
For a full list of BASHing data blog posts, see the index page. ![]()
Leading and trailing whitespace
Googling the phrase "trailing whitespace" is like googling "coffee stains": you mainly get "how to remove" recipes.
There are procedures for deleting trailing whitespace in C, Python, Vim, PHP, Java, Visual Studio, R, C++, JavaScript, etc etc. Nobody wants trailing whitespace in their code, and in a Coding Horror blog post ten years ago, Jeff Atwood called it — a bit melodramatically — "The Silent Killer".
In my data auditing, though, trailing (and leading) whitespace is no big deal within data items in data tables. The worst it does is needlessly "pseudo-duplicate" a data item, making cleaning advisable. Here's a real-world example from a tally I did in May:
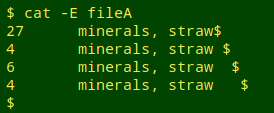
Just to be clear, by "whitespace" I mean the ASCII blank space: hex 20, Unicode U+0020, the character you get when pressing the spacebar on a keyboard:
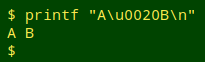
Other kinds of whitespace, like non-breaking spaces, I detect and treat as gremlin characters.
Finding and visualising leading/trailing whitespace within data items. For demonstration purposes I'll use the comma-separated table "fileB". It has whitespace leading and trailing as well as inside its data items:
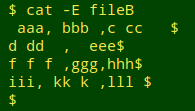
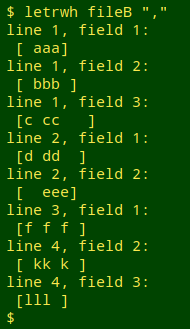
My finder/visualiser has the following AWK command at its core:
awk '{for (i=1;i<=NF;i++) \
{if ($i ~ /^[ ]+/ || $i ~ /[ ]+$/) \
print "line "NR", field "i":\n ["$i"]"}}'
The for loop works through each field in the line and tests it. If the field matches either the pattern "starts with one or more spaces" (^[ ]+) or the pattern "ends with one or more spaces" ([ ]+$), then AWK prints the line number and field number, and on the next line an indented copy of the field. The copy is enclosed in square brackets. This "visualises" any leading or trailing spaces as blanks after (leading) or before (trailing) a bracket.
To make the command more easily usable I've saved it in a function, "letrwh", in which the table's field separator, whatever it is, is given to the function as the second argument:
letrwh() { awk -v FS="$2" '{for (i=1;i<=NF;i++) \
{if ($i ~ /^[ ]+/ || $i ~ /[ ]+$/) \
print "line "NR", field "i":\n ["$i"]"}}' "$1"; }
Removing leading/trailing whitespace. When I'm auditing data, the finder/visualiser is handy for identifying scattered instances of leading/trailing whitespace, which can then be individually reported or edited away. If I want to get rid of all the leading/trailing whitespace within fields in a data table, I need a command that acts like the "TRIM" function in individual cells in a spreadsheet. This is not the same as deleting leading/trailing whitespace from whole lines, and again a field-by-field solution is safest:
awk '{for (i=1;i<=NF;i++) gsub(/^[ ]+|[ ]+$/,"",$i); print}'
I've saved that basic command in the function "delfldspa" with the field separator again as second argument:
delfldspa() { awk -v sep="$2" 'BEGIN{FS=OFS=sep} \
{for (i=1;i<=NF;i++) \
gsub(/^[ ]+|[ ]+$/,"",$i); print}' "$1" > "clean_$1"; }
In each field in a line, AWK substitutes an empty string ("") for one or more leading spaces (^[ ]+), or (|) for one or more trailing spaces ([ ]+$). When all fields in the line have been processed, AWK prints the line with the fields re-built where substitution happened.
The substitution is done with AWK's gsub string function, which takes 3 comma-separated arguments: the regex pattern to be matched, the replacement string, and the target, which in this case is a field. From the GNU AWK manual, on gsub: Search target for all of the longest, leftmost, nonoverlapping matching substrings it can find and replace them with replacement. The ‘g’ in gsub() stands for "global," which means replace everywhere.
The fields are defined by the field separator given in the second argument, which is converted to an AWK variable (I call it "sep") for use in the command (-v sep="$2"). The BEGIN statement specifies that both the input file ("$1") and the output file ("clean_$1") will have the same field separator.
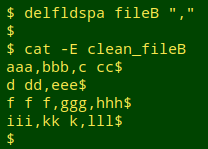
Here's the function at work on "fileB":
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License