
For a full list of BASHing data blog posts see the index page. ![]()
Add an issues field to a data table
Some of the data tables I audit have an "Issues" field that flags problems with individual records. It's a kind of self-reporting "Look! I've got an error!" feature.
I wondered if I could do something similar with my favourite data-processing language, AWK, and this post documents my tinkerings. Although the 10-record sample table I've used for demonstration purposes could be checked by eye, many of the tables I work with have tens of thousands of records and more than 100 fields. The commands shown here are a little fiddly but work well, regardless of table size.
Data table. In the tab-separated table (TSV) "countries", Area is in km2 and PopDens is in persons/km2.
| Country | Pop | PopYr | Area | PopDens |
| Afghanistan | 38,928,346 | 2020 | 652,860 | 60 |
| El Salvador | 6,486,205 | 2020 | 20,720 | 313 |
| Slovenia | 2,078,938 | 2200 | 20,140 | 93 |
| USA | 331,002,651 | 2020 | 9,147,420 | 36 |
| Yemen | 29,825,964 | 2020 | 527,970 | 56 |
| Chile | 19,116,201 | 2020 | 743,532 | 26 |
| United States | 331,002,651 | 2020 | 9,147,420 | 36 |
| San Marino | 33,931 | 2020 | 566 | |
| Nigeria | 200,963,599 | 2019 | 910,770 | 221 |
| Canada | 37,742,154 | 2020 | 9,093,510 | 4 |
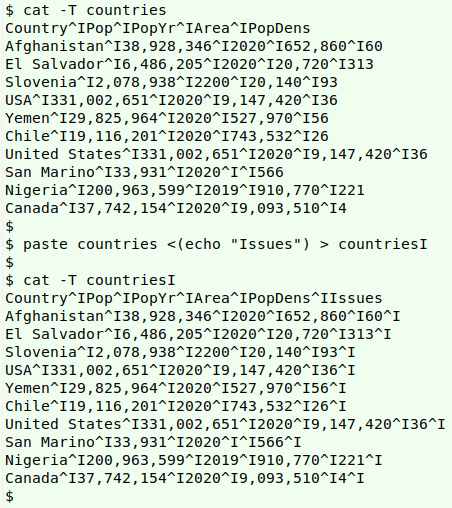
Issues table. I'll back up the original table and create a working one ("countriesI") at the same time by paste-ing the field name "Issues" as the header of a blank sixth field. Adding a header+blank field this way with paste can be done anywhere in a table, as explained in an earlier BASHing data post. The screenshot below shows that after the header, all the records in "countriesI" end in a blank field delimited by a tab (catted as "^I").
paste countries <(echo "Issues") > countriesI
Get field names. In several of the tests below I'll be adding something like "Problem with field 5" to Issues. It would be a lot more friendly to report "Problem with PopDens". To do that I'll store the first five field names in the array "fld", so I can call them up later in the command. The field numbers are the array's index strings and the field names are the array's value strings. In the next screenshot the array-building is the main action, and in an END statement I print out the index strings and their corresponding value strings:
awk -F"\t" '{for (i=1;i<=(NF-1);i++) \
{if (NR==1) fld[i]=$i}} \
END {for (i in fld) print i, fld[i]}' countriesI

Test for missing data items. The "countries" table shouldn't have any blanks. The following command checks for missing data items field by field in "countriesI" and reports blanks in Issues. The Issues field is redefined in this command if there's a blank found, so AWK needs to be given an output field separator as well as an input one (-F"\t" -v OFS="\t").
The test for blanks is actually a test for absence of an alphanumeric character ($i !~ /[[:alnum:]]/, and it works on each of the 5 fields defined in the loop for (i=1;i<=(NF-1);i++). The final "1" ensures that every line is printed; it's short for "if 1 {print}" and the condition "1" is always true.
Because other tests will be done on the same table (see below), I use GNU AWK's -i inplace feature to edit "countriesI" in place. The semicolon after the Issues entry is there to separate the latest note from any others found in later tests on the same record. For the same reason, field 6 is redefined as the old field 6 concatenated with the new note.
awk -F"\t" -v OFS="\t" -i inplace \
'{for (i=1;i<=(NF-1);i++) \
{if (NR==1) fld[i]=$i; \
if (NR>1 && $i !~ /[[:alnum:]]/) \
$6=$6"Missing "fld[i]";"}} 1' countriesI
Right-hand side of edited "countriesI":

