
For a full list of BASHing data blog posts see the index page. ![]()
What's wrong with these records?
When my wife added a tab-delimited text table as a layer in her QGIS GIS program recently, nine of her points got rejected:

This was odd because the XY values in those records (UTM eastings and northings) were no different in format from all the other XY pairs in the table, and were well within the numerical range of the others as well. So why the nine rejections?
After considerable checking I found that those nine records — and none of the other 4906 records in the table — contained double quotes. The quotes were in a text field, not in an X or Y field; an example is the data item Corylus avellana "Atheldens lebner". When my wife changed the double quotes to single quotes, the nine records were accepted by QGIS and plotted.
Another solution to this particular problem would have been to delete the " that QGIS has as a default in its table import dialog, in both the Quote and Escape boxes.
The incident led me to think about how I usually diagnose data problems, which is by the Boringly Analytical, Painfully Step-by-Step Method™. Did all the records in the table have the same number of fields? (Yes, assuming tabs were the only field separators.) Were all the X-Y values OK? (Yes.) Were there any gremlin control characters lurking in the table? (No.) A question I could have asked (but didn't) was Do the rejected records have something in common that none of the other records have? Like maybe some character?
Some command-line tinkering with that question is described below.
ALERT! "Tinkering" here means fooling around on a keyboard. It does not mean optimising code, or finding the best or simplest way to do a text-processing job. You've been warned.
Split the file. A good first step would be to split the table into (1) the nine records and (2) all the others. To do this I first copied and pasted into the file "errors" the full, relevant lines in the QGIS message log:
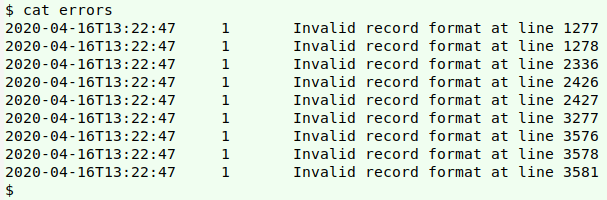
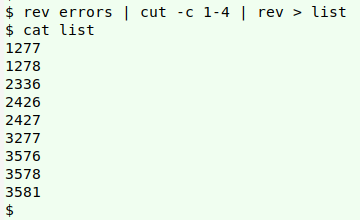
I extracted the line numbers at the ends of the "errors" lines (which were conveniently each 4 digits long) with a combination of rev and cut -c, , storing the result in the temp file "list":
rev errors | cut -c 1-4 | rev > list
I then used AWK to split my wife's table "LT2019-10-23.txt" into "the_nine" (the nine rejected records) and "the_others" (all the other records, excluding the header):
awk 'FNR==NR {a[$0]; next} FNR>1 {if (FNR in a) print >> "the_nine"; else print >> "the_others"}' list LT2019-10-23.txt
The file "list" is put into the array "a" as index strings, after which AWK moves to "LT2019-10-23.txt" and the second action. That action is to test if the current line number (FNR) in "LT2019-10-23.txt" is an index string in the array. If it is, the line is added to the file "the_nine". If not, the line is added to "the_others".
Characters in the rejects, but not the others. My plan for checking individual characters looked like this:
Loop through the "core" UTF-8 characters.
For each character, count lines with the character in the "rejects" file
and the "others" file.
If all the "rejects" lines have the character but none of the "others" do,
then print the character.
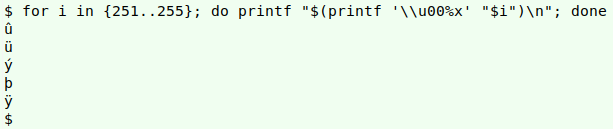
Looping through the 255 "core" UTF-8 characters (excluding the null byte) can be done by re-formatting the decimal numbers 1 through 255 as Unicode representations of those values. For shell purposes, those 255 representations can have the form "\u00XX", where "XX" is the hexadecimal equivalent of the decimal number. A command to do that is shown below for the restricted range 251-255; the printf formatting option "%x" converts decimal numbers to hexadecimal:

To print a character, just pass its Unicode representation to printf:
To count lines with a character I would normally do a grep -c search for that character in the file. There's a catch, though: grep doesn't understand Unicode representations, even when enabled for Perl-compatible regex (PCRE). I know of two workarounds. One is to quote the string "\u00XX" within $'..', the other is to search for the printed-out character. The two methods are shown below in a search for the letter "y" (\u0079) in the first line of "the_nine" file:
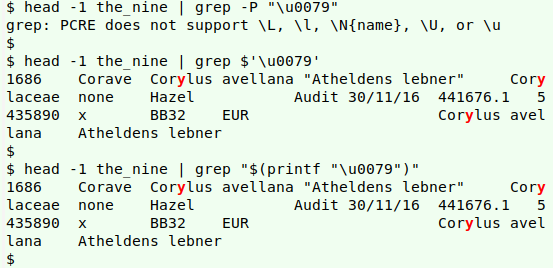
The second workaround suits my plan, because I can put the decimal-to-hexadecimal-to-Unicode printing in a variable ("char"), to save typing. A final tweak is to use the grep option "-F", which means the searched-for pattern is a string, not a regular expression. Below is my command with its result marked by a red arrow.

for i in {1..255}; do char=$(printf '\\u00%x' "$i"); if [[ "$(grep -cF "$(printf "$char")" the_nine)" = "9" && "$(grep -cF "$(printf "$char")" the_others)" = "0" ]]; then printf "$char\n"; fi; done
Without the -F option for grep, the command returns the correct character but also the error messages
grep: Invalid regular expression
grep: Trailing backslash
The two problems are caused by grep's regex engine looking for "[" (decimal value 91) and "\" (decimal value 92), respectively, as shown below:

-F turns off the regex engine and forces grep to look for the literal characters "[" and "\".
Summing up. It's possible to do a diagnostic check on the command line comparing "bad" records with "good" ones, but it's impossible to design a general diagnosis, because the definition of "bad" depends on how the records are processed. So how did I actually find the double quote problem in my wife's data, before I did the command-line tinkering? I'm not sure, so I'll call it "data worker's intuition"!
Last update: 2020-08-26
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License