
For a full list of BASHing data blog posts see the index page. ![]()
Dealing with an all-CAPS/first-CAP jumble
I sometimes need to tally lists of single words in which the same word might appear capitalised or all in capital letters. Here's an example, a 20-line list of plant family names, including some blanks:
BRASSICACEAE
Caryophyllaceae
Asteraceae
Apocynaceae
APIACEAE
Caesalpiniaceae
APIACEAE
Brassicaceae
Apiaceae
CAMPANULACEAE
Caryophyllaceae
Boraginaceae
BIGNONIACEAE
APIACEAE
CARYOPHYLLACEAE
The tally I'd like from this list has the names with the all-caps strings changed to first-cap ones:
5 #These are the blank items in the list
4 Apiaceae
1 Apocynaceae
1 Asteraceae
1 Bignoniaceae
1 Boraginaceae
2 Brassicaceae
1 Caesalpiniaceae
1 Campanulaceae
3 Caryophyllaceae
A neat way to build the tally with GNU sed is shown below; the list above is here called "families":
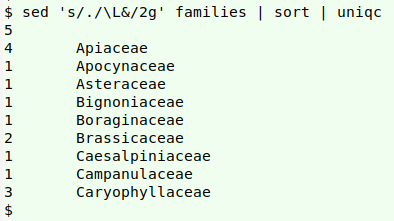
sed 's/./\L&/2g' families | sort | uniqc
#"uniqc" is an alias; see below
The command sed 's/./\L&/' converts the first character (.) in a line to its lowercase version (\L&). With the "g" option in sed 's/./\L&/g', every character in each line is converted. With the GNU sed option "2g" (sed 's/./\L&/2g'), conversions begin with the second character and continue to the end of the line. That changes "APIACEAE" to "Apiaceae".
"uniqc" is an alias I use a lot:
alias uniqc="uniq -c | sed 's/^[ ]*//;s/ /\t/'".
The output of uniq -c is re-formatted by this command so that the count is left-justified and separated from the counted item by a tab. An alternative alias using AWK that does the same thing is
alias uniqc="uniq -c | awk 'BEGIN {FS=" ";OFS="\t"} {$1=$1} 1'"
Here's an AWK alternative to the GNU sed method:
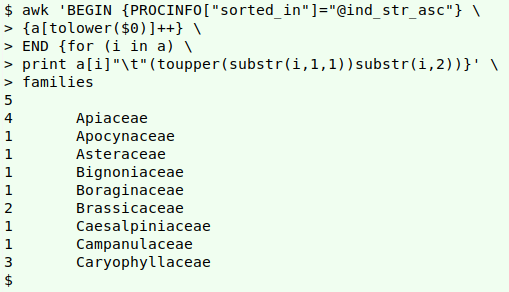
awk 'BEGIN {PROCINFO["sorted_in"]="@ind_str_asc"} {a[tolower($0)]++} END {for (i in a) print a[i]"\t"(toupper(substr(i,1,1))substr(i,2))}' families
Ignoring the BEGIN statement for a moment, the main part of the command (a[tolower($0)]++) creates an array "a" with the lowercase version of the whole line as an index string, and counts the number of times that array item occurs in the file.
In the END statement, AWK walks through the array index string by index string (for (i in a)) and prints the count of that array item (a[i]), followed by a tab ("\t"), followed by two substrings of the index string concatenated together: first the uppercase version of the first character (toupper(substr(i,1,1)), then the rest of the string (substr(i,2)).
The printing is done with the array items sorted by their index string, thanks to the instruction in the BEGIN statement PROCINFO["sorted_in"]="@ind_str_asc".
For more on array-sorting methods in AWK, see this earlier BASHing data post.
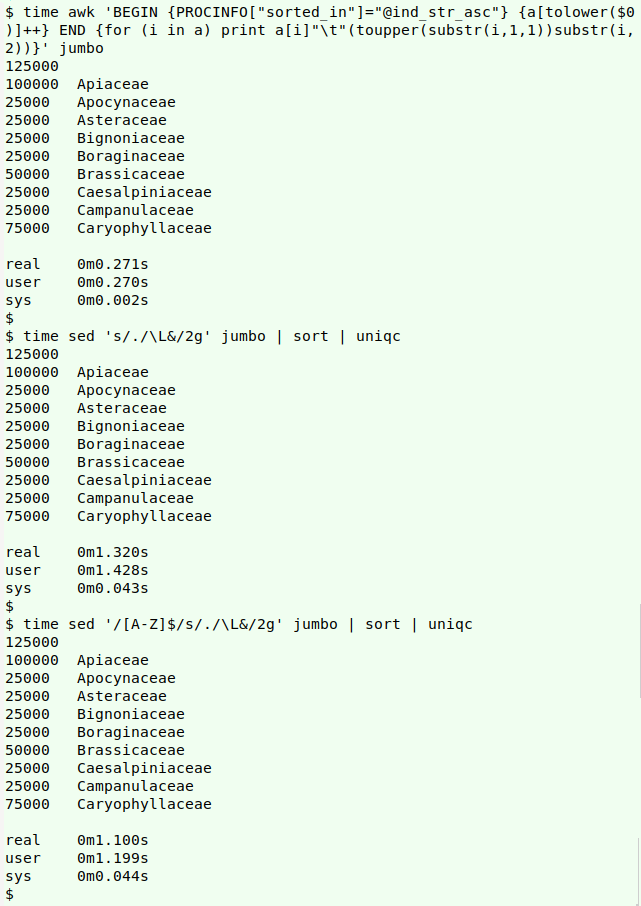
Although the AWK command is more complicated than the sed one, it's actually a lot faster, even if I restrict the case-changing by sed to lines ending in a capital letter:
sed '/[A-Z]$/s/./\L&/2g' families | sort | uniqc
To test processing times, I'll first multiply the 20-line "families" file 25,000 times, then shuffle the resulting 500,000-line file:
for i in {1..25000}; do cat families >> bigger; done; shuf bigger > jumbo
AWK completes the job on "jumbo" in one-fifth to one-quarter the time required by sed, sort and uniq:
Last update: 2020-04-29
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License