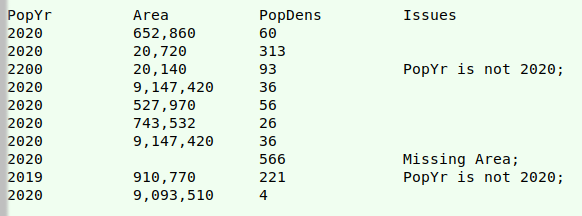
Test for incorrect date. The population figures in the table should all date from 2020, so the next test simply looks at field 3 to confirm that "2020" is the entry. If not, there's a note in Issues.
awk -F"\t" -v OFS="\t" -i inplace \
'{for (i=1;i<=(NF-1);i++) {if (NR==1) fld[i]=$i} \
{if (NR>1 && $3 != "2020") \
$6=$6fld[3]" is not 2020;"}} 1' countriesI
Right-hand side of edited "countriesI":
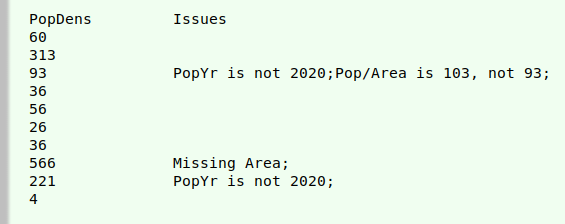
Test for incorrect calculation. Does the table have the correct population density, which should be Pop divided by Area, rounded to the nearest whole number? (Spoiler: it's wrong for Slovenia.)
A test that divides field 2 by field 4 will be meaningless if either field is empty (and will give a fatal error "attempt to divide by zero" if field 4 doesn't contain a non-zero number), so a condition for the test is that neither field is blank ($2 != "" && $4 != "").
Another quirk of the data is that the figures contain comma separators. These have to be removed temporarily, in this case with gensub. The comma-less figure from field 2 is sprintfed as variable "m", and from field 4 as "n".
The quotient "m/n" is formatted as a whole number with sprintf "%.f" and the result stored in the variable "x" for convenience. If field 5 is not equal to the calculated quotient (if ($5 != x)), the Issues field gets a note with both the correct and the incorrect values for the quotient.
awk -F"\t" -v OFS="\t" -i inplace \
'{for (i=1;i<=NF;i++) {if (NR==1) {fld[i]=$i}} \
{if (NR>1 && $2 != "" && $4 != "") \
{m=sprintf("%d",gensub(",","","g",$2)); \
n=sprintf("%d",gensub(",","","g",$4)); \
x=sprintf("%.f",m/n); \
if ($5 != x) $6=$6fld[2]"/"fld[4]" is "x", not "$5";"}}} 1' countriesI
Right-hand side of edited "countriesI":
Test for duplicate records. This command is a bit elaborate but delivers a neat result. The assumption here is that field 1 contains a unique identifier for the record, which is true in this case, so field 1 can be ignored when looking for duplicates.
AWK processes the file "countriesI" twice. In the first pass (FNR==NR) it creates an array "dup" whose index strings are a concatenation of fields 2 through 5. The "++" after the array statement means that AWK keeps a count of the number of times each unique concatenation of fields appears in the file.
In the second pass (next) AWK first sets the variable "n" to the count found by "dup" for that particular concatenation of fields. If the count is greater than 1 (indicating duplicates), then AWK starts a counter "c" at that record. It then rebuilds field 6 with the the number (from "c") out of "n" for which that record is a duplicate, followed by the contents of the first three of the duplicated fields. If there's more than one set of duplicated records in the table, those quoted fields will identify which duplicate ("1 of 2", "2 of 2") goes with which.
awk -F"\t" -v OFS="\t" -i inplace \
'FNR==NR {dup[$2,$3,$4,$5]++; next} \
{n=dup[$2,$3,$4,$5]; \
{if (n>1) \
{++c; $6=$6"Duplicate "c" of "n" with "$2" | "$3" | "$4" etc;"}}} 1' \
countriesI countriesI
Right-hand side of edited "countriesI":

Summing up. Yes, I can do tests with AWK and add "issues" notes to a data table, but putting code like the above into a script would only be worthwhile if the table to be checked was in a standardised form and I could apply a standardised group of tests. Alas, that's not the case with my auditing work, where every table is different and the problems I look for depend on the nature of the data supplied!
Last update: 2020-05-20
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License