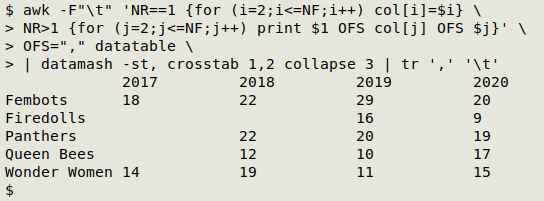
And just for fun I'll pass the "decomposed" table as a CSV to datamash for reconstructing as a table. This time I'll let datamash do the sorting:
Last update: 2021-06-02
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License