
For a full list of BASHing data blog posts, see the index page. ![]()
How to delete, insert and replace whole lines
The trick to successful operations with whole lines in data tables is the correct use of line addresses. You need to be sure not only that the operation is done where you want it, but also that it isn't done where you don't want it. sed and AWK are the right tools, because with both you can easily specify the line address or addresses for the operation.
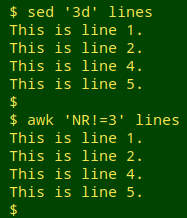
Single lines. From the table "lines" (below), I'll delete line 3:
This is line 1.
This is line 2.
This is line 3.
This is line 4.
This is line 5.
sed '3d' lines
awk 'NR!=3' lines
Inserting and replacing are similar operations, because both involve adding a new line to the table. I'll insert "This is a new line." after line 4...
sed '4a\This is a new line.' lines
awk -v x="This is a new line." 'NR==4 {$0=$0 RS x} 1' lines
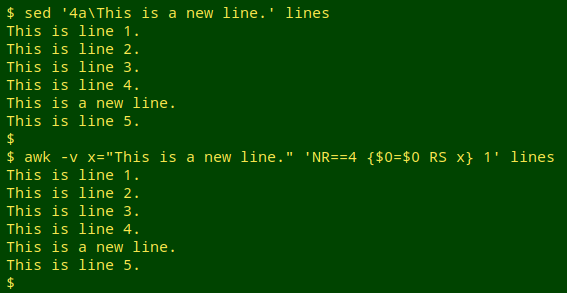
The "append" instruction (a) for sed adds a line just after the line address.
In the AWK command, line 4 is redefined to be line 4, a newline (the default record separator, or RS) and the line to be added.
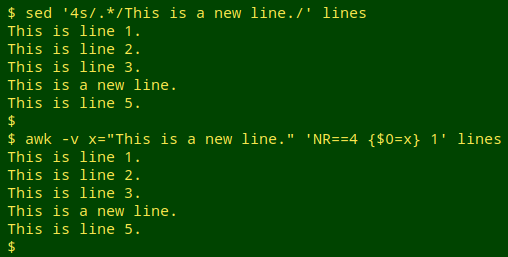
...and replace line 4 with the new line:
sed '4s/.*/This is a new line./' lines
awk -v x="This is a new line." 'NR==4 {$0=x} 1' lines
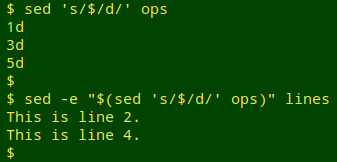
Multiple lines. Suppose I want to delete lines 1, 3 and 5 from "lines". (Three lines isn't a lot, but this method works for any number of lines.) First I'll create a file called "ops" with a list of those line numbers:
1
3
5
With sed, I generate a virtual file of instructions from "ops", and use sed's "-e" option to make that a list of jobs to do on "lines":
sed -e "$(sed 's/$/d/' ops)" lines
Something similar works for inserting and replacing. I'll insert "This is a new line." after lines 1, 3 and 5, or replace those lines with the new one:
sed -e "$(sed 's/$/a\This is a new line./' ops)" lines
sed -e "$(sed 's/$/s\/.*\/This is a new line.\//' ops)" lines
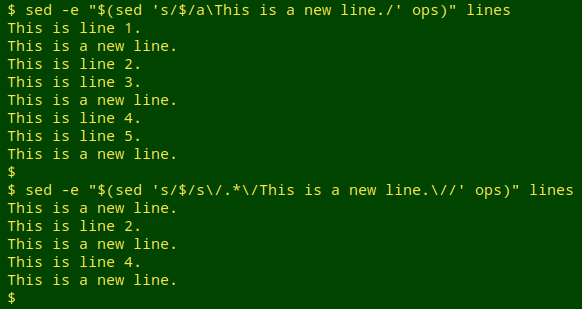
Since I'm using a forward slash as a delimiter in the sed commands, I need to escape the forward slashes in the "statement" s/.*/This is a new line./.
An easy AWK method is to first put the contents of "ops" into an array, then do a deletion, insertion or replacement based on whether or not the current line number is in the array:
awk 'FNR==NR {a[$0]; next} !(FNR in a)' ops lines
awk -v x="This is a new line." \
'FNR==NR {a[$0]; next} FNR in a {$0=$0 RS x} 1' ops lines
awk -v x="This is a new line." \
'FNR==NR {a[$0]; next} FNR in a {$0=x} 1' ops lines
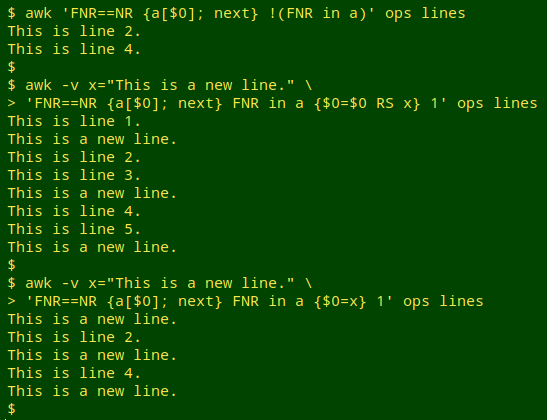
FNR is the record number (records are lines by default) of the current file and NR is the total number of records. These will only be the same for the first file processed, so the action in curly brackets (a[$0]; next) only applies to the first file, namely "ops". That action is to build an array "a" indexed with the whole lines in the file, i.e. the listed line numbers. When that's done, next tells AWK to move on to the next file, "lines".
If the current line number in "lines" (FNR) is not indexed in "a" (!(FNR in a)), it's printed.
If the current line number in "lines" (FNR) is indexed in "a" (FNR in a), AWK does the commanded action, either inserting or replacing. The final "1" is AWK shorthand for "print all lines".
Deleting, inserting or replacing based on a pattern match. This is where operations on whole lines can go wrong, because line addresses aren't used. For example, suppose I want to delete any lines containing the string "tomorrow" in "file". I can use sed or AWK:
sed '/tomorrow/d' file
awk '$0 !~ /tomorrow/' file
But what if there were lines in "file" that I didn't want to delete and that I didn't realise contained "tomorrow"? To avoid disaster, I always check with a general grep search to make sure that the only lines to be targeted are the ones containing the pattern to be matched.
grep "tomorrow" file
If some of those lines need to be left alone, I get the line numbers of the ones to be deleted and do the deletion with just those line addresses. It's safer.
Last update: 2019-05-12
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License