
For a full list of BASHing data blog posts see the index page. ![]()
A grizzle about captive data
A co-worker gave me some data for checking. The client had sent it in a RAR file. Inside the RAR was a Microsoft Access database. Inside the Access database was a single Access table, and inside the Access table was the data.
I don't know why the client did that matryoshka-style data packing, but I know that many people don't understand that software is not data. In this case, the raw data was just plain text — letters and numbers, punctuation, spaces, tabs and newlines:
I extracted the table with mdbtools and saved it as a TSV by passing it through csvformat:
$ mdb-tables nokidding.accdb
seriously
$ mdb-export nokidding.accdb seriously | csvformat -T > data_tsv
The file "data_tsv" was plain text and UTF-8 encoded, with 40 fields and ca 70,000 rows and a file size of 30.1 MB, compared to the Access file's 61.8 MB. The proprietary RAR-format archive I received was 2.5 MB, about the same size as "data_tsv.zip" in the public-domain ZIP format (2.4 MB).
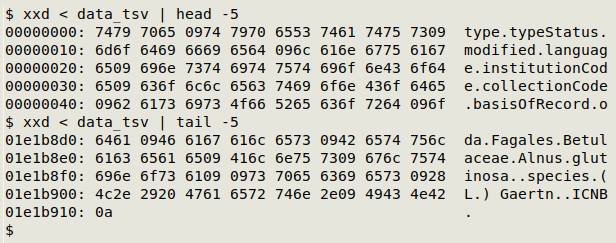
But the data was imprisoned in Microsoft Access, which is mostly secret gobbledygook:
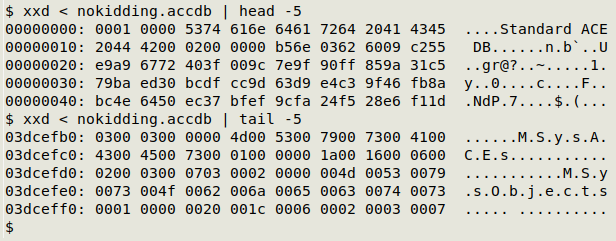
Microsoft encourages people to confuse software with data. Late in 2018, an article in the Harvard Business Review began as follows:
The past 10 years have seen a wave of innovative big data software designed to analyze, manipulate, and visualize data. Yet for the regular knowledge worker, Microsoft Excel, 30 years on, remains the go-to product for people looking to make sense of data. Satya Nadella, Microsoft’s CEO, maintains that Excel is still the one Microsoft product that stands above the rest — and 750 million knowledge workers worldwide support that claim every day.
Just repeating, this was an article, not an advertisement. It was written by Microsoft associates.
Powerful data-working environments like Python, R and the shell all use raw data files. The file is still raw when you've finished your data work, unless you've done an in-place edit, and the raw data file remains available for use by another application. Excel, on the other hand, doesn't work with raw data. It only operates on data captive within Excel.
Unfortunately, otherwise clever researchers are as easily persuaded by propaganda as anyone else, so it's probably not surprising that tables of research data are often made publicly available as Excel files. Everyone uses Excel, right? And "publicly available" means "open data", right?
Well, no, not everyone uses Excel, and there's more to "open" than that. Shared data should be machine-readable and formatted for maximum re-usability. In practice that means UTF-8 encoding and plain-text formatting. The Dryad data repository is quite clear in its advice:
To maximize accessibility, reusability and preservability, share data in non-proprietary open formats when possible (see preferred formats). This ensures your data will be accessible by most people. [Link in original]
The preferred text formats:
README files should be in plain text format (ASCII, UTF-8)
Comma-separated values (CSV) for tabular data
Semi-structured plain text formats for non-tabular data (e.g., protein sequences)
Structured plain text (XML, JSON)
But even Dryad hedges:
Dryad welcomes the submission of data in multiple formats to enable various reuse scenarios. For instance, Dryad's preferred format for tabular data is CSV, however, an Excel spreadsheet may optimize reuse in some cases. Thus, Dryad accepts more than just the preservation-friendly formats listed below.
An Australian data repository is a bit clearer about format:
AVOID
- proprietary formats
- file format and software obsolescence
You may have to use software that does not save data in a durable format, due to discipline-specific or other requirements e.g. specialised programs to capture or generate data. Export your data to a more durable format such as plain text if you can do so without losing data integrity and include it alongside the original files when you archive them. This is often possible. An example is exporting .csv files from SPSS (with value labels) and archiving them alongside the .sav files.
Back in America there's Harvard University, which like many USA universities is closely partnered with Microsoft. Harvard runs a data repository called "Dataverse", and the advice on supported file formats says Dataverse accepts tables in SPSS, STATA, R and Excel formats, but that CSV files have "limited support".
Really? Excel is OK in Dataverse but CSV isn't? Wow.
Grizzling finished. If you work in a Windows environment and want to share tabular data, please free that dataset from its application prison by exporting it as plain text, UTF-8 encoded, with plain line endings (LF, not CRLF). And TSV is better than CSV.
Scott Nesbitt's Plain Text Project website has lots of useful resources for plain text users.
Last update: 2020-07-22
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License