
For a full list of BASHing data blog posts see the index page. ![]()
Checking date components across fields
The checking operation explained below is similar to one described here in A Data Cleaner's Cookbook. I used it when auditing a CSV data table with ca 18500 records and 17 fields, including a date field in dd-mmm-yy format and "decomposed date" fields for day, month and year. Were there any disagreements between date fields? [Spoiler: yes].
To show how I checked the table, I'll do each of three operations separately, then combine them in the single command I used. Here's a simplified demonstration table called "demo":
Date,Day,Month,Year
23-Sep-05,23,9,2005 #All OK
NA,NA,NA,1977 #Quite a few of these were in the data table
03-Jul-82,3,6,1982 #Month disagreement
26-Apr-93,26,4,1993 #All OK
09-Jun-03,8,6,2003 #Day disagreement
13-Aug-67,12,8,1977 #Day and year disagreement
26-Jul-04,26,7,2004 #All OK
Year. Are the last 2 characters in Date (if it doesn't contain "NA") different from the last 2 characters in Year?
awk -F"," $1 != "NA" {if (substr($1,8) != substr($4,3)) print}' demo
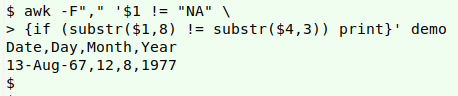
AWK's substr function usually takes 3 arguments: string to be subdivided, starting character for subdivision, and number of characters to be returned beginning with the starting character. If you leave out the third argument, as I did here, AWK returns all characters from the starting one to the end of the string.
I don't have to exclude the table header from the operation, because I'd like it in the output, and the last 2 characters in "Date" aren't the same as the last 2 characters in "Year".
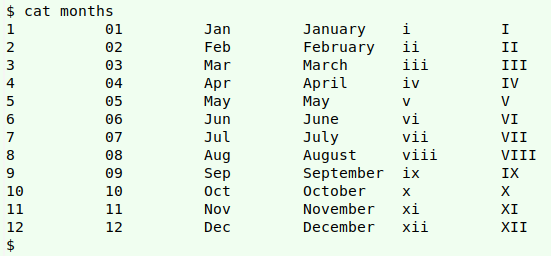
Month. For details on using a "months" table to convert between month formats, see this BASHing data post. My "months" table looks like this:
The checking command for month disagreements first splits the Date string, then looks to see if the month part of the string, converted to a number, is different from the number in the Month field:
awk 'FNR==NR {a[$3]=$1; next} $1 != "NA" {split($1,b,"-"); if (a[b[2]] != $3) print}' FS="\t" months FS="," demo
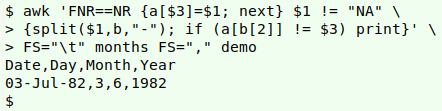
The array "a" built from "months" takes the 3-letter field in field 3 (Jan, Feb etc) as its index string and the corresponding number (1, 2 etc) from field 1 as its value string.
The split command creates an array "b" from the date string. The first array element, "b[1]", is the day component, "b[2]" is the month component and "b[3] is the year component. In the "if" test on the one erroneous record, "a[b[2]]" is "a[Jul]", which has the value string "7".
Notice the use of the FS variable as a "pseudo-argument", as discussed in a previous BASHing data post. The "months" table is tab-separated, and "demo" is comma-separated.
Day. Here I check to see if the day component "b[1]" from the split-up Date string is different from the number in the Day field, but first I need to format "b[1]" to lose any leading zero (e.g. in "03-Jul-82"):
awk -F"," '$1 != "NA" {split($1,b,"-"); if (sprintf("%d",b[1]) != $2) print}' demo
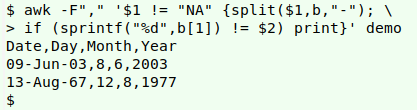
Formatting "b[1]" is done with sprintf rather than printf so that the formatted string can be used as a variable in the "if" test, not just printed out.
Putting them all together...
...is just a matter of combining the tests with "||" (logical OR) between them:
awk 'FNR==NR {a[$3]=$1; next} $1 != "NA" {split($1,b,"-"); if (substr($1,8) != substr($4,3) || a[b[2]] != $3 || sprintf("%d",b[1]) != $2) print}' FS="\t" months FS="," demo

In the real world. The table I was auditing, here called "data_table", had 17 fields. Date was field 6, Day was field 7, Month was field 8 and Year was field 9. The table was (luckily) a simple CSV, with no embedded commas in any field. However, I didn't want to print out the whole of a record with disagreements, just the four fields with date components plus the first two fields in the data table, ID1 and ID2, which together made each record unique. To do this printing I had to specify an output field separator for re-building records, and I decided to use tabs (-v OFS="\t"). The real-world command was:
awk -v OFS="\t" \
'FNR==NR {a[$3]=$1; next} \
$6 != "NA" {split($6,b,"-"); \
if (substr($6,8) != substr($9,3) \
|| a[b[2]] != $8 \
|| sprintf("%d",b[1]) != $7) \
print $1,$2,$6,$7,$8,$9}' \
FS="\t" months FS="," data_table
The result was 47 defective records out of 18488, not a bad error rate but avoidable if the Day, Month and Year fields had been built directly from Date, or the other way around.
Last update: 2020-04-15
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